 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFlow: Self-correction Motion Learning for Dynamic Scene Reconstruction
Apr 02, 2026We present ReFlow, a unified framework for monocular dynamic scene reconstruction that learns 3D motion in a novel self-correction manner from raw video. Existing methods often suffer from incomplete scene initialization for dynamic regions, leading to unstable reconstruction and motion estimation, which often resorts to external dense motion guidance such as pre-computed optical flow to further stabilize and constrain the reconstruction of dynamic components. However, this introduces additional complexity and potential error propagation. To address these issues, ReFlow integrates a Complete Canonical Space Construction module for enhanced initialization of both static and dynamic regions, and a Separation-Based Dynamic Scene Modeling module that decouples static and dynamic components for targeted motion supervision. The core of ReFlow is a novel self-correction flow matching mechanism, consisting of Full Flow Matching to align 3D scene flow with time-varying 2D observations, and Camera Flow Matching to enforce multi-view consistency for static objects. Together, these modules enable robust and accurate dynamic scene reconstruction. Extensive experiments across diverse scenarios demonstrate that ReFlow achieves superior reconstruction quality and robustness, establishing a novel self-correction paradigm for monocular 4D reconstruction.
MeshSplat: Generalizable Sparse-View Surface Reconstruction via Gaussian Splatting
Aug 25, 2025Surface reconstruction has been widely studied in computer vision and graphics. However, existing surface reconstruction works struggle to recover accurate scene geometry when the input views are extremely sparse. To address this issue, we propose MeshSplat, a generalizable sparse-view surface reconstruction framework via Gaussian Splatting. Our key idea is to leverage 2DGS as a bridge, which connects novel view synthesis to learned geometric priors and then transfers these priors to achieve surface reconstruction. Specifically, we incorporate a feed-forward network to predict per-view pixel-aligned 2DGS, which enables the network to synthesize novel view images and thus eliminates the need for direct 3D ground-truth supervision. To improve the accuracy of 2DGS position and orientation prediction, we propose a Weighted Chamfer Distance Loss to regularize the depth maps, especially in overlapping areas of input views, and also a normal prediction network to align the orientation of 2DGS with normal vectors predicted by a monocular normal estimator. Extensive experiments validate the effectiveness of our proposed improvement, demonstrating that our method achieves state-of-the-art performance in generalizable sparse-view mesh reconstruction tasks. Project Page: https://hanzhichang.github.io/meshsplat_web
SAS: Segment Any 3D Scene with Integrated 2D Priors
Mar 11, 2025



The open vocabulary capability of 3D models is increasingly valued, as traditional methods with models trained with fixed categories fail to recognize unseen objects in complex dynamic 3D scenes. In this paper, we propose a simple yet effective approach, SAS, to integrate the open vocabulary capability of multiple 2D models and migrate it to 3D domain. Specifically, we first propose Model Alignment via Text to map different 2D models into the same embedding space using text as a bridge. Then, we propose Annotation-Free Model Capability Construction to explicitly quantify the 2D model's capability of recognizing different categories using diffusion models. Following this, point cloud features from different 2D models are fused with the guide of constructed model capabilities. Finally, the integrated 2D open vocabulary capability is transferred to 3D domain through feature distillation. SAS outperforms previous methods by a large margin across multiple datasets, including ScanNet v2, Matterport3D, and nuScenes, while its generalizability is further validated on downstream tasks, e.g., gaussian segmentation and instance segmentation.
DN-4DGS: Denoised Deformable Network with Temporal-Spatial Aggregation for Dynamic Scene Rendering
Oct 17, 2024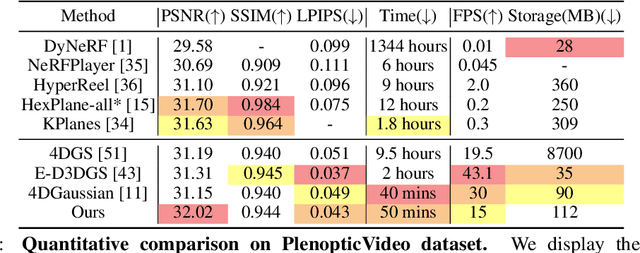

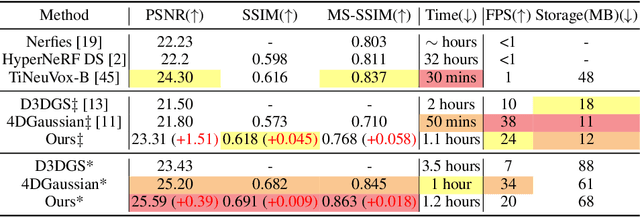

Dynamic scenes rendering is an intriguing yet challenging problem. Although current methods based on NeRF have achieved satisfactory performance, they still can not reach real-time levels. Recently, 3D Gaussian Splatting (3DGS) has gar?nered researchers attention due to their outstanding rendering quality and real?time speed. Therefore, a new paradigm has been proposed: defining a canonical 3D gaussians and deforming it to individual frames in deformable fields. How?ever, since the coordinates of canonical 3D gaussians are filled with noise, which can transfer noise into the deformable fields, and there is currently no method that adequately considers the aggregation of 4D information. Therefore, we pro?pose Denoised Deformable Network with Temporal-Spatial Aggregation for Dy?namic Scene Rendering (DN-4DGS). Specifically, a Noise Suppression Strategy is introduced to change the distribution of the coordinates of the canonical 3D gaussians and suppress noise. Additionally, a Decoupled Temporal-Spatial Ag?gregation Module is designed to aggregate information from adjacent points and frames. Extensive experiments on various real-world datasets demonstrate that our method achieves state-of-the-art rendering quality under a real-time level.
MotionGS: Exploring Explicit Motion Guidance for Deformable 3D Gaussian Splatting
Oct 10, 2024



