 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
Mar 26, 2026Image restoration under real-world degradations is critical for downstream tasks such as autonomous driving and object detection. However, existing restoration models are often limited by the scale and distribution of their training data, resulting in poor generalization to real-world scenarios. Recently, large-scale image editing models have shown strong generalization ability in restoration tasks, especially for closed-source models like Nano Banana Pro, which can restore images while preserving consistency. Nevertheless, achieving such performance with those large universal models requires substantial data and computational costs. To address this issue, we construct a large-scale dataset covering nine common real-world degradation types and train a state-of-the-art open-source model to narrow the gap with closed-source alternatives. Furthermore, we introduce RealIR-Bench, which contains 464 real-world degraded images and tailored evaluation metrics focusing on degradation removal and consistency preservation. Extensive experiments demonstrate our model ranks first among open-source methods, achieving state-of-the-art performance.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
Scene123: One Prompt to 3D Scene Generation via Video-Assisted and Consistency-Enhanced MAE
Aug 10, 2024



As Artificial Intelligence Generated Content (AIGC) advances, a variety of methods have been developed to generate text, images, videos, and 3D objects from single or multimodal inputs, contributing efforts to emulate human-like cognitive content creation. However, generating realistic large-scale scenes from a single input presents a challenge due to the complexities involved in ensuring consistency across extrapolated views generated by models. Benefiting from recent video generation models and implicit neural representations, we propose Scene123, a 3D scene generation model, that not only ensures realism and diversity through the video generation framework but also uses implicit neural fields combined with Masked Autoencoders (MAE) to effectively ensures the consistency of unseen areas across views. Specifically, we initially warp the input image (or an image generated from text) to simulate adjacent views, filling the invisible areas with the MAE model. However, these filled images usually fail to maintain view consistency, thus we utilize the produced views to optimize a neural radiance field, enhancing geometric consistency. Moreover, to further enhance the details and texture fidelity of generated views, we employ a GAN-based Loss against images derived from the input image through the video generation model. Extensive experiments demonstrate that our method can generate realistic and consistent scenes from a single prompt. Both qualitative and quantitative results indicate that our approach surpasses existing state-of-the-art methods. We show encourage video examples at https://yiyingyang12.github.io/Scene123.github.io/.
MeshXL: Neural Coordinate Field for Generative 3D Foundation Models
May 31, 2024



The polygon mesh representation of 3D data exhibits great flexibility, fast rendering speed, and storage efficiency, which is widely preferred in various applications. However, given its unstructured graph representation, the direct generation of high-fidelity 3D meshes is challenging. Fortunately, with a pre-defined ordering strategy, 3D meshes can be represented as sequences, and the generation process can be seamlessly treated as an auto-regressive problem. In this paper, we validate the Neural Coordinate Field (NeurCF), an explicit coordinate representation with implicit neural embeddings, is a simple-yet-effective representation for large-scale sequential mesh modeling. After that, we present MeshXL, a family of generative pre-trained auto-regressive models, which addresses the process of 3D mesh generation with modern large language model approaches. Extensive experiments show that MeshXL is able to generate high-quality 3D meshes, and can also serve as foundation models for various down-stream applications.
MotionChain: Conversational Motion Controllers via Multimodal Prompts
Apr 03, 2024



Recent advancements in language models have demonstrated their adeptness in conducting multi-turn dialogues and retaining conversational context. However, this proficiency remains largely unexplored in other multimodal generative models, particularly in human motion models. By integrating multi-turn conversations in controlling continuous virtual human movements, generative human motion models can achieve an intuitive and step-by-step process of human task execution for humanoid robotics, game agents, or other embodied systems. In this work, we present MotionChain, a conversational human motion controller to generate continuous and long-term human motion through multimodal prompts. Specifically, MotionChain consists of multi-modal tokenizers that transform various data types such as text, image, and motion, into discrete tokens, coupled with a Vision-Motion-aware Language model. By leveraging large-scale language, vision-language, and vision-motion data to assist motion-related generation tasks, MotionChain thus comprehends each instruction in multi-turn conversation and generates human motions followed by these prompts. Extensive experiments validate the efficacy of MotionChain, demonstrating state-of-the-art performance in conversational motion generation, as well as more intuitive manners of controlling and interacting with virtual humans.
M3DBench: Let's Instruct Large Models with Multi-modal 3D Prompts
Dec 17, 2023



