 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionChain: Conversational Motion Controllers via Multimodal Prompts
Apr 03, 2024



Recent advancements in language models have demonstrated their adeptness in conducting multi-turn dialogues and retaining conversational context. However, this proficiency remains largely unexplored in other multimodal generative models, particularly in human motion models. By integrating multi-turn conversations in controlling continuous virtual human movements, generative human motion models can achieve an intuitive and step-by-step process of human task execution for humanoid robotics, game agents, or other embodied systems. In this work, we present MotionChain, a conversational human motion controller to generate continuous and long-term human motion through multimodal prompts. Specifically, MotionChain consists of multi-modal tokenizers that transform various data types such as text, image, and motion, into discrete tokens, coupled with a Vision-Motion-aware Language model. By leveraging large-scale language, vision-language, and vision-motion data to assist motion-related generation tasks, MotionChain thus comprehends each instruction in multi-turn conversation and generates human motions followed by these prompts. Extensive experiments validate the efficacy of MotionChain, demonstrating state-of-the-art performance in conversational motion generation, as well as more intuitive manners of controlling and interacting with virtual humans.
ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
Dec 01, 2023



The advent of large language models, enabling flexibility through instruction-driven approaches, has revolutionized many traditional generative tasks, but large models for 3D data, particularly in comprehensively handling 3D shapes with other modalities, are still under-explored. By achieving instruction-based shape generations, versatile multimodal generative shape models can significantly benefit various fields like 3D virtual construction and network-aided design. In this work, we present ShapeGPT, a shape-included multi-modal framework to leverage strong pre-trained language models to address multiple shape-relevant tasks. Specifically, ShapeGPT employs a word-sentence-paragraph framework to discretize continuous shapes into shape words, further assembles these words for shape sentences, as well as integrates shape with instructional text for multi-modal paragraphs. To learn this shape-language model, we use a three-stage training scheme, including shape representation, multimodal alignment, and instruction-based generation, to align shape-language codebooks and learn the intricate correlations among these modalities. Extensive experiments demonstrate that ShapeGPT achieves comparable performance across shape-relevant tasks, including text-to-shape, shape-to-text, shape completion, and shape editing.
MotionGPT: Human Motion as a Foreign Language
Jun 26, 2023



