 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrackingWorld: World-centric Monocular 3D Tracking of Almost All Pixels
Dec 09, 2025Monocular 3D tracking aims to capture the long-term motion of pixels in 3D space from a single monocular video and has witnessed rapid progress in recent years. However, we argue that the existing monocular 3D tracking methods still fall short in separating the camera motion from foreground dynamic motion and cannot densely track newly emerging dynamic subjects in the videos. To address these two limitations, we propose TrackingWorld, a novel pipeline for dense 3D tracking of almost all pixels within a world-centric 3D coordinate system. First, we introduce a tracking upsampler that efficiently lifts the arbitrary sparse 2D tracks into dense 2D tracks. Then, to generalize the current tracking methods to newly emerging objects, we apply the upsampler to all frames and reduce the redundancy of 2D tracks by eliminating the tracks in overlapped regions. Finally, we present an efficient optimization-based framework to back-project dense 2D tracks into world-centric 3D trajectories by estimating the camera poses and the 3D coordinates of these 2D tracks. Extensive evaluations on both synthetic and real-world datasets demonstrate that our system achieves accurate and dense 3D tracking in a world-centric coordinate frame.
Adaptive Agent Selection and Interaction Network for Image-to-point cloud Registration
Nov 08, 2025Typical detection-free methods for image-to-point cloud registration leverage transformer-based architectures to aggregate cross-modal features and establish correspondences. However, they often struggle under challenging conditions, where noise disrupts similarity computation and leads to incorrect correspondences. Moreover, without dedicated designs, it remains difficult to effectively select informative and correlated representations across modalities, thereby limiting the robustness and accuracy of registration. To address these challenges, we propose a novel cross-modal registration framework composed of two key modules: the Iterative Agents Selection (IAS) module and the Reliable Agents Interaction (RAI) module. IAS enhances structural feature awareness with phase maps and employs reinforcement learning principles to efficiently select reliable agents. RAI then leverages these selected agents to guide cross-modal interactions, effectively reducing mismatches and improving overall robustness. Extensive experiments on the RGB-D Scenes v2 and 7-Scenes benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
CA-I2P: Channel-Adaptive Registration Network with Global Optimal Selection
Jun 26, 2025Detection-free methods typically follow a coarse-to-fine pipeline, extracting image and point cloud features for patch-level matching and refining dense pixel-to-point correspondences. However, differences in feature channel attention between images and point clouds may lead to degraded matching results, ultimately impairing registration accuracy. Furthermore, similar structures in the scene could lead to redundant correspondences in cross-modal matching. To address these issues, we propose Channel Adaptive Adjustment Module (CAA) and Global Optimal Selection Module (GOS). CAA enhances intra-modal features and suppresses cross-modal sensitivity, while GOS replaces local selection with global optimization. Experiments on RGB-D Scenes V2 and 7-Scenes demonstrate the superiority of our method, achieving state-of-the-art performance in image-to-point cloud registration.
Bridge 2D-3D: Uncertainty-aware Hierarchical Registration Network with Domain Alignment
Apr 02, 2025The method for image-to-point cloud registration typically determines the rigid transformation using a coarse-to-fine pipeline. However, directly and uniformly matching image patches with point cloud patches may lead to focusing on incorrect noise patches during matching while ignoring key ones. Moreover, due to the significant differences between image and point cloud modalities, it may be challenging to bridge the domain gap without specific improvements in design. To address the above issues, we innovatively propose the Uncertainty-aware Hierarchical Matching Module (UHMM) and the Adversarial Modal Alignment Module (AMAM). Within the UHMM, we model the uncertainty of critical information in image patches and facilitate multi-level fusion interactions between image and point cloud features. In the AMAM, we design an adversarial approach to reduce the domain gap between image and point cloud. Extensive experiments and ablation studies on RGB-D Scene V2 and 7-Scenes benchmarks demonstrate the superiority of our method, making it a state-of-the-art approach for image-to-point cloud registration tasks.
SAS: Segment Any 3D Scene with Integrated 2D Priors
Mar 11, 2025



