 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
Mar 26, 2026Image restoration under real-world degradations is critical for downstream tasks such as autonomous driving and object detection. However, existing restoration models are often limited by the scale and distribution of their training data, resulting in poor generalization to real-world scenarios. Recently, large-scale image editing models have shown strong generalization ability in restoration tasks, especially for closed-source models like Nano Banana Pro, which can restore images while preserving consistency. Nevertheless, achieving such performance with those large universal models requires substantial data and computational costs. To address this issue, we construct a large-scale dataset covering nine common real-world degradation types and train a state-of-the-art open-source model to narrow the gap with closed-source alternatives. Furthermore, we introduce RealIR-Bench, which contains 464 real-world degraded images and tailored evaluation metrics focusing on degradation removal and consistency preservation. Extensive experiments demonstrate our model ranks first among open-source methods, achieving state-of-the-art performance.
MotionChain: Conversational Motion Controllers via Multimodal Prompts
Apr 03, 2024



Recent advancements in language models have demonstrated their adeptness in conducting multi-turn dialogues and retaining conversational context. However, this proficiency remains largely unexplored in other multimodal generative models, particularly in human motion models. By integrating multi-turn conversations in controlling continuous virtual human movements, generative human motion models can achieve an intuitive and step-by-step process of human task execution for humanoid robotics, game agents, or other embodied systems. In this work, we present MotionChain, a conversational human motion controller to generate continuous and long-term human motion through multimodal prompts. Specifically, MotionChain consists of multi-modal tokenizers that transform various data types such as text, image, and motion, into discrete tokens, coupled with a Vision-Motion-aware Language model. By leveraging large-scale language, vision-language, and vision-motion data to assist motion-related generation tasks, MotionChain thus comprehends each instruction in multi-turn conversation and generates human motions followed by these prompts. Extensive experiments validate the efficacy of MotionChain, demonstrating state-of-the-art performance in conversational motion generation, as well as more intuitive manners of controlling and interacting with virtual humans.
PDF: Point Diffusion Implicit Function for Large-scale Scene Neural Representation
Nov 03, 2023Recent advances in implicit neural representations have achieved impressive results by sampling and fusing individual points along sampling rays in the sampling space. However, due to the explosively growing sampling space, finely representing and synthesizing detailed textures remains a challenge for unbounded large-scale outdoor scenes. To alleviate the dilemma of using individual points to perceive the entire colossal space, we explore learning the surface distribution of the scene to provide structural priors and reduce the samplable space and propose a Point Diffusion implicit Function, PDF, for large-scale scene neural representation. The core of our method is a large-scale point cloud super-resolution diffusion module that enhances the sparse point cloud reconstructed from several training images into a dense point cloud as an explicit prior. Then in the rendering stage, only sampling points with prior points within the sampling radius are retained. That is, the sampling space is reduced from the unbounded space to the scene surface. Meanwhile, to fill in the background of the scene that cannot be provided by point clouds, the region sampling based on Mip-NeRF 360 is employed to model the background representation. Expensive experiments have demonstrated the effectiveness of our method for large-scale scene novel view synthesis, which outperforms relevant state-of-the-art baselines.
StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation
May 31, 2023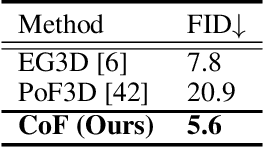
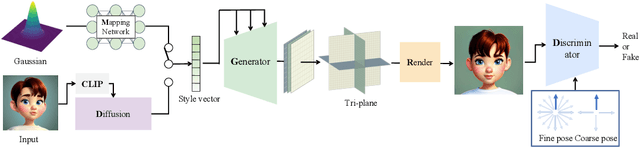


The recent advancements in image-text diffusion models have stimulated research interest in large-scale 3D generative models. Nevertheless, the limited availability of diverse 3D resources presents significant challenges to learning. In this paper, we present a novel method for generating high-quality, stylized 3D avatars that utilizes pre-trained image-text diffusion models for data generation and a Generative Adversarial Network (GAN)-based 3D generation network for training. Our method leverages the comprehensive priors of appearance and geometry offered by image-text diffusion models to generate multi-view images of avatars in various styles. During data generation, we employ poses extracted from existing 3D models to guide the generation of multi-view images. To address the misalignment between poses and images in data, we investigate view-specific prompts and develop a coarse-to-fine discriminator for GAN training. We also delve into attribute-related prompts to increase the diversity of the generated avatars. Additionally, we develop a latent diffusion model within the style space of StyleGAN to enable the generation of avatars based on image inputs. Our approach demonstrates superior performance over current state-of-the-art methods in terms of visual quality and diversity of the produced avatars.
A Large-Scale Outdoor Multi-modal Dataset and Benchmark for Novel View Synthesis and Implicit Scene Reconstruction
Jan 17, 2023Neural Radiance Fields (NeRF) has achieved impressive results in single object scene reconstruction and novel view synthesis, which have been demonstrated on many single modality and single object focused indoor scene datasets like DTU, BMVS, and NeRF Synthetic.However, the study of NeRF on large-scale outdoor scene reconstruction is still limited, as there is no unified outdoor scene dataset for large-scale NeRF evaluation due to expensive data acquisition and calibration costs. In this paper, we propose a large-scale outdoor multi-modal dataset, OMMO dataset, containing complex land objects and scenes with calibrated images, point clouds and prompt annotations. Meanwhile, a new benchmark for several outdoor NeRF-based tasks is established, such as novel view synthesis, surface reconstruction, and multi-modal NeRF. To create the dataset, we capture and collect a large number of real fly-view videos and select high-quality and high-resolution clips from them. Then we design a quality review module to refine images, remove low-quality frames and fail-to-calibrate scenes through a learning-based automatic evaluation plus manual review. Finally, a number of volunteers are employed to add the text descriptions for each scene and key-frame to meet the potential multi-modal requirements in the future. Compared with existing NeRF datasets, our dataset contains abundant real-world urban and natural scenes with various scales, camera trajectories, and lighting conditions. Experiments show that our dataset can benchmark most state-of-the-art NeRF methods on different tasks. We will release the dataset and model weights very soon.
End-to-End 3D Dense Captioning with Vote2Cap-DETR
Jan 06, 2023



