 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAS: Segment Any 3D Scene with Integrated 2D Priors
Mar 11, 2025The open vocabulary capability of 3D models is increasingly valued, as traditional methods with models trained with fixed categories fail to recognize unseen objects in complex dynamic 3D scenes. In this paper, we propose a simple yet effective approach, SAS, to integrate the open vocabulary capability of multiple 2D models and migrate it to 3D domain. Specifically, we first propose Model Alignment via Text to map different 2D models into the same embedding space using text as a bridge. Then, we propose Annotation-Free Model Capability Construction to explicitly quantify the 2D model's capability of recognizing different categories using diffusion models. Following this, point cloud features from different 2D models are fused with the guide of constructed model capabilities. Finally, the integrated 2D open vocabulary capability is transferred to 3D domain through feature distillation. SAS outperforms previous methods by a large margin across multiple datasets, including ScanNet v2, Matterport3D, and nuScenes, while its generalizability is further validated on downstream tasks, e.g., gaussian segmentation and instance segmentation.
Active Learning for Conditional Inverse Design with Crystal Generation and Foundation Atomic Models
Feb 24, 2025Artificial intelligence (AI) is transforming materials science, enabling both theoretical advancements and accelerated materials discovery. Recent progress in crystal generation models, which design crystal structures for targeted properties, and foundation atomic models (FAMs), which capture interatomic interactions across the periodic table, has significantly improved inverse materials design. However, an efficient integration of these two approaches remains an open challenge. Here, we present an active learning framework that combines crystal generation models and foundation atomic models to enhance the accuracy and efficiency of inverse design. As a case study, we employ Con-CDVAE to generate candidate crystal structures and MACE-MP-0 FAM as one of the high-throughput screeners for bulk modulus evaluation. Through iterative active learning, we demonstrate that Con-CDVAE progressively improves its accuracy in generating crystals with target properties, highlighting the effectiveness of a property-driven fine-tuning process. Our framework is general to accommodate different crystal generation and foundation atomic models, and establishes a scalable approach for AI-driven materials discovery. By bridging generative modeling with atomic-scale simulations, this work paves the way for more accurate and efficient inverse materials design.
Spend Wisely: Maximizing Post-Training Gains in Iterative Synthetic Data Boostrapping
Jan 31, 2025



Modern foundation models often undergo iterative ``bootstrapping'' in their post-training phase: a model generates synthetic data, an external verifier filters out low-quality samples, and the high-quality subset is used for further fine-tuning. Over multiple iterations, the model's performance improves--raising a crucial question: how should the total budget on generation and training be allocated across iterations to maximize final performance? In this work, we develop a theoretical framework to analyze budget allocation strategies. Specifically, we show that constant policies fail to converge with high probability, while increasing policies--particularly exponential growth policies--exhibit significant theoretical advantages. Experiments on image denoising with diffusion probabilistic models and math reasoning with large language models show that both exponential and polynomial growth policies consistently outperform constant policies, with exponential policies often providing more stable performance.
Mitigating Tail Narrowing in LLM Self-Improvement via Socratic-Guided Sampling
Nov 01, 2024Self-improvement methods enable large language models (LLMs) to generate solutions themselves and iteratively train on filtered, high-quality rationales. This process proves effective and reduces the reliance on human supervision in LLMs' reasoning, but the performance soon plateaus. We delve into the process and find that models tend to over-sample on easy queries and under-sample on queries they have yet to master. As iterations proceed, this imbalance in sampling is exacerbated, leading to a long-tail distribution where solutions to difficult queries almost diminish. This phenomenon limits the performance gain of self-improving models. A straightforward solution is brute-force sampling to balance the distribution, which significantly raises computational costs. In this paper, we introduce Guided Self-Improvement (GSI), a strategy aimed at improving the efficiency of sampling challenging heavy-tailed data. It leverages Socratic-style guidance signals to help LLM reasoning with complex queries, reducing the exploration effort and minimizing computational overhead. Experiments on four models across diverse mathematical tasks show that GSI strikes a balance between performance and efficiency, while also being effective on held-out tasks.
