 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM-MCTS: Learning from Reasoning Trajectories with Metacognitive Reflection
Apr 07, 2026PRISM-MCTS: Learning from Reasoning Trajectories with Metacognitive Reflection Siyuan Cheng, Bozhong Tian, Yanchao Hao, Zheng Wei Published: 06 Apr 2026, Last Modified: 06 Apr 2026 ACL 2026 Findings Conference, Area Chairs, Reviewers, Publication Chairs, Authors Revisions BibTeX CC BY 4.0 Keywords: Efficient/Low-Resource Methods for NLP, Generation, Question Answering Abstract: The emergence of reasoning models, exemplified by OpenAI o1, signifies a transition from intuitive to deliberative cognition, effectively reorienting the scaling laws from pre-training paradigms toward test-time computation. While Monte Carlo Tree Search (MCTS) has shown promise in this domain, existing approaches typically treat each rollout as an isolated trajectory. This lack of information sharing leads to severe inefficiency and substantial computational redundancy, as the search process fails to leverage insights from prior explorations. To address these limitations, we propose PRISM-MCTS, a novel reasoning framework that draws inspiration from human parallel thinking and reflective processes. PRISM-MCTS integrates a Process Reward Model (PRM) with a dynamic shared memory, capturing both "Heuristics" and "Fallacies". By reinforcing successful strategies and pruning error-prone branches, PRISM-MCTS effectively achieves refinement. Furthermore, we develop a data-efficient training strategy for the PRM, achieving high-fidelity evaluation under a few-shot regime. Empirical evaluations across diverse reasoning benchmarks substantiate the efficacy of PRISM-MCTS. Notably, it halves the trajectory requirements on GPQA while surpassing MCTS-RAG and Search-o1, demonstrating that it scales inference by reasoning judiciously rather than exhaustively.
ASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference Attacks
Jun 12, 2025



Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbf{S}elective data \textbf{O}bfuscation in LLM \textbf{F}ine-\textbf{T}uning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
Jun 12, 2025Large language models (LLMs) have been increasingly applied to automated harmful content detection tasks, assisting moderators in identifying policy violations and improving the overall efficiency and accuracy of content review. However, existing resources for harmful content detection are predominantly focused on English, with Chinese datasets remaining scarce and often limited in scope. We present a comprehensive, professionally annotated benchmark for Chinese content harm detection, which covers six representative categories and is constructed entirely from real-world data. Our annotation process further yields a knowledge rule base that provides explicit expert knowledge to assist LLMs in Chinese harmful content detection. In addition, we propose a knowledge-augmented baseline that integrates both human-annotated knowledge rules and implicit knowledge from large language models, enabling smaller models to achieve performance comparable to state-of-the-art LLMs. Code and data are available at https://github.com/zjunlp/ChineseHarm-bench.
CENSOR: Defense Against Gradient Inversion via Orthogonal Subspace Bayesian Sampling
Jan 27, 2025



Federated learning collaboratively trains a neural network on a global server, where each local client receives the current global model weights and sends back parameter updates (gradients) based on its local private data. The process of sending these model updates may leak client's private data information. Existing gradient inversion attacks can exploit this vulnerability to recover private training instances from a client's gradient vectors. Recently, researchers have proposed advanced gradient inversion techniques that existing defenses struggle to handle effectively. In this work, we present a novel defense tailored for large neural network models. Our defense capitalizes on the high dimensionality of the model parameters to perturb gradients within a subspace orthogonal to the original gradient. By leveraging cold posteriors over orthogonal subspaces, our defense implements a refined gradient update mechanism. This enables the selection of an optimal gradient that not only safeguards against gradient inversion attacks but also maintains model utility. We conduct comprehensive experiments across three different datasets and evaluate our defense against various state-of-the-art attacks and defenses. Code is available at https://censor-gradient.github.io.
DIGIMON: Diagnosis and Mitigation of Sampling Skew for Reinforcement Learning based Meta-Planner in Robot Navigation
Sep 17, 2024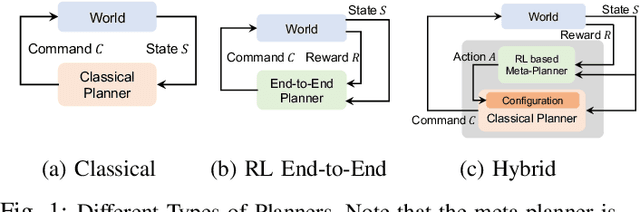



