 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUITester: Enabling GUI Agents for Exploratory Defect Discovery
Jan 08, 2026Exploratory GUI testing is essential for software quality but suffers from high manual costs. While Multi-modal Large Language Model (MLLM) agents excel in navigation, they fail to autonomously discover defects due to two core challenges: \textit{Goal-Oriented Masking}, where agents prioritize task completion over reporting anomalies, and \textit{Execution-Bias Attribution}, where system defects are misidentified as agent errors. To address these, we first introduce \textbf{GUITestBench}, the first interactive benchmark for this task, featuring 143 tasks across 26 defects. We then propose \textbf{GUITester}, a multi-agent framework that decouples navigation from verification via two modules: (i) a \textit{Planning-Execution Module (PEM)} that proactively probes for defects via embedded testing intents, and (ii) a \textit{Hierarchical Reflection Module (HRM)} that resolves attribution ambiguity through interaction history analysis. GUITester achieves an F1-score of 48.90\% (Pass@3) on GUITestBench, outperforming state-of-the-art baselines (33.35\%). Our work demonstrates the feasibility of autonomous exploratory testing and provides a robust foundation for future GUI quality assurance~\footnote{Our code is now available in~\href{https://github.com/ADaM-BJTU/GUITestBench}{https://github.com/ADaM-BJTU/GUITestBench}}.
Decentralized Gaussian Process Classification and an Application in Subsea Robotics
Nov 19, 2025Teams of cooperating autonomous underwater vehicles (AUVs) rely on acoustic communication for coordination, yet this communication medium is constrained by limited range, multi-path effects, and low bandwidth. One way to address the uncertainty associated with acoustic communication is to learn the communication environment in real-time. We address the challenge of a team of robots building a map of the probability of communication success from one location to another in real-time. This is a decentralized classification problem -- communication events are either successful or unsuccessful -- where AUVs share a subset of their communication measurements to build the map. The main contribution of this work is a rigorously derived data sharing policy that selects measurements to be shared among AUVs. We experimentally validate our proposed sharing policy using real acoustic communication data collected from teams of Virginia Tech 690 AUVs, demonstrating its effectiveness in underwater environments.
FAME: Adaptive Functional Attention with Expert Routing for Function-on-Function Regression
Oct 01, 2025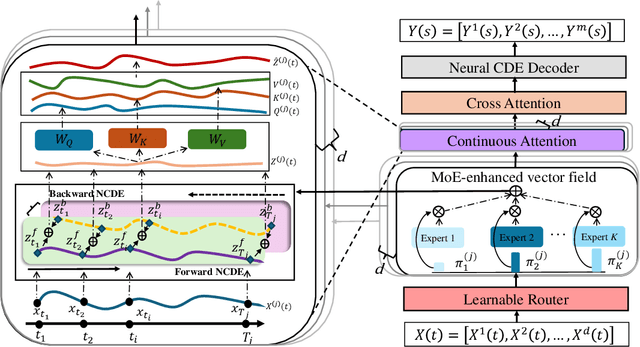
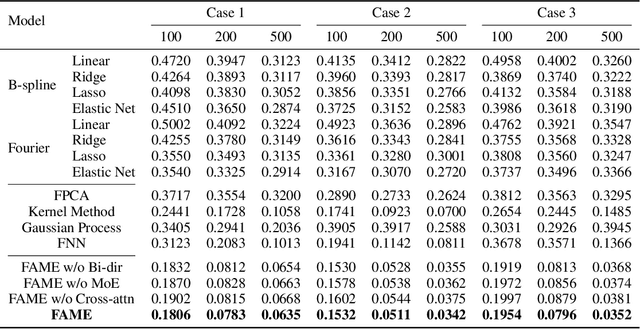
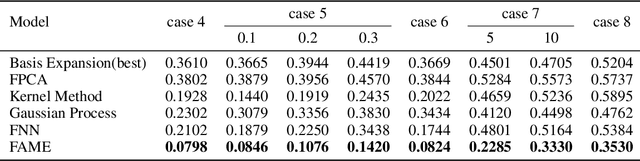
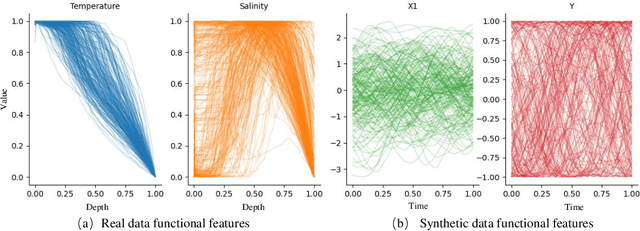