USTC-TD: A Test Dataset and Benchmark for Image and Video Coding in 2020s
Sep 13, 2024



Image/video coding has been a remarkable research area for both academia and industry for many years. Testing datasets, especially high-quality image/video datasets are desirable for the justified evaluation of coding-related research, practical applications, and standardization activities. We put forward a test dataset namely USTC-TD, which has been successfully adopted in the practical end-to-end image/video coding challenge of the IEEE International Conference on Visual Communications and Image Processing in 2022 and 2023. USTC-TD contains 40 images at 4K spatial resolution and 10 video sequences at 1080p spatial resolution, featuring various content due to the diverse environmental factors (scene type, texture, motion, view) and the designed imaging factors (illumination, shadow, lens). We quantitatively evaluate USTC-TD on different image/video features (spatial, temporal, color, lightness), and compare it with the previous image/video test datasets, which verifies the wider coverage and more diversity of the proposed dataset. We also evaluate both classic standardized and recent learned image/video coding schemes on USTC-TD with PSNR and MS-SSIM, and provide an extensive benchmark for the evaluated schemes. Based on the characteristics and specific design of the proposed test dataset, we analyze the benchmark performance and shed light on the future research and development of image/video coding. All the data are released online: https://esakak.github.io/USTC-TD.
State-observation augmented diffusion model for nonlinear assimilation
Jul 31, 2024Data assimilation has become a crucial technique aiming to combine physical models with observational data to estimate state variables. Traditional assimilation algorithms often face challenges of high nonlinearity brought by both the physical and observational models. In this work, we propose a novel data-driven assimilation algorithm based on generative models to address such concerns. Our State-Observation Augmented Diffusion (SOAD) model is designed to handle nonlinear physical and observational models more effectively. The marginal posterior associated with SOAD has been derived and then proved to match the real posterior under mild assumptions, which shows theoretical superiority over previous score-based assimilation works. Experimental results also indicate that our SOAD model may offer improved accuracy over existing data-driven methods.
Uniformly Accelerated Motion Model for Inter Prediction
Jul 16, 2024



Inter prediction is a key technology to reduce the temporal redundancy in video coding. In natural videos, there are usually multiple moving objects with variable velocity, resulting in complex motion fields that are difficult to represent compactly. In Versatile Video Coding (VVC), existing inter prediction methods usually assume uniform speed motion between consecutive frames and use the linear models for motion estimation (ME) and motion compensation (MC), which may not well handle the complex motion fields in the real world. To address these issues, we introduce a uniformly accelerated motion model (UAMM) to exploit motion-related elements (velocity, acceleration) of moving objects between the video frames, and further combine them to assist the inter prediction methods to handle the variable motion in the temporal domain. Specifically, first, the theory of UAMM is mentioned. Second, based on that, we propose the UAMM-based parameter derivation and extrapolation schemes in the coding process. Third, we integrate the UAMM into existing inter prediction modes (Merge, MMVD, CIIP) to achieve higher prediction accuracy. The proposed method is implemented into the VVC reference software, VTM version 12.0. Experimental results show that the proposed method achieves up to 0.38% and on average 0.13% BD-rate reduction compared to the VTM anchor, under the Low-delay P configuration, with a slight increase of time complexity on the encoding/decoding side.
In-Loop Filtering via Trained Look-Up Tables
Jul 15, 2024In-loop filtering (ILF) is a key technology for removing the artifacts in image/video coding standards. Recently, neural network-based in-loop filtering methods achieve remarkable coding gains beyond the capability of advanced video coding standards, which becomes a powerful coding tool candidate for future video coding standards. However, the utilization of deep neural networks brings heavy time and computational complexity, and high demands of high-performance hardware, which is challenging to apply to the general uses of coding scene. To address this limitation, inspired by explorations in image restoration, we propose an efficient and practical in-loop filtering scheme by adopting the Look-up Table (LUT). We train the DNN of in-loop filtering within a fixed filtering reference range, and cache the output values of the DNN into a LUT via traversing all possible inputs. At testing time in the coding process, the filtered pixel is generated by locating input pixels (to-be-filtered pixel with reference pixels) and interpolating cached filtered pixel values. To further enable the large filtering reference range with the limited storage cost of LUT, we introduce the enhanced indexing mechanism in the filtering process, and clipping/finetuning mechanism in the training. The proposed method is implemented into the Versatile Video Coding (VVC) reference software, VTM-11.0. Experimental results show that the ultrafast, very fast, and fast mode of the proposed method achieves on average 0.13%/0.34%/0.51%, and 0.10%/0.27%/0.39% BD-rate reduction, under the all intra (AI) and random access (RA) configurations. Especially, our method has friendly time and computational complexity, only 101%/102%-104%/108% time increase with 0.13-0.93 kMACs/pixel, and only 164-1148 KB storage cost for a single model. Our solution may shed light on the journey of practical neural network-based coding tool evolution.
IVCA: Inter-Relation-Aware Video Complexity Analyzer
Jun 29, 2024


To meet the real-time analysis requirements of video streaming applications, we propose an inter-relation-aware video complexity analyzer (IVCA) as an extension to VCA. The IVCA addresses the limitation of VCA by considering inter-frame relations, namely motion and reference structure. First, we enhance the accuracy of temporal features by introducing feature-domain motion estimation into the IVCA. Next, drawing inspiration from the hierarchical reference structure in codecs, we design layer-aware weights to adjust the majorities of frame complexity in different layers. Additionally, we expand the scope of temporal features by considering frames that be referred to, rather than relying solely on the previous frame. Experimental results show the significant improvement in complexity estimation accuracy achieved by IVCA, with minimal time complexity increase.
