 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructEdit: Instruction-based Knowledge Editing for Large Language Models
Feb 25, 2024



Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance. However, the current approach encounters issues with limited generalizability across tasks, necessitating one distinct editor for each task, which significantly hinders the broader applications. To address this, we take the first step to analyze the multi-task generalization issue in knowledge editing. Specifically, we develop an instruction-based editing technique, termed InstructEdit, which facilitates the editor's adaptation to various task performances simultaneously using simple instructions. With only one unified editor for each LLM, we empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in multi-task editing setting. Furthermore, experiments involving holdout unseen task illustrate that InstructEdit consistently surpass previous strong baselines. To further investigate the underlying mechanisms of instruction-based knowledge editing, we analyze the principal components of the editing gradient directions, which unveils that instructions can help control optimization direction with stronger OOD generalization. Code and datasets will be available in https://github.com/zjunlp/EasyEdit.
Pretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction
Aug 20, 2022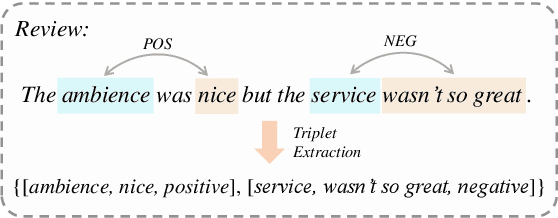
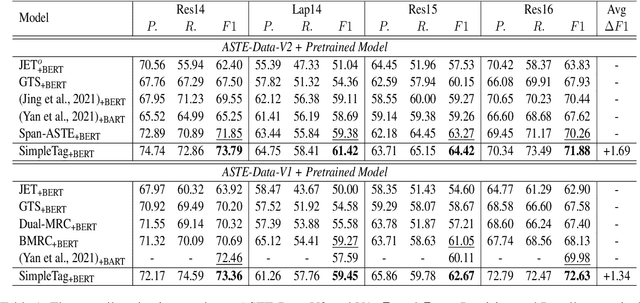
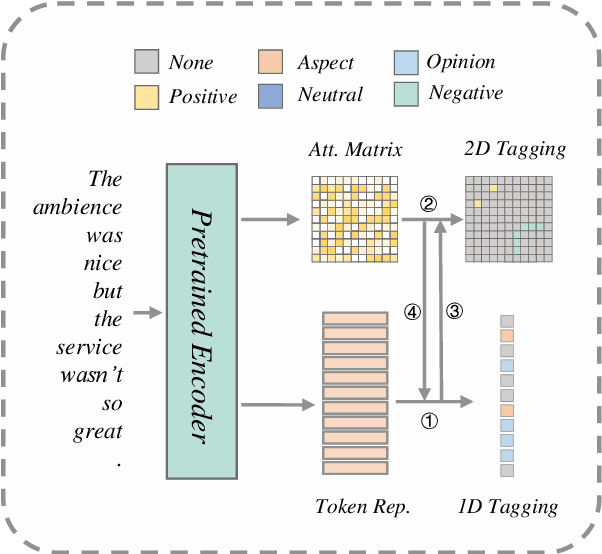
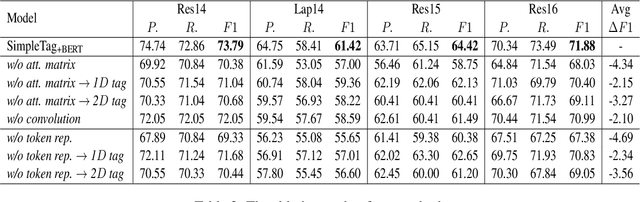
Aspect Sentiment Triplet Extraction (ASTE) aims to extract the spans of aspect, opinion, and their sentiment relations as sentiment triplets. Existing works usually formulate the span detection as a 1D token tagging problem, and model the sentiment recognition with a 2D tagging matrix of token pairs. Moreover, by leveraging the token representation of Pretrained Language Encoders (PLEs) like BERT, they can achieve better performance. However, they simply leverage PLEs as feature extractors to build their modules but never have a deep look at what specific knowledge does PLEs contain. In this paper, we argue that instead of further designing modules to capture the inductive bias of ASTE, PLEs themselves contain "enough" features for 1D and 2D tagging: (1) The token representation contains the contextualized meaning of token itself, so this level feature carries necessary information for 1D tagging. (2) The attention matrix of different PLE layers can further capture multi-level linguistic knowledge existing in token pairs, which benefits 2D tagging. (3) Furthermore, with simple transformations, these two features can also be easily converted to the 2D tagging matrix and 1D tagging sequence, respectively. That will further boost the tagging results. By doing so, PLEs can be natural tagging frameworks and achieve a new state of the art, which is verified by extensive experiments and deep analyses.
Contextualize Knowledge Bases with Transformer for End-to-end Task-Oriented Dialogue Systems
Oct 22, 2020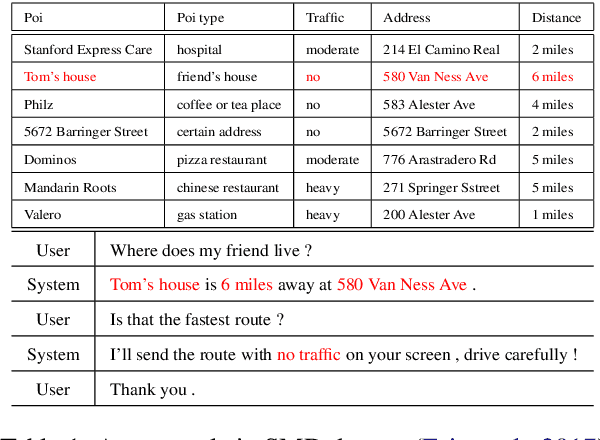


