 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Dense-Aligned Diffusion Guidance for Modular Conditional Image Synthesis
Apr 03, 2025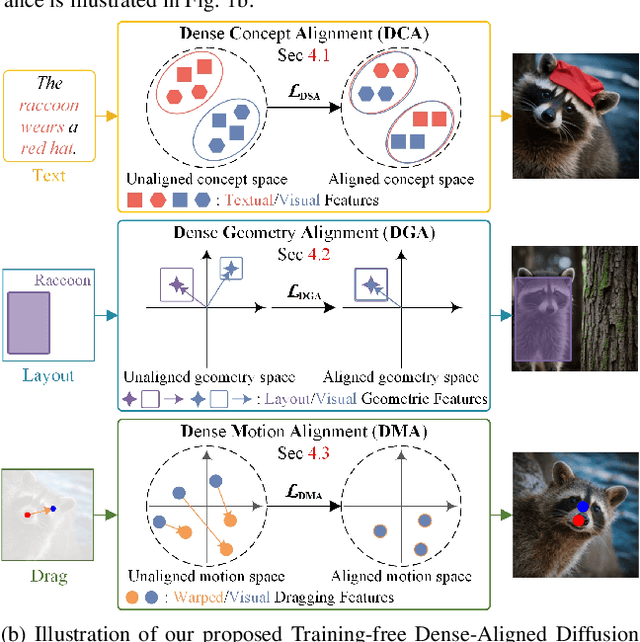
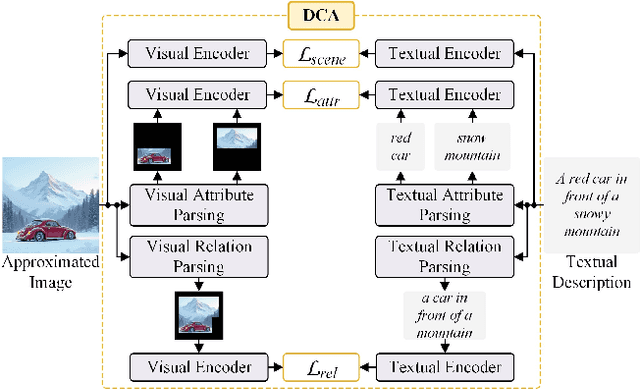
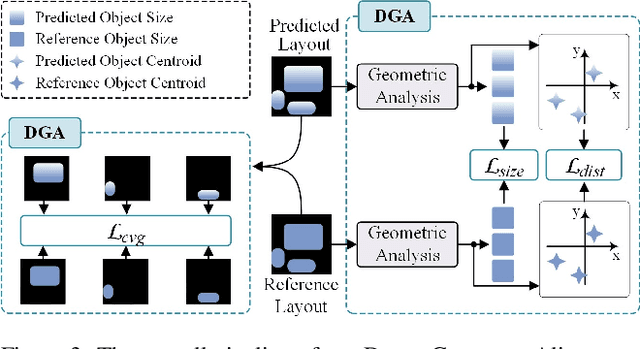
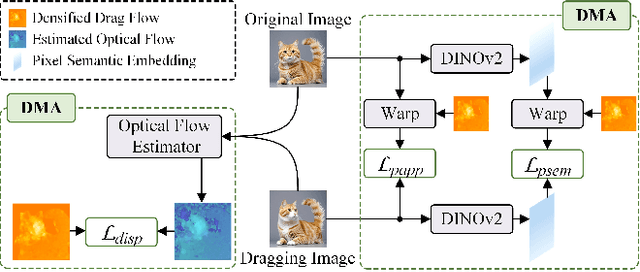
Conditional image synthesis is a crucial task with broad applications, such as artistic creation and virtual reality. However, current generative methods are often task-oriented with a narrow scope, handling a restricted condition with constrained applicability. In this paper, we propose a novel approach that treats conditional image synthesis as the modular combination of diverse fundamental condition units. Specifically, we divide conditions into three primary units: text, layout, and drag. To enable effective control over these conditions, we design a dedicated alignment module for each. For the text condition, we introduce a Dense Concept Alignment (DCA) module, which achieves dense visual-text alignment by drawing on diverse textual concepts. For the layout condition, we propose a Dense Geometry Alignment (DGA) module to enforce comprehensive geometric constraints that preserve the spatial configuration. For the drag condition, we introduce a Dense Motion Alignment (DMA) module to apply multi-level motion regularization, ensuring that each pixel follows its desired trajectory without visual artifacts. By flexibly inserting and combining these alignment modules, our framework enhances the model's adaptability to diverse conditional generation tasks and greatly expands its application range. Extensive experiments demonstrate the superior performance of our framework across a variety of conditions, including textual description, segmentation mask (bounding box), drag manipulation, and their combinations. Code is available at https://github.com/ZixuanWang0525/DADG.