Robot navigation is increasingly crucial across applications like delivery services and warehouse management. The integration of Reinforcement Learning (RL) with classical planning has given rise to meta-planners that combine the adaptability of RL with the explainable decision-making of classical planners. However, the exploration capabilities of RL-based meta-planners during training are often constrained by the capabilities of the underlying classical planners. This constraint can result in limited exploration, thereby leading to sampling skew issues. To address these issues, our paper introduces a novel framework, DIGIMON, which begins with behavior-guided diagnosis for exploration bottlenecks within the meta-planner and follows up with a mitigation strategy that conducts up-sampling from diagnosed bottleneck data. Our evaluation shows 13.5%+ improvement in navigation performance, greater robustness in out-of-distribution environments, and a 4x boost in training efficiency. DIGIMON is designed as a versatile, plug-and-play solution, allowing seamless integration into various RL-based meta-planners.
ROCAS: Root Cause Analysis of Autonomous Driving Accidents via Cyber-Physical Co-mutation
Sep 12, 2024



As Autonomous driving systems (ADS) have transformed our daily life, safety of ADS is of growing significance. While various testing approaches have emerged to enhance the ADS reliability, a crucial gap remains in understanding the accidents causes. Such post-accident analysis is paramount and beneficial for enhancing ADS safety and reliability. Existing cyber-physical system (CPS) root cause analysis techniques are mainly designed for drones and cannot handle the unique challenges introduced by more complex physical environments and deep learning models deployed in ADS. In this paper, we address the gap by offering a formal definition of ADS root cause analysis problem and introducing ROCAS, a novel ADS root cause analysis framework featuring cyber-physical co-mutation. Our technique uniquely leverages both physical and cyber mutation that can precisely identify the accident-trigger entity and pinpoint the misconfiguration of the target ADS responsible for an accident. We further design a differential analysis to identify the responsible module to reduce search space for the misconfiguration. We study 12 categories of ADS accidents and demonstrate the effectiveness and efficiency of ROCAS in narrowing down search space and pinpointing the misconfiguration. We also show detailed case studies on how the identified misconfiguration helps understand rationale behind accidents.
UNIT: Backdoor Mitigation via Automated Neural Distribution Tightening
Jul 16, 2024



Deep neural networks (DNNs) have demonstrated effectiveness in various fields. However, DNNs are vulnerable to backdoor attacks, which inject a unique pattern, called trigger, into the input to cause misclassification to an attack-chosen target label. While existing works have proposed various methods to mitigate backdoor effects in poisoned models, they tend to be less effective against recent advanced attacks. In this paper, we introduce a novel post-training defense technique UNIT that can effectively eliminate backdoor effects for a variety of attacks. In specific, UNIT approximates a unique and tight activation distribution for each neuron in the model. It then proactively dispels substantially large activation values that exceed the approximated boundaries. Our experimental results demonstrate that UNIT outperforms 7 popular defense methods against 14 existing backdoor attacks, including 2 advanced attacks, using only 5\% of clean training data. UNIT is also cost efficient. The code is accessible at https://github.com/Megum1/UNIT.
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Jul 02, 2024

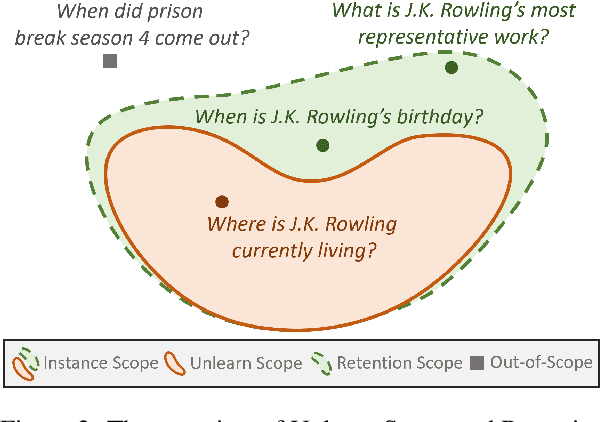

Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.
LOTUS: Evasive and Resilient Backdoor Attacks through Sub-Partitioning
Mar 25, 2024



Backdoor attack poses a significant security threat to Deep Learning applications. Existing attacks are often not evasive to established backdoor detection techniques. This susceptibility primarily stems from the fact that these attacks typically leverage a universal trigger pattern or transformation function, such that the trigger can cause misclassification for any input. In response to this, recent papers have introduced attacks using sample-specific invisible triggers crafted through special transformation functions. While these approaches manage to evade detection to some extent, they reveal vulnerability to existing backdoor mitigation techniques. To address and enhance both evasiveness and resilience, we introduce a novel backdoor attack LOTUS. Specifically, it leverages a secret function to separate samples in the victim class into a set of partitions and applies unique triggers to different partitions. Furthermore, LOTUS incorporates an effective trigger focusing mechanism, ensuring only the trigger corresponding to the partition can induce the backdoor behavior. Extensive experimental results show that LOTUS can achieve high attack success rate across 4 datasets and 7 model structures, and effectively evading 13 backdoor detection and mitigation techniques. The code is available at https://github.com/Megum1/LOTUS.