Recently, 3D understanding has become popular to facilitate autonomous agents to perform further decisionmaking. However, existing 3D datasets and methods are often limited to specific tasks. On the other hand, recent progress in Large Language Models (LLMs) and Multimodal Language Models (MLMs) have demonstrated exceptional general language and imagery tasking performance. Therefore, it is interesting to unlock MLM's potential to be 3D generalist for wider tasks. However, current MLMs' research has been less focused on 3D tasks due to a lack of large-scale 3D instruction-following datasets. In this work, we introduce a comprehensive 3D instructionfollowing dataset called M3DBench, which possesses the following characteristics: 1) It supports general multimodal instructions interleaved with text, images, 3D objects, and other visual prompts. 2) It unifies diverse 3D tasks at both region and scene levels, covering a variety of fundamental abilities in real-world 3D environments. 3) It is a large-scale 3D instruction-following dataset with over 320k instruction-response pairs. Furthermore, we establish a new benchmark for assessing the performance of large models in understanding multi-modal 3D prompts. Extensive experiments demonstrate the effectiveness of our dataset and baseline, supporting general 3D-centric tasks, which can inspire future research.
ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
Dec 01, 2023



The advent of large language models, enabling flexibility through instruction-driven approaches, has revolutionized many traditional generative tasks, but large models for 3D data, particularly in comprehensively handling 3D shapes with other modalities, are still under-explored. By achieving instruction-based shape generations, versatile multimodal generative shape models can significantly benefit various fields like 3D virtual construction and network-aided design. In this work, we present ShapeGPT, a shape-included multi-modal framework to leverage strong pre-trained language models to address multiple shape-relevant tasks. Specifically, ShapeGPT employs a word-sentence-paragraph framework to discretize continuous shapes into shape words, further assembles these words for shape sentences, as well as integrates shape with instructional text for multi-modal paragraphs. To learn this shape-language model, we use a three-stage training scheme, including shape representation, multimodal alignment, and instruction-based generation, to align shape-language codebooks and learn the intricate correlations among these modalities. Extensive experiments demonstrate that ShapeGPT achieves comparable performance across shape-relevant tasks, including text-to-shape, shape-to-text, shape completion, and shape editing.
PDF: Point Diffusion Implicit Function for Large-scale Scene Neural Representation
Nov 03, 2023Recent advances in implicit neural representations have achieved impressive results by sampling and fusing individual points along sampling rays in the sampling space. However, due to the explosively growing sampling space, finely representing and synthesizing detailed textures remains a challenge for unbounded large-scale outdoor scenes. To alleviate the dilemma of using individual points to perceive the entire colossal space, we explore learning the surface distribution of the scene to provide structural priors and reduce the samplable space and propose a Point Diffusion implicit Function, PDF, for large-scale scene neural representation. The core of our method is a large-scale point cloud super-resolution diffusion module that enhances the sparse point cloud reconstructed from several training images into a dense point cloud as an explicit prior. Then in the rendering stage, only sampling points with prior points within the sampling radius are retained. That is, the sampling space is reduced from the unbounded space to the scene surface. Meanwhile, to fill in the background of the scene that cannot be provided by point clouds, the region sampling based on Mip-NeRF 360 is employed to model the background representation. Expensive experiments have demonstrated the effectiveness of our method for large-scale scene novel view synthesis, which outperforms relevant state-of-the-art baselines.
VQ-NeRF: Vector Quantization Enhances Implicit Neural Representations
Oct 23, 2023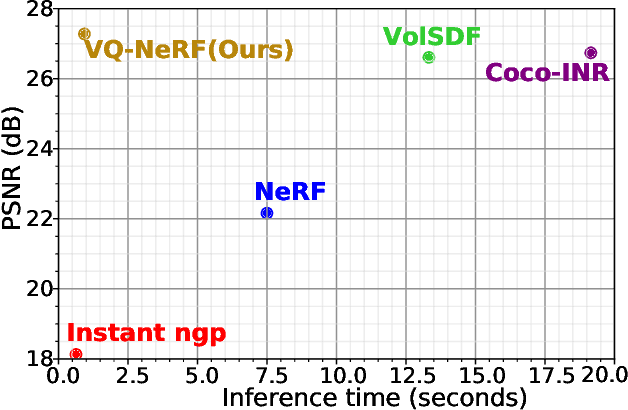