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Dec 02, 2024



Research on 3D Vision-Language Models (3D-VLMs) is gaining increasing attention, which is crucial for developing embodied AI within 3D scenes, such as visual navigation and embodied question answering. Due to the high density of visual features, especially in large 3D scenes, accurately locating task-relevant visual information is challenging. Existing works attempt to segment all objects and consider their features as scene representations. However, these task-agnostic object features include much redundant information and missing details for the task-relevant area. To tackle these problems, we propose LSceneLLM, an adaptive framework that automatically identifies task-relevant areas by leveraging LLM's visual preference for different tasks, followed by a plug-and-play scene magnifier module to capture fine-grained details in focused areas. Specifically, a dense token selector examines the attention map of LLM to identify visual preferences for the instruction input. It then magnifies fine-grained details of the focusing area. An adaptive self-attention module is leveraged to fuse the coarse-grained and selected fine-grained visual information. To comprehensively evaluate the large scene understanding ability of 3D-VLMs, we further introduce a cross-room understanding benchmark, XR-Scene, which contains a series of large scene understanding tasks including XR-QA, XR-EmbodiedPlanning, and XR-SceneCaption. Experiments show that our method surpasses existing methods on both large scene understanding and existing scene understanding benchmarks. Plunging our scene magnifier module into the existing 3D-VLMs also brings significant improvement.
Recent Advances in Multi-modal 3D Scene Understanding: A Comprehensive Survey and Evaluation
Oct 24, 2023Multi-modal 3D scene understanding has gained considerable attention due to its wide applications in many areas, such as autonomous driving and human-computer interaction. Compared to conventional single-modal 3D understanding, introducing an additional modality not only elevates the richness and precision of scene interpretation but also ensures a more robust and resilient understanding. This becomes especially crucial in varied and challenging environments where solely relying on 3D data might be inadequate. While there has been a surge in the development of multi-modal 3D methods over past three years, especially those integrating multi-camera images (3D+2D) and textual descriptions (3D+language), a comprehensive and in-depth review is notably absent. In this article, we present a systematic survey of recent progress to bridge this gap. We begin by briefly introducing a background that formally defines various 3D multi-modal tasks and summarizes their inherent challenges. After that, we present a novel taxonomy that delivers a thorough categorization of existing methods according to modalities and tasks, exploring their respective strengths and limitations. Furthermore, comparative results of recent approaches on several benchmark datasets, together with insightful analysis, are offered. Finally, we discuss the unresolved issues and provide several potential avenues for future research.