The open vocabulary capability of 3D models is increasingly valued, as traditional methods with models trained with fixed categories fail to recognize unseen objects in complex dynamic 3D scenes. In this paper, we propose a simple yet effective approach, SAS, to integrate the open vocabulary capability of multiple 2D models and migrate it to 3D domain. Specifically, we first propose Model Alignment via Text to map different 2D models into the same embedding space using text as a bridge. Then, we propose Annotation-Free Model Capability Construction to explicitly quantify the 2D model's capability of recognizing different categories using diffusion models. Following this, point cloud features from different 2D models are fused with the guide of constructed model capabilities. Finally, the integrated 2D open vocabulary capability is transferred to 3D domain through feature distillation. SAS outperforms previous methods by a large margin across multiple datasets, including ScanNet v2, Matterport3D, and nuScenes, while its generalizability is further validated on downstream tasks, e.g., gaussian segmentation and instance segmentation.
Beyond the Final Layer: Hierarchical Query Fusion Transformer with Agent-Interpolation Initialization for 3D Instance Segmentation
Feb 06, 2025



3D instance segmentation aims to predict a set of object instances in a scene and represent them as binary foreground masks with corresponding semantic labels. Currently, transformer-based methods are gaining increasing attention due to their elegant pipelines, reduced manual selection of geometric properties, and superior performance. However, transformer-based methods fail to simultaneously maintain strong position and content information during query initialization. Additionally, due to supervision at each decoder layer, there exists a phenomenon of object disappearance with the deepening of layers. To overcome these hurdles, we introduce Beyond the Final Layer: Hierarchical Query Fusion Transformer with Agent-Interpolation Initialization for 3D Instance Segmentation (BFL). Specifically, an Agent-Interpolation Initialization Module is designed to generate resilient queries capable of achieving a balance between foreground coverage and content learning. Additionally, a Hierarchical Query Fusion Decoder is designed to retain low overlap queries, mitigating the decrease in recall with the deepening of layers. Extensive experiments on ScanNetV2, ScanNet200, ScanNet++ and S3DIS datasets demonstrate the superior performance of BFL.
ErasableMask: A Robust and Erasable Privacy Protection Scheme against Black-box Face Recognition Models
Dec 24, 2024



While face recognition (FR) models have brought remarkable convenience in face verification and identification, they also pose substantial privacy risks to the public. Existing facial privacy protection schemes usually adopt adversarial examples to disrupt face verification of FR models. However, these schemes often suffer from weak transferability against black-box FR models and permanently damage the identifiable information that cannot fulfill the requirements of authorized operations such as forensics and authentication. To address these limitations, we propose ErasableMask, a robust and erasable privacy protection scheme against black-box FR models. Specifically, via rethinking the inherent relationship between surrogate FR models, ErasableMask introduces a novel meta-auxiliary attack, which boosts black-box transferability by learning more general features in a stable and balancing optimization strategy. It also offers a perturbation erasion mechanism that supports the erasion of semantic perturbations in protected face without degrading image quality. To further improve performance, ErasableMask employs a curriculum learning strategy to mitigate optimization conflicts between adversarial attack and perturbation erasion. Extensive experiments on the CelebA-HQ and FFHQ datasets demonstrate that ErasableMask achieves the state-of-the-art performance in transferability, achieving over 72% confidence on average in commercial FR systems. Moreover, ErasableMask also exhibits outstanding perturbation erasion performance, achieving over 90% erasion success rate.
Three-in-One: Robust Enhanced Universal Transferable Anti-Facial Retrieval in Online Social Networks
Dec 23, 2024