Functional data play a pivotal role across science and engineering, yet their infinite-dimensional nature makes representation learning challenging. Conventional statistical models depend on pre-chosen basis expansions or kernels, limiting the flexibility of data-driven discovery, while many deep-learning pipelines treat functions as fixed-grid vectors, ignoring inherent continuity. In this paper, we introduce Functional Attention with a Mixture-of-Experts (FAME), an end-to-end, fully data-driven framework for function-on-function regression. FAME forms continuous attention by coupling a bidirectional neural controlled differential equation with MoE-driven vector fields to capture intra-functional continuity, and further fuses change to inter-functional dependencies via multi-head cross attention. Extensive experiments on synthetic and real-world functional-regression benchmarks show that FAME achieves state-of-the-art accuracy, strong robustness to arbitrarily sampled discrete observations of functions.
PR2: Peephole Raw Pointer Rewriting with LLMs for Translating C to Safer Rust
May 07, 2025There has been a growing interest in translating C code to Rust due to Rust's robust memory and thread safety guarantees. Tools such as C2RUST enable syntax-guided transpilation from C to semantically equivalent Rust code. However, the resulting Rust programs often rely heavily on unsafe constructs--particularly raw pointers--which undermines Rust's safety guarantees. This paper aims to improve the memory safety of Rust programs generated by C2RUST by eliminating raw pointers. Specifically, we propose a peephole raw pointer rewriting technique that lifts raw pointers in individual functions to appropriate Rust data structures. Technically, PR2 employs decision-tree-based prompting to guide the pointer lifting process. Additionally, it leverages code change analysis to guide the repair of errors introduced during rewriting, effectively addressing errors encountered during compilation and test case execution. We implement PR2 as a prototype and evaluate it using gpt-4o-mini on 28 real-world C projects. The results show that PR2 successfully eliminates 13.22% of local raw pointers across these projects, significantly enhancing the safety of the translated Rust code. On average, PR2 completes the transformation of a project in 5.44 hours, at an average cost of $1.46.
CICADA: Cross-Domain Interpretable Coding for Anomaly Detection and Adaptation in Multivariate Time Series
May 01, 2025Unsupervised Time series anomaly detection plays a crucial role in applications across industries. However, existing methods face significant challenges due to data distributional shifts across different domains, which are exacerbated by the non-stationarity of time series over time. Existing models fail to generalize under multiple heterogeneous source domains and emerging unseen new target domains. To fill the research gap, we introduce CICADA (Cross-domain Interpretable Coding for Anomaly Detection and Adaptation), with four key innovations: (1) a mixture of experts (MOE) framework that captures domain-agnostic anomaly features with high flexibility and interpretability; (2) a novel selective meta-learning mechanism to prevent negative transfer between dissimilar domains, (3) an adaptive expansion algorithm for emerging heterogeneous domain expansion, and (4) a hierarchical attention structure that quantifies expert contributions during fusion to enhance interpretability further.Extensive experiments on synthetic and real-world industrial datasets demonstrate that CICADA outperforms state-of-the-art methods in both cross-domain detection performance and interpretability.