Vote2Cap-DETR++: Decoupling Localization and Describing for End-to-End 3D Dense Captioning
Sep 06, 2023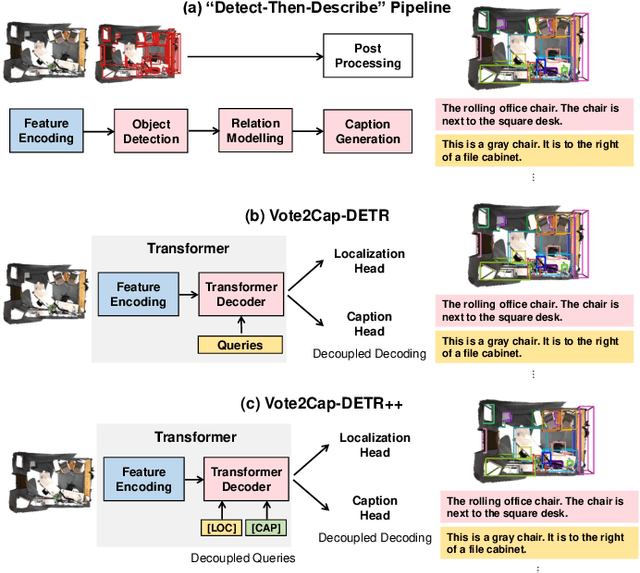
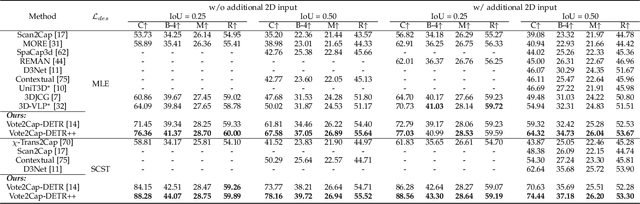
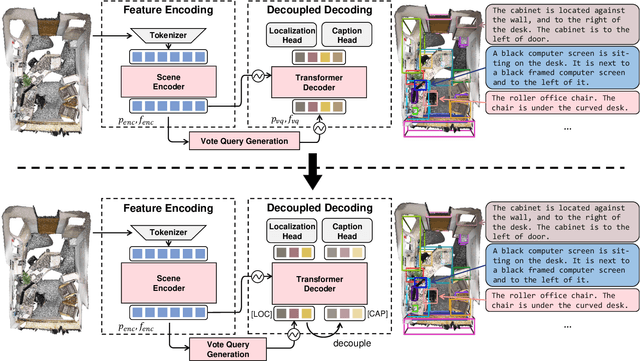
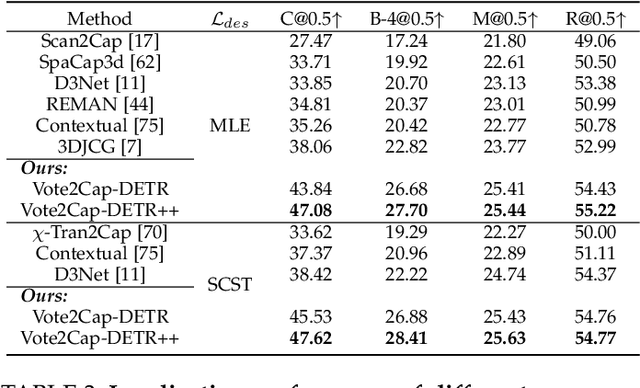
3D dense captioning requires a model to translate its understanding of an input 3D scene into several captions associated with different object regions. Existing methods adopt a sophisticated "detect-then-describe" pipeline, which builds explicit relation modules upon a 3D detector with numerous hand-crafted components. While these methods have achieved initial success, the cascade pipeline tends to accumulate errors because of duplicated and inaccurate box estimations and messy 3D scenes. In this paper, we first propose Vote2Cap-DETR, a simple-yet-effective transformer framework that decouples the decoding process of caption generation and object localization through parallel decoding. Moreover, we argue that object localization and description generation require different levels of scene understanding, which could be challenging for a shared set of queries to capture. To this end, we propose an advanced version, Vote2Cap-DETR++, which decouples the queries into localization and caption queries to capture task-specific features. Additionally, we introduce the iterative spatial refinement strategy to vote queries for faster convergence and better localization performance. We also insert additional spatial information to the caption head for more accurate descriptions. Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate Vote2Cap-DETR and Vote2Cap-DETR++ surpass conventional "detect-then-describe" methods by a large margin. Codes will be made available at https://github.com/ch3cook-fdu/Vote2Cap-DETR.