3D dense captioning aims to generate multiple captions localized with their associated object regions. Existing methods follow a sophisticated ``detect-then-describe'' pipeline equipped with numerous hand-crafted components. However, these hand-crafted components would yield suboptimal performance given cluttered object spatial and class distributions among different scenes. In this paper, we propose a simple-yet-effective transformer framework Vote2Cap-DETR based on recent popular \textbf{DE}tection \textbf{TR}ansformer (DETR). Compared with prior arts, our framework has several appealing advantages: 1) Without resorting to numerous hand-crafted components, our method is based on a full transformer encoder-decoder architecture with a learnable vote query driven object decoder, and a caption decoder that produces the dense captions in a set-prediction manner. 2) In contrast to the two-stage scheme, our method can perform detection and captioning in one-stage. 3) Without bells and whistles, extensive experiments on two commonly used datasets, ScanRefer and Nr3D, demonstrate that our Vote2Cap-DETR surpasses current state-of-the-arts by 11.13\% and 7.11\% in CIDEr@0.5IoU, respectively. Codes will be released soon.
Coordinates Are NOT Lonely -- Codebook Prior Helps Implicit Neural 3D Representations
Oct 20, 2022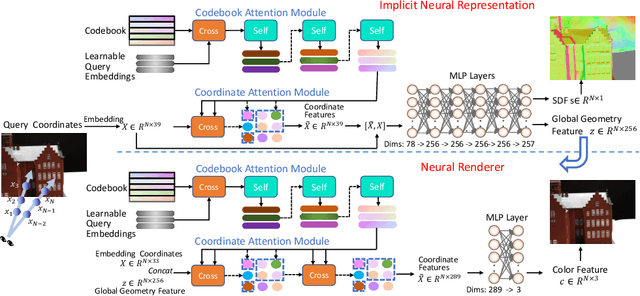


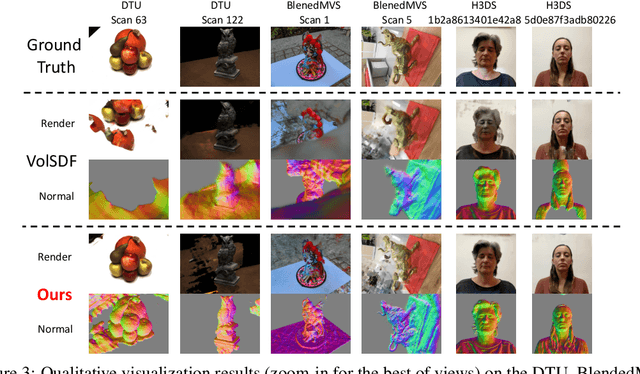
Implicit neural 3D representation has achieved impressive results in surface or scene reconstruction and novel view synthesis, which typically uses the coordinate-based multi-layer perceptrons (MLPs) to learn a continuous scene representation. However, existing approaches, such as Neural Radiance Field (NeRF) and its variants, usually require dense input views (i.e. 50-150) to obtain decent results. To relive the over-dependence on massive calibrated images and enrich the coordinate-based feature representation, we explore injecting the prior information into the coordinate-based network and introduce a novel coordinate-based model, CoCo-INR, for implicit neural 3D representation. The cores of our method are two attention modules: codebook attention and coordinate attention. The former extracts the useful prototypes containing rich geometry and appearance information from the prior codebook, and the latter propagates such prior information into each coordinate and enriches its feature representation for a scene or object surface. With the help of the prior information, our method can render 3D views with more photo-realistic appearance and geometries than the current methods using fewer calibrated images available. Experiments on various scene reconstruction datasets, including DTU and BlendedMVS, and the full 3D head reconstruction dataset, H3DS, demonstrate the robustness under fewer input views and fine detail-preserving capability of our proposed method.