Evaluating Trust in AI, Human, and Co-produced Feedback Among Undergraduate Students
Apr 15, 2025As generative AI transforms educational feedback practices, understanding students' perceptions of different feedback providers becomes crucial for effective implementation. This study addresses a critical gap by comparing undergraduate students' trust in AI-generated, human-created, and human-AI co-produced feedback, informing how institutions can adapt feedback practices in this new era. Through a within-subject experiment with 91 participants, we investigated factors predicting students' ability to distinguish between feedback types, perception of feedback quality, and potential biases to AI involvement. Findings revealed that students generally preferred AI and co-produced feedback over human feedback in terms of perceived usefulness and objectivity. Only AI feedback suffered a decline in perceived genuineness when feedback sources were revealed, while co-produced feedback maintained its positive perception. Educational AI experience improved students' ability to identify AI feedback and increased their trust in all feedback types, while general AI experience decreased perceived usefulness and credibility. Male students consistently rated all feedback types as less valuable than their female and non-binary counterparts. These insights inform evidence-based guidelines for integrating AI into higher education feedback systems while addressing trust concerns and fostering AI literacy among students.
TokenButler: Token Importance is Predictable
Mar 10, 2025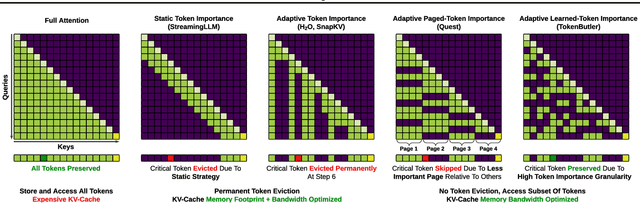
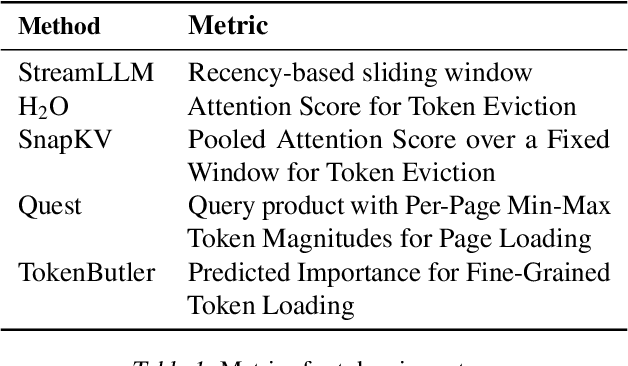
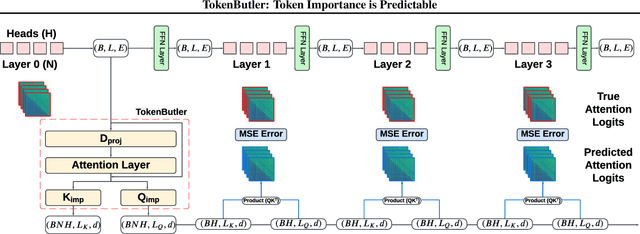
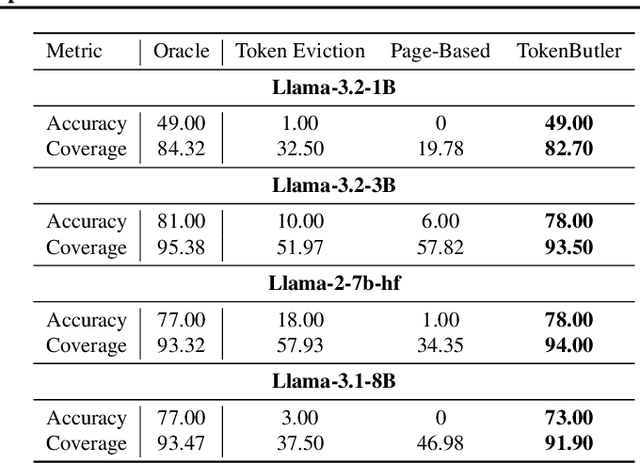
Large Language Models (LLMs) rely on the Key-Value (KV) Cache to store token history, enabling efficient decoding of tokens. As the KV-Cache grows, it becomes a major memory and computation bottleneck, however, there is an opportunity to alleviate this bottleneck, especially because prior research has shown that only a small subset of tokens contribute meaningfully to each decoding step. A key challenge in finding these critical tokens is that they are dynamic, and heavily input query-dependent. Existing methods either risk quality by evicting tokens permanently, or retain the full KV-Cache but rely on retrieving chunks (pages) of tokens at generation, failing at dense, context-rich tasks. Additionally, many existing KV-Cache sparsity methods rely on