Mamba24/8D: Enhancing Global Interaction in Point Clouds via State Space Model
Jun 25, 2024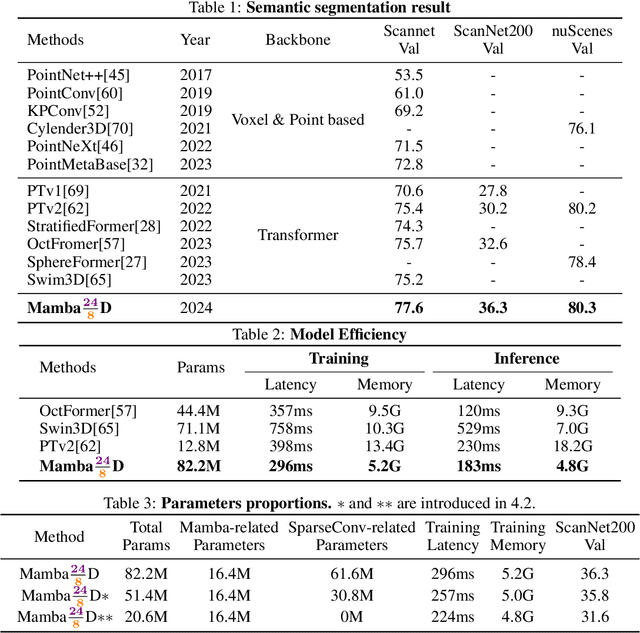
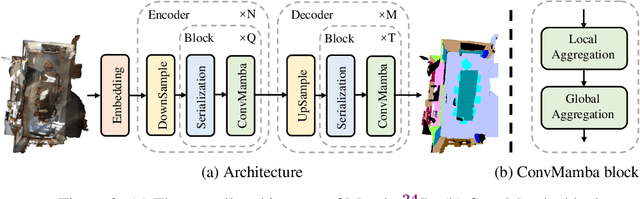
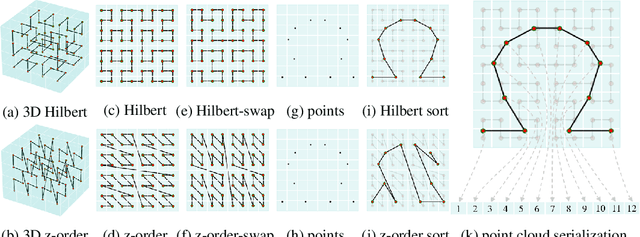
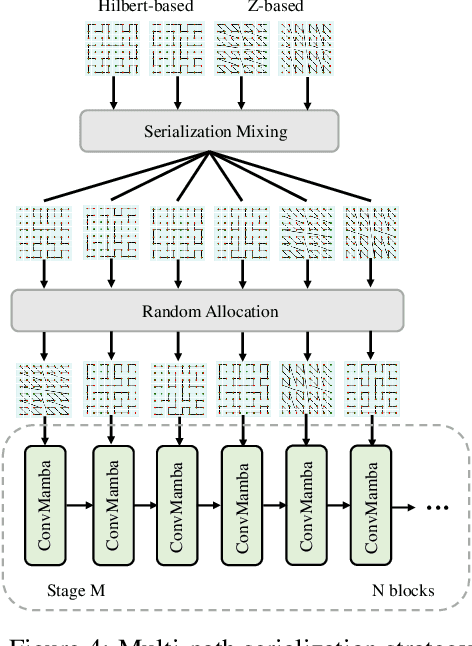
Transformers have demonstrated impressive results for 3D point cloud semantic segmentation. However, the quadratic complexity of transformer makes computation cost high, limiting the number of points that can be processed simultaneously and impeding the modeling of long-range dependencies. Drawing inspiration from the great potential of recent state space models (SSM) for long sequence modeling, we introduce Mamba, a SSM-based architecture, to the point cloud domain and propose Mamba24/8D, which has strong global modeling capability under linear complexity. Specifically, to make disorderness of point clouds fit in with the causal nature of Mamba, we propose a multi-path serialization strategy applicable to point clouds. Besides, we propose the ConvMamba block to compensate for the shortcomings of Mamba in modeling local geometries and in unidirectional modeling. Mamba24/8D obtains state of the art results on several 3D point cloud segmentation tasks, including ScanNet v2, ScanNet200 and nuScenes, while its effectiveness is validated by extensive experiments.