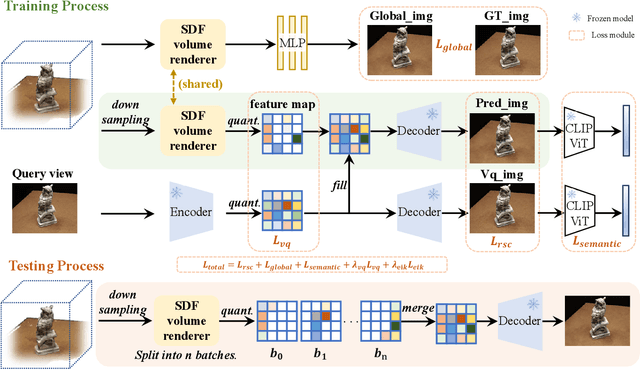
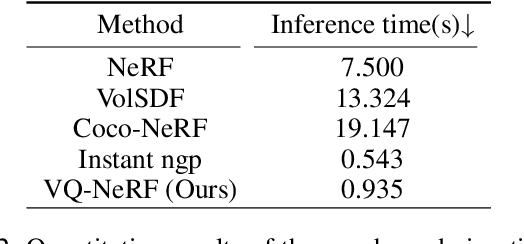
Recent advancements in implicit neural representations have contributed to high-fidelity surface reconstruction and photorealistic novel view synthesis. However, the computational complexity inherent in these methodologies presents a substantial impediment, constraining the attainable frame rates and resolutions in practical applications. In response to this predicament, we propose VQ-NeRF, an effective and efficient pipeline for enhancing implicit neural representations via vector quantization. The essence of our method involves reducing the sampling space of NeRF to a lower resolution and subsequently reinstating it to the original size utilizing a pre-trained VAE decoder, thereby effectively mitigating the sampling time bottleneck encountered during rendering. Although the codebook furnishes representative features, reconstructing fine texture details of the scene remains challenging due to high compression rates. To overcome this constraint, we design an innovative multi-scale NeRF sampling scheme that concurrently optimizes the NeRF model at both compressed and original scales to enhance the network's ability to preserve fine details. Furthermore, we incorporate a semantic loss function to improve the geometric fidelity and semantic coherence of our 3D reconstructions. Extensive experiments demonstrate the effectiveness of our model in achieving the optimal trade-off between rendering quality and efficiency. Evaluation on the DTU, BlendMVS, and H3DS datasets confirms the superior performance of our approach.
A Large-Scale Outdoor Multi-modal Dataset and Benchmark for Novel View Synthesis and Implicit Scene Reconstruction
Jan 17, 2023Neural Radiance Fields (NeRF) has achieved impressive results in single object scene reconstruction and novel view synthesis, which have been demonstrated on many single modality and single object focused indoor scene datasets like DTU, BMVS, and NeRF Synthetic.However, the study of NeRF on large-scale outdoor scene reconstruction is still limited, as there is no unified outdoor scene dataset for large-scale NeRF evaluation due to expensive data acquisition and calibration costs. In this paper, we propose a large-scale outdoor multi-modal dataset, OMMO dataset, containing complex land objects and scenes with calibrated images, point clouds and prompt annotations. Meanwhile, a new benchmark for several outdoor NeRF-based tasks is established, such as novel view synthesis, surface reconstruction, and multi-modal NeRF. To create the dataset, we capture and collect a large number of real fly-view videos and select high-quality and high-resolution clips from them. Then we design a quality review module to refine images, remove low-quality frames and fail-to-calibrate scenes through a learning-based automatic evaluation plus manual review. Finally, a number of volunteers are employed to add the text descriptions for each scene and key-frame to meet the potential multi-modal requirements in the future. Compared with existing NeRF datasets, our dataset contains abundant real-world urban and natural scenes with various scales, camera trajectories, and lighting conditions. Experiments show that our dataset can benchmark most state-of-the-art NeRF methods on different tasks. We will release the dataset and model weights very soon.