inaccurate proxies for token importance. To address these limitations, we introduce TokenButler, a high-granularity, query-aware predictor that learns to identify these critical tokens. By training a light-weight predictor with less than 1.2% parameter overhead, TokenButler prioritizes tokens based on their contextual, predicted importance. This improves perplexity & downstream accuracy by over 8% relative to SoTA methods for estimating token importance. We evaluate TokenButler on a novel synthetic small-context co-referential retrieval task, demonstrating near-oracle accuracy. Code, models and benchmarks: https://github.com/abdelfattah-lab/TokenButler
Beyond Existance: Fulfill 3D Reconstructed Scenes with Pseudo Details
Mar 06, 2025The emergence of 3D Gaussian Splatting (3D-GS) has significantly advanced 3D reconstruction by providing high fidelity and fast training speeds across various scenarios. While recent efforts have mainly focused on improving model structures to compress data volume or reduce artifacts during zoom-in and zoom-out operations, they often overlook an underlying issue: training sampling deficiency. In zoomed-in views, Gaussian primitives can appear unregulated and distorted due to their dilation limitations and the insufficient availability of scale-specific training samples. Consequently, incorporating pseudo-details that ensure the completeness and alignment of the scene becomes essential. In this paper, we introduce a new training method that integrates diffusion models and multi-scale training using pseudo-ground-truth data. This approach not only notably mitigates the dilation and zoomed-in artifacts but also enriches reconstructed scenes with precise details out of existing scenarios. Our method achieves state-of-the-art performance across various benchmarks and extends the capabilities of 3D reconstruction beyond training datasets.
VaLiD: Mitigating the Hallucination of Large Vision Language Models by Visual Layer Fusion Contrastive Decoding
Nov 24, 2024Large Vision-Language Models (LVLMs) have demonstrated outstanding performance in multimodal task reasoning. However, they often generate responses that appear plausible yet do not accurately reflect the visual content, a phenomenon known as hallucination. Recent approaches have introduced training-free methods that mitigate hallucinations by adjusting the decoding strategy during inference stage, typically attributing hallucination to the language model itself. Our analysis, however, reveals