Recent studies try to build task-oriented dialogue systems in an end-to-end manner and the existing works make great progress on this task. However, there is still an issue need to be further considered, i.e., how to effectively represent the knowledge bases and incorporate that into dialogue systems. To solve this issue, we design a novel Transformer-based Context-aware Memory Generator to model the entities in knowledge bases, which can produce entity representations with perceiving all the relevant entities and dialogue history. Furthermore, we propose Context-aware Memory Enhanced Transformer (CMET), which can effectively aggregate information from the dialogue history and knowledge bases to generate more accurate responses. Through extensive experiments, our method can achieve superior performance over the state-of-the-art methods.
Improving Distant Supervised Relation Extraction by Dynamic Neural Network
Dec 13, 2019

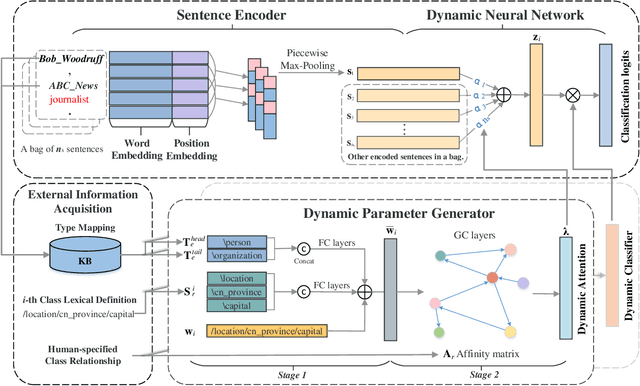

Distant Supervised Relation Extraction (DSRE) is usually formulated as a problem of classifying a bag of sentences that contain two query entities, into the predefined relation classes. Most existing methods consider those relation classes as distinct semantic categories while ignoring their potential connection to query entities. In this paper, we propose to leverage this connection to improve the relation extraction accuracy. Our key ideas are twofold: (1) For sentences belonging to the same relation class, the expression style, i.e. words choice, can vary according to the query entities. To account for this style shift, the model should adjust its parameters in accordance with entity types. (2) Some relation classes are semantically similar, and the entity types appear in one relation may also appear in others. Therefore, it can be trained cross different relation classes and further enhance those classes with few samples, i.e., long-tail classes. To unify these two arguments, we developed a novel Dynamic Neural Network for Relation Extraction (DNNRE). The network adopts a novel dynamic parameter generator that dynamically generates the network parameters according to the query entity types and relation classes. By using this mechanism, the network can simultaneously handle the style shift problem and enhance the prediction accuracy for long-tail classes. Through our experimental study, we demonstrate the effectiveness of the proposed method and show that it can achieve superior performance over the state-of-the-art methods.