Unsupervised Domain Adaptation via Domain-Adaptive Diffusion
Aug 26, 2023Unsupervised Domain Adaptation (UDA) is quite challenging due to the large distribution discrepancy between the source domain and the target domain. Inspired by diffusion models which have strong capability to gradually convert data distributions across a large gap, we consider to explore the diffusion technique to handle the challenging UDA task. However, using diffusion models to convert data distribution across different domains is a non-trivial problem as the standard diffusion models generally perform conversion from the Gaussian distribution instead of from a specific domain distribution. Besides, during the conversion, the semantics of the source-domain data needs to be preserved for classification in the target domain. To tackle these problems, we propose a novel Domain-Adaptive Diffusion (DAD) module accompanied by a Mutual Learning Strategy (MLS), which can gradually convert data distribution from the source domain to the target domain while enabling the classification model to learn along the domain transition process. Consequently, our method successfully eases the challenge of UDA by decomposing the large domain gap into small ones and gradually enhancing the capacity of classification model to finally adapt to the target domain. Our method outperforms the current state-of-the-arts by a large margin on three widely used UDA datasets.
Unsupervised Image Denoising in Real-World Scenarios via Self-Collaboration Parallel Generative Adversarial Branches
Aug 13, 2023



Deep learning methods have shown remarkable performance in image denoising, particularly when trained on large-scale paired datasets. However, acquiring such paired datasets for real-world scenarios poses a significant challenge. Although unsupervised approaches based on generative adversarial networks offer a promising solution for denoising without paired datasets, they are difficult in surpassing the performance limitations of conventional GAN-based unsupervised frameworks without significantly modifying existing structures or increasing the computational complexity of denoisers. To address this problem, we propose a SC strategy for multiple denoisers. This strategy can achieve significant performance improvement without increasing the inference complexity of the GAN-based denoising framework. Its basic idea is to iteratively replace the previous less powerful denoiser in the filter-guided noise extraction module with the current powerful denoiser. This process generates better synthetic clean-noisy image pairs, leading to a more powerful denoiser for the next iteration. This baseline ensures the stability and effectiveness of the training network. The experimental results demonstrate the superiority of our method over state-of-the-art unsupervised methods.
End-to-End 3D Dense Captioning with Vote2Cap-DETR
Jan 06, 2023



3D dense captioning aims to generate multiple captions localized with their associated object regions. Existing methods follow a sophisticated ``detect-then-describe'' pipeline equipped with numerous hand-crafted components. However, these hand-crafted components would yield suboptimal performance given cluttered object spatial and class distributions among different scenes. In this paper, we propose a simple-yet-effective transformer framework Vote2Cap-DETR based on recent popular \textbf{DE}tection \textbf{TR}ansformer (DETR). Compared with prior arts, our framework has several appealing advantages: 1) Without resorting to numerous hand-crafted components, our method is based on a full transformer encoder-decoder architecture with a learnable vote query driven object decoder, and a caption decoder that produces the dense captions in a set-prediction manner. 2) In contrast to the two-stage scheme, our method can perform detection and captioning in one-stage. 3) Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate that our Vote2Cap-DETR surpasses current state-of-the-arts by 11.13\% and 7.11\% in CIDEr@0.5IoU, respectively. Codes will be released soon.
ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
Dec 12, 2022



Recently, CLIP has been applied to pixel-level zero-shot learning tasks via a two-stage scheme. The general idea is to first generate class-agnostic region proposals and then feed the cropped proposal regions to CLIP to utilize its image-level zero-shot classification capability. While effective, such a scheme requires two image encoders, one for proposal generation and one for CLIP, leading to a complicated pipeline and high computational cost. In this work, we pursue a simpler-and-efficient one-stage solution that directly extends CLIP's zero-shot prediction capability from image to pixel level. Our investigation starts with a straightforward extension as our baseline that generates semantic masks by comparing the similarity between text and patch embeddings extracted from CLIP. However, such a paradigm could heavily overfit the seen classes and fail to generalize to unseen classes. To handle this issue, we propose three simple-but-effective designs and figure out that they can significantly retain the inherent zero-shot capacity of CLIP and improve pixel-level generalization ability. Incorporating those modifications leads to an efficient zero-shot semantic segmentation system called ZegCLIP. Through extensive experiments on three public benchmarks, ZegCLIP demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both "inductive" and "transductive" zero-shot settings. In addition, compared with the two-stage method, our one-stage ZegCLIP achieves a speedup of about 5 times faster during inference. We release the code at https://github.com/ZiqinZhou66/ZegCLIP.git.
Pretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction
Aug 20, 2022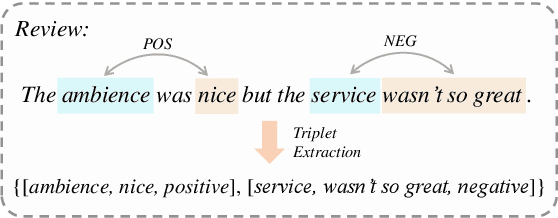
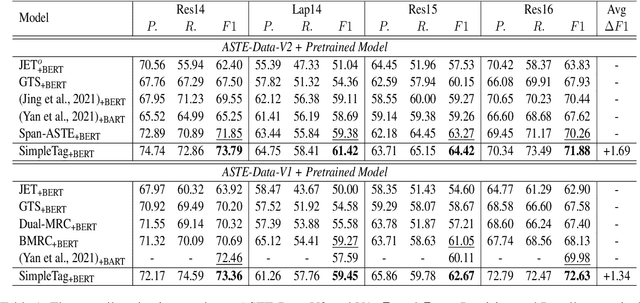
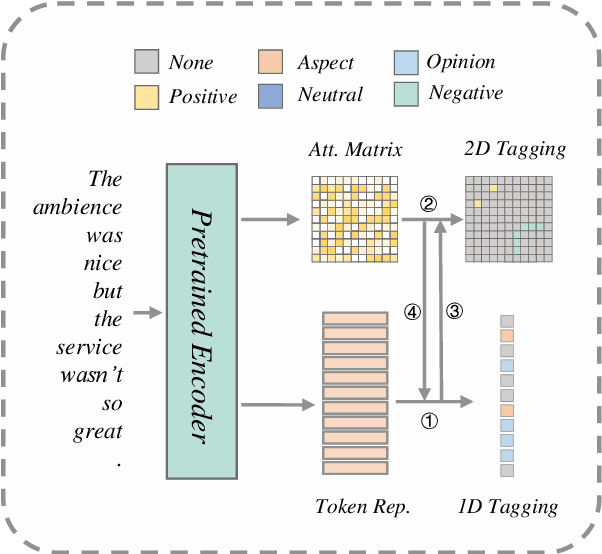
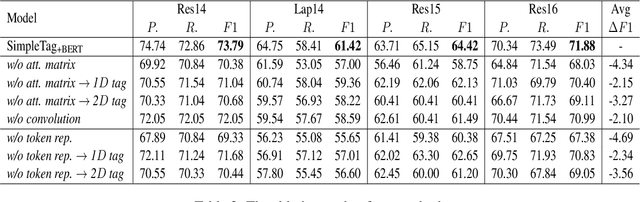
Aspect Sentiment Triplet Extraction (ASTE) aims to extract the spans of aspect, opinion, and their sentiment relations as sentiment triplets. Existing works usually formulate the span detection as a 1D token tagging problem, and model the sentiment recognition with a 2D tagging matrix of token pairs. Moreover, by leveraging the token representation of Pretrained Language Encoders (PLEs) like BERT, they can achieve better performance. However, they simply leverage PLEs as feature extractors to build their modules but never have a deep look at what specific knowledge does PLEs contain. In this paper, we argue that instead of further designing modules to capture the inductive bias of ASTE, PLEs themselves contain "enough" features for 1D and 2D tagging: (1) The token representation contains the contextualized meaning of token itself, so this level feature carries necessary information for 1D tagging. (2) The attention matrix of different PLE layers can further capture multi-level linguistic knowledge existing in token pairs, which benefits 2D tagging. (3) Furthermore, with simple transformations, these two features can also be easily converted to the 2D tagging matrix and 1D tagging sequence, respectively. That will further boost the tagging results. By doing so, PLEs can be natural tagging frameworks and achieve a new state of the art, which is verified by extensive experiments and deep analyses.