Dynamic scene reconstruction is a long-term challenge in the field of 3D vision. Recently, the emergence of 3D Gaussian Splatting has provided new insights into this problem. Although subsequent efforts rapidly extend static 3D Gaussian to dynamic scenes, they often lack explicit constraints on object motion, leading to optimization difficulties and performance degradation. To address the above issues, we propose a novel deformable 3D Gaussian splatting framework called MotionGS, which explores explicit motion priors to guide the deformation of 3D Gaussians. Specifically, we first introduce an optical flow decoupling module that decouples optical flow into camera flow and motion flow, corresponding to camera movement and object motion respectively. Then the motion flow can effectively constrain the deformation of 3D Gaussians, thus simulating the motion of dynamic objects. Additionally, a camera pose refinement module is proposed to alternately optimize 3D Gaussians and camera poses, mitigating the impact of inaccurate camera poses. Extensive experiments in the monocular dynamic scenes validate that MotionGS surpasses state-of-the-art methods and exhibits significant superiority in both qualitative and quantitative results. Project page: https://ruijiezhu94.github.io/MotionGS_page
Mamba24/8D: Enhancing Global Interaction in Point Clouds via State Space Model
Jun 25, 2024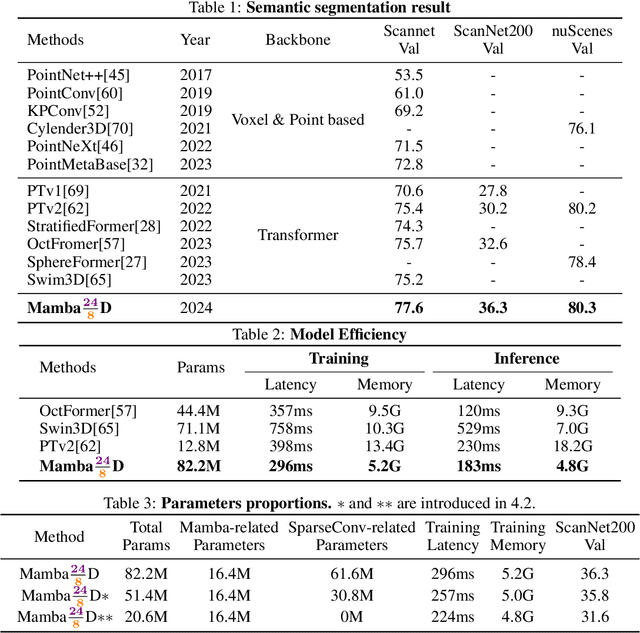
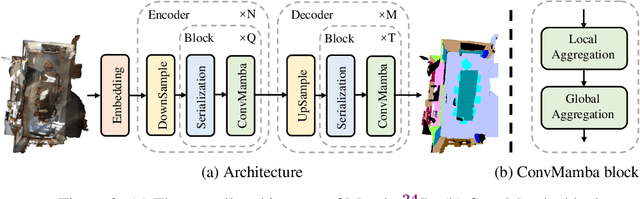
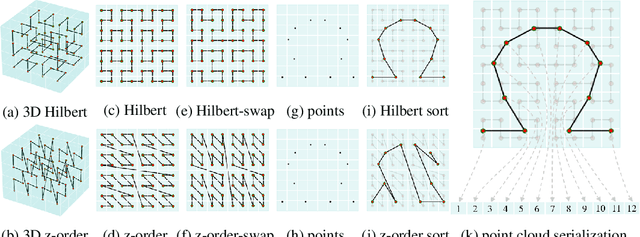
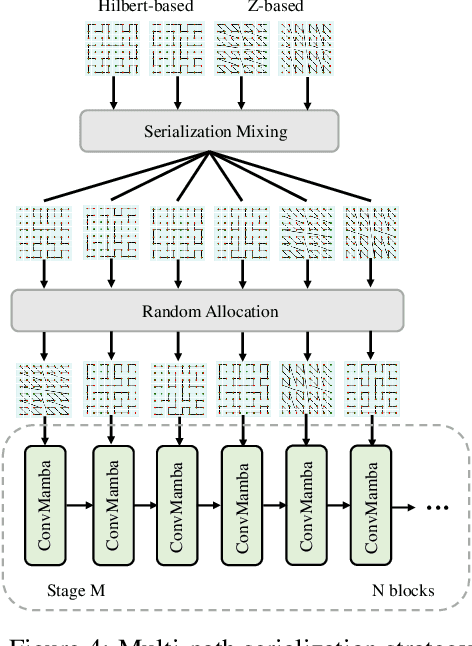
Transformers have demonstrated impressive results for 3D point cloud semantic segmentation. However, the quadratic complexity of transformer makes computation cost high, limiting the number of points that can be processed simultaneously and impeding the modeling of long-range dependencies. Drawing inspiration from the great potential of recent state space models (SSM) for long sequence modeling, we introduce Mamba, a SSM-based architecture, to the point cloud domain and propose Mamba24/8D, which has strong global modeling capability under linear complexity. Specifically, to make disorderness of point clouds fit in with the causal nature of Mamba, we propose a multi-path serialization strategy applicable to point clouds. Besides, we propose the ConvMamba block to compensate for the shortcomings of Mamba in modeling local geometries and in unidirectional modeling. Mamba24/8D obtains state of the art results on several 3D point cloud segmentation tasks, including ScanNet v2, ScanNet200 and nuScenes, while its effectiveness is validated by extensive experiments.