 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba24/8D: Enhancing Global Interaction in Point Clouds via State Space Model
Jun 25, 2024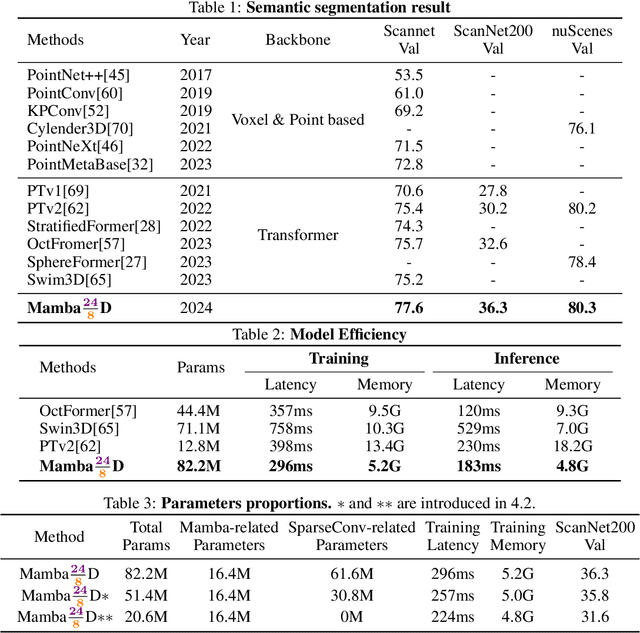
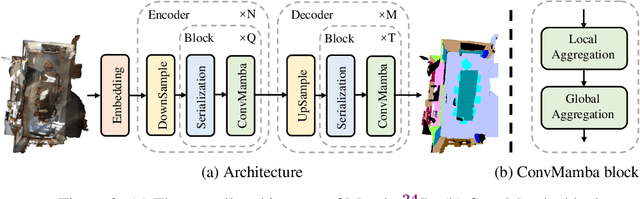
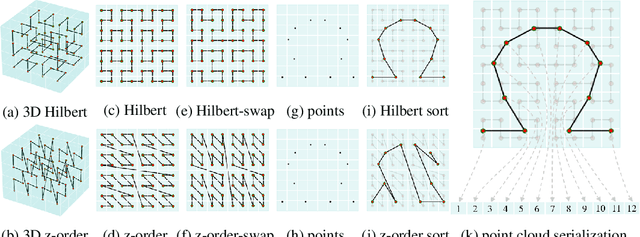
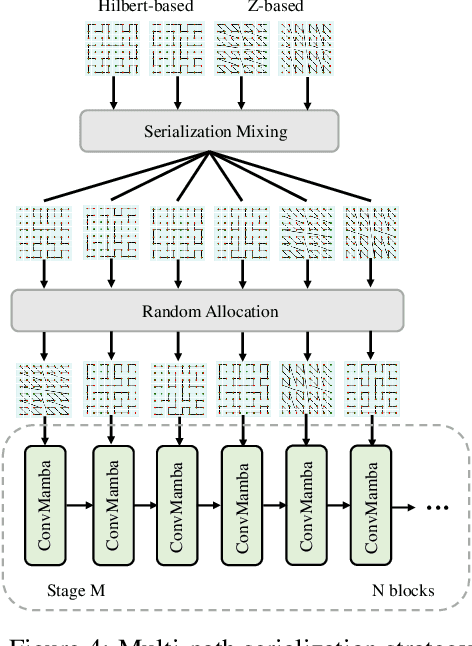
Transformers have demonstrated impressive results for 3D point cloud semantic segmentation. However, the quadratic complexity of transformer makes computation cost high, limiting the number of points that can be processed simultaneously and impeding the modeling of long-range dependencies. Drawing inspiration from the great potential of recent state space models (SSM) for long sequence modeling, we introduce Mamba, a SSM-based architecture, to the point cloud domain and propose Mamba24/8D, which has strong global modeling capability under linear complexity. Specifically, to make disorderness of point clouds fit in with the causal nature of Mamba, we propose a multi-path serialization strategy applicable to point clouds. Besides, we propose the ConvMamba block to compensate for the shortcomings of Mamba in modeling local geometries and in unidirectional modeling. Mamba24/8D obtains state of the art results on several 3D point cloud segmentation tasks, including ScanNet v2, ScanNet200 and nuScenes, while its effectiveness is validated by extensive experiments.
Not Every Side Is Equal: Localization Uncertainty Estimation for Semi-Supervised 3D Object Detection
Dec 16, 2023Semi-supervised 3D object detection from point cloud aims to train a detector with a small number of labeled data and a large number of unlabeled data. The core of existing methods lies in how to select high-quality pseudo-labels using the designed quality evaluation criterion. However, these methods treat each pseudo bounding box as a whole and assign equal importance to each side during training, which is detrimental to model performance due to many sides having poor localization quality. Besides, existing methods filter out a large number of low-quality pseudo-labels, which also contain some correct regression values that can help with model training. To address the above issues, we propose a side-aware framework for semi-supervised 3D object detection consisting of three key designs: a 3D bounding box parameterization method, an uncertainty estimation module, and a pseudo-label selection strategy. These modules work together to explicitly estimate the localization quality of each side and assign different levels of importance during the training phase. Extensive experiment results demonstrate that the proposed method can consistently outperform baseline models under different scenes and evaluation criteria. Moreover, our method achieves state-of-the-art performance on three datasets with different labeled ratios.