Semantic-Aware Domain Generalized Segmentation
Apr 02, 2022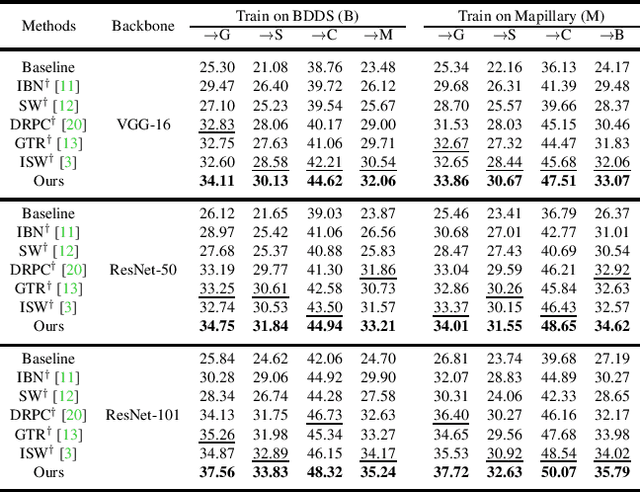
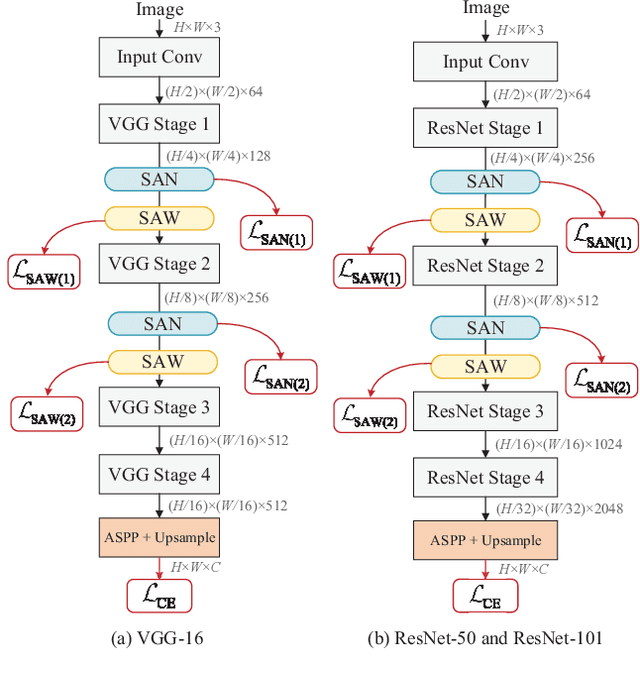
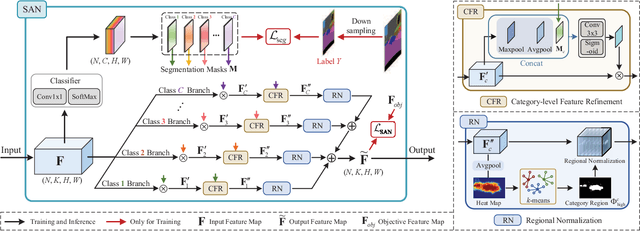

Deep models trained on source domain lack generalization when evaluated on unseen target domains with different data distributions. The problem becomes even more pronounced when we have no access to target domain samples for adaptation. In this paper, we address domain generalized semantic segmentation, where a segmentation model is trained to be domain-invariant without using any target domain data. Existing approaches to tackle this problem standardize data into a unified distribution. We argue that while such a standardization promotes global normalization, the resulting features are not discriminative enough to get clear segmentation boundaries. To enhance separation between categories while simultaneously promoting domain invariance, we propose a framework including two novel modules: Semantic-Aware Normalization (SAN) and Semantic-Aware Whitening (SAW). Specifically, SAN focuses on category-level center alignment between features from different image styles, while SAW enforces distributed alignment for the already center-aligned features. With the help of SAN and SAW, we encourage both intra-category compactness and inter-category separability. We validate our approach through extensive experiments on widely-used datasets (i.e. GTAV, SYNTHIA, Cityscapes, Mapillary and BDDS). Our approach shows significant improvements over existing state-of-the-art on various backbone networks. Code is available at https://github.com/leolyj/SAN-SAW