that distortions in the visual encoding process significantly affect the model's reasoning accuracy. Specifically, earlier visual layers may retain key features but gradually distort as the information propagates toward the output layer. Building on these findings, we propose a novel hallucination-mitigation method from the visual encoding perspective: \textbf{V}isu\textbf{a}l \textbf{L}ayer Fus\textbf{i}on Contrastive \textbf{D}ecoding (VaLiD). This method utilizes uncertainty to guide the selection of visual hidden layers, correcting distortions in the visual encoding process and thereby improving the reliability of generated text. Experimental results show that VaLiD effectively reduces hallucinations across various benchmarks, achieving state-of-the-art performance compared to multiple baseline methods.
Prediction of Acoustic Communication Performance for AUVs using Gaussian Process Classification
Nov 12, 2024
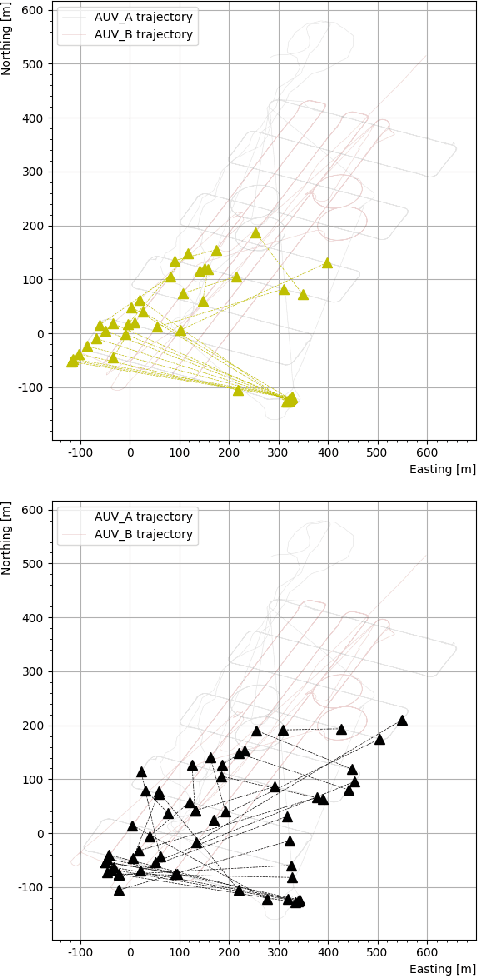
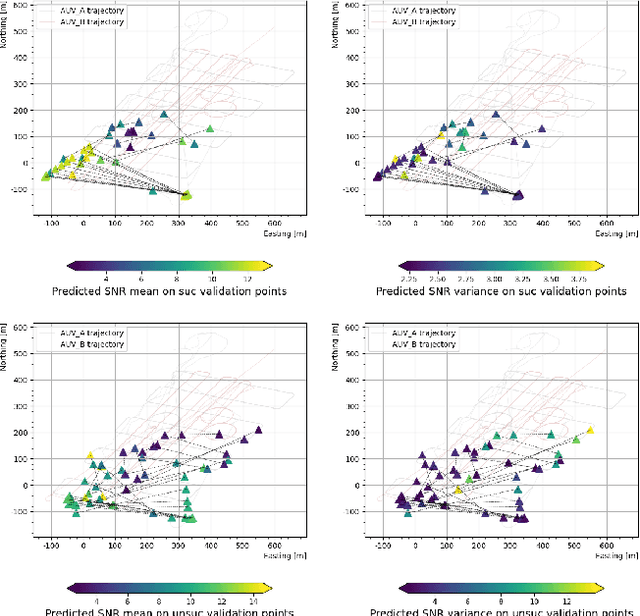
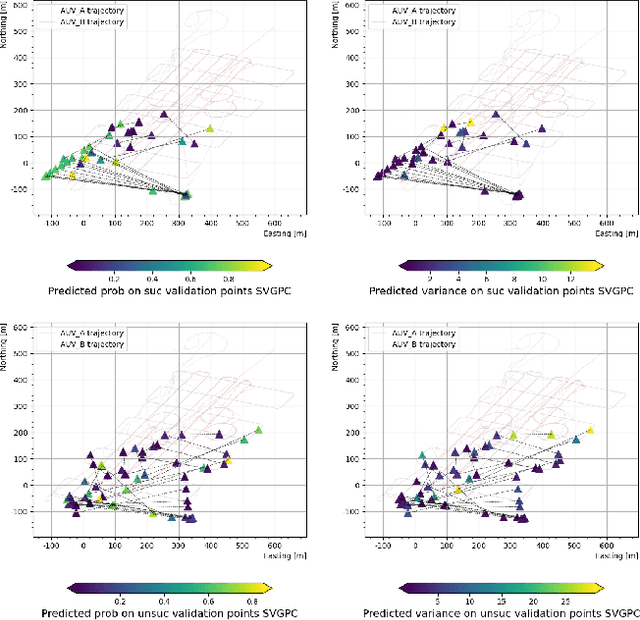
Cooperating autonomous underwater vehicles (AUVs) often rely on acoustic communication to coordinate their actions effectively. However, the reliability of underwater acoustic communication decreases as the communication range between vehicles increases. Consequently, teams of cooperating AUVs typically make conservative assumptions about the maximum range at which they can communicate reliably. To address this limitation, we propose a novel approach that involves learning a map representing the probability of successful communication based on the locations of the transmitting and receiving vehicles. This probabilistic communication map accounts for factors such as the range between vehicles, environmental noise, and multi-path effects at a given location. In pursuit of this goal, we investigate the application of Gaussian process binary classification to generate the desired communication map. We specialize existing results to this specific binary classification problem and explore methods to incorporate uncertainty in vehicle location into the mapping process. Furthermore, we compare the prediction performance of the probability communication map generated using binary classification with that of a signal-to-noise ratio (SNR) communication map generated using Gaussian process regression. Our approach is experimentally validated using communication and navigation data collected during trials with a pair of Virginia Tech 690 AUVs.