Though the advancement of pre-trained large language models unfolds, the exploration of building a unified model for language and other multi-modal data, such as motion, remains challenging and untouched so far. Fortunately, human motion displays a semantic coupling akin to human language, often perceived as a form of body language. By fusing language data with large-scale motion models, motion-language pre-training that can enhance the performance of motion-related tasks becomes feasible. Driven by this insight, we propose MotionGPT, a unified, versatile, and user-friendly motion-language model to handle multiple motion-relevant tasks. Specifically, we employ the discrete vector quantization for human motion and transfer 3D motion into motion tokens, similar to the generation process of word tokens. Building upon this "motion vocabulary", we perform language modeling on both motion and text in a unified manner, treating human motion as a specific language. Moreover, inspired by prompt learning, we pre-train MotionGPT with a mixture of motion-language data and fine-tune it on prompt-based question-and-answer tasks. Extensive experiments demonstrate that MotionGPT achieves state-of-the-art performances on multiple motion tasks including text-driven motion generation, motion captioning, motion prediction, and motion in-between.
Financial Distress Prediction For Small And Medium Enterprises Using Machine Learning Techniques
Feb 23, 2023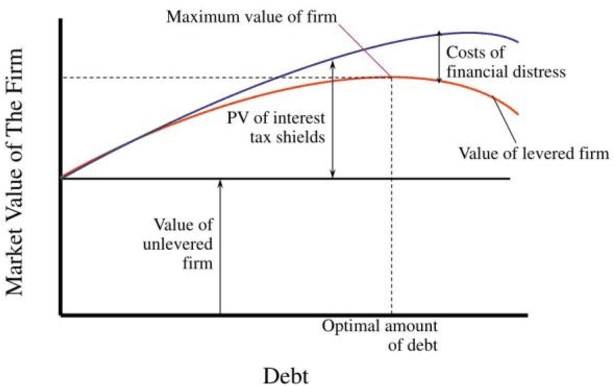
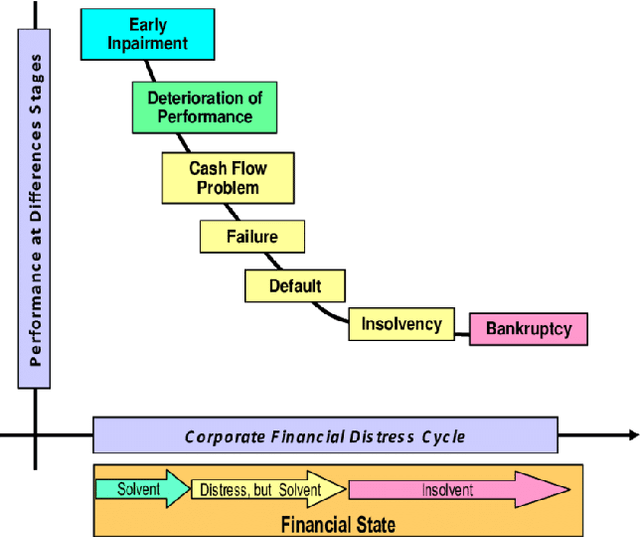
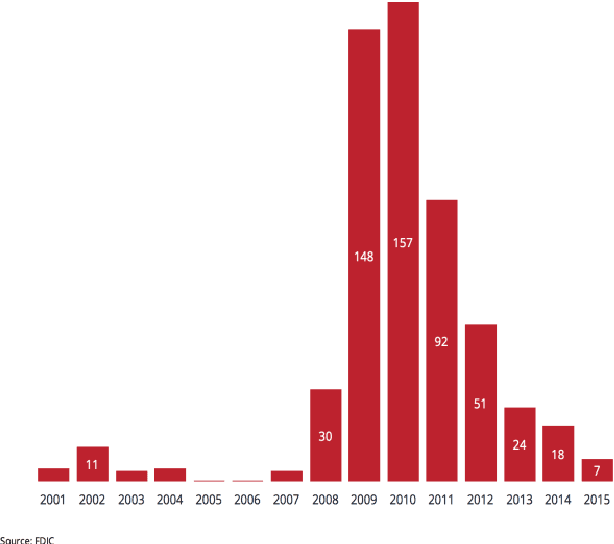
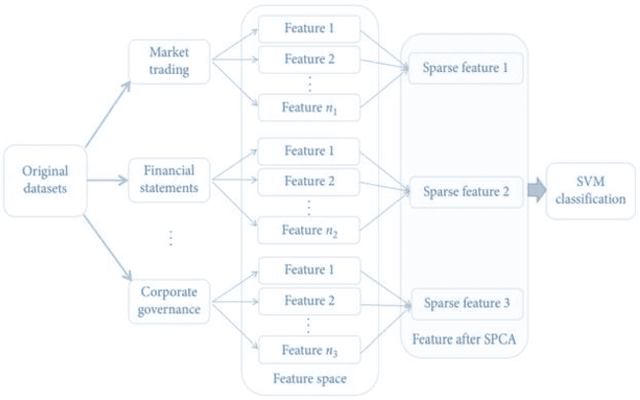
Financial Distress Prediction plays a crucial role in the economy by accurately forecasting the number and probability of failing structures, providing insight into the growth and stability of a country's economy. However, predicting financial distress for Small and Medium Enterprises is challenging due to their inherent ambiguity, leading to increased funding costs and decreased chances of receiving funds. While several strategies have been developed for effective FCP, their implementation, accuracy, and data security fall short of practical applications. Additionally, many of these strategies perform well for a portion of the dataset but are not adaptable to various datasets. As a result, there is a need to develop a productive prediction model for better order execution and adaptability to different datasets. In this review, we propose a feature selection algorithm for FCP based on element credits and data source collection. Current financial distress prediction models rely mainly on financial statements and disregard the timeliness of organization tests. Therefore, we propose a corporate FCP model that better aligns with industry practice and incorporates the gathering of thin-head component analysis of financial data, corporate governance qualities, and market exchange data with a Relevant Vector Machine. Experimental results demonstrate that this strategy can improve the forecast efficiency of financial distress with fewer characteristic factors.
Executing your Commands via Motion Diffusion in Latent Space
Dec 08, 2022



We study a challenging task, conditional human motion generation, which produces plausible human motion sequences according to various conditional inputs, such as action classes or textual descriptors. Since human motions are highly diverse and have a property of quite different distribution from conditional modalities, such as textual descriptors in natural languages, it is hard to learn a probabilistic mapping from the desired conditional modality to the human motion sequences. Besides, the raw motion data from the motion capture system might be redundant in sequences and contain noises; directly modeling the joint distribution over the raw motion sequences and conditional modalities would need a heavy computational overhead and might result in artifacts introduced by the captured noises. To learn a better representation of the various human motion sequences, we first design a powerful Variational AutoEncoder (VAE) and arrive at a representative and low-dimensional latent code for a human motion sequence. Then, instead of using a diffusion model to establish the connections between the raw motion sequences and the conditional inputs, we perform a diffusion process on the motion latent space. Our proposed Motion Latent-based Diffusion model (MLD) could produce vivid motion sequences conforming to the given conditional inputs and substantially reduce the computational overhead in both the training and inference stages. Extensive experiments on various human motion generation tasks demonstrate that our MLD achieves significant improvements over the state-of-the-art methods among extensive human motion generation tasks, with two orders of magnitude faster than previous diffusion models on raw motion sequences.