Deep hash-based retrieval techniques are widely used in facial retrieval systems to improve the efficiency of facial matching. However, it also carries the danger of exposing private information. Deep hash models are easily influenced by adversarial examples, which can be leveraged to protect private images from malicious retrieval. The existing adversarial example methods against deep hash models focus on universality and transferability, lacking the research on its robustness in online social networks (OSNs), which leads to their failure in anti-retrieval after post-processing. Therefore, we provide the first in-depth discussion on robustness adversarial perturbation in universal transferable anti-facial retrieval and propose Three-in-One Adversarial Perturbation (TOAP). Specifically, we construct a local and global Compression Generator (CG) to simulate complex post-processing scenarios, which can be used to mitigate perturbation. Then, we propose robust optimization objectives based on the discovery of the variation patterns of model's distribution after post-processing, and generate adversarial examples using these objectives and meta-learning. Finally, we iteratively optimize perturbation by alternately generating adversarial examples and fine-tuning the CG, balancing the performance of perturbation while enhancing CG's ability to mitigate them. Numerous experiments demonstrate that, in addition to its advantages in universality and transferability, TOAP significantly outperforms current state-of-the-art methods in multiple robustness metrics. It further improves universality and transferability by 5% to 28%, and achieves up to about 33% significant improvement in several simulated post-processing scenarios as well as mainstream OSNs, demonstrating that TOAP can effectively protect private images from malicious retrieval in real-world scenarios.
TOAP: Towards Better Robustness in Universal Transferable Anti-Facial Retrieval
Dec 12, 2024Deep hash-based retrieval techniques are widely used in facial retrieval systems to improve the efficiency of facial matching. However, it also brings the risk of privacy leakage. Deep hash models are easily influenced by adversarial examples, which can be leveraged to prevent the malicious retrieval of private images. The existing adversarial example methods against deep hash models focus on universality and transferability, lacking the research on its robustness in online social networks (OSNs), which leads to their failure in anti-retrieval after post-processing. Therefore, we provide the first in-depth discussion on robustness adversarial perturbation in universal transferable anti-facial retrieval and propose Three-in-One Adversarial Perturbation (TOAP). Specifically, we firstly analyze the performance of deep hash models after post-processing and construct a local and global Compression Generator (CG) to simulate complex post-processing scenarios. Then, we explore the variation patterns of the model's objective under image post-processing and propose robust optimization objectives, cluster centers and data space centers, optimizing them using meta-learning. Finally, we iteratively optimize perturbation by alternately generating adversarial examples and fine-tuning the CG, balancing the performance of perturbation while enhancing CG's ability to mitigate them. Numerous experiments demonstrate that, in addition to its advantages in universality and transferability, TOAP significantly outperforms current state-of-the-art methods in multiple robustness metrics. It further improves universality and transferability by 5% to 28%, and achieves up to about 33% significant improvement in several simulated post-processing scenarios as well as mainstream OSNs, demonstrating that TOAP can effectively protect private images from malicious retrieval in real-world scenarios.
Take Fake as Real: Realistic-like Robust Black-box Adversarial Attack to Evade AIGC Detection
Dec 09, 2024


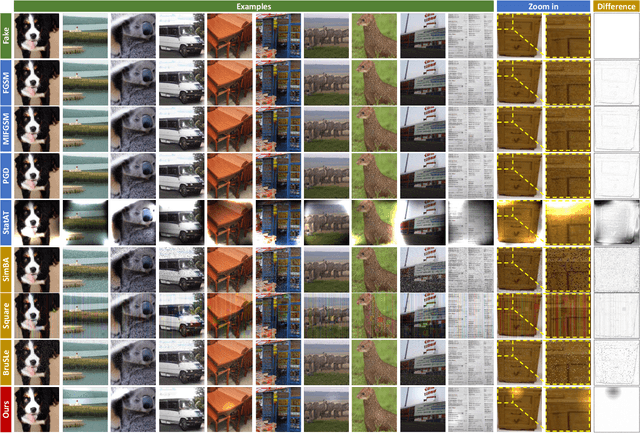
The security of AI-generated content (AIGC) detection based on GANs and diffusion models is closely related to the credibility of multimedia content. Malicious adversarial attacks can evade these developing AIGC detection. However, most existing adversarial attacks focus only on GAN-generated facial images detection, struggle to be effective on multi-class natural images and diffusion-based detectors, and exhibit poor invisibility. To fill this gap, we first conduct an in-depth analysis of the vulnerability of AIGC detectors and discover the feature that detectors vary in vulnerability to different post-processing. Then, considering the uncertainty of detectors in real-world scenarios, and based on the discovery, we propose a Realistic-like Robust Black-box Adversarial attack (R$^2$BA) with post-processing fusion optimization. Unlike typical perturbations, R$^2$BA uses real-world post-processing, i.e., Gaussian blur, JPEG compression, Gaussian noise and light spot to generate adversarial examples. Specifically, we use a stochastic particle swarm algorithm with inertia decay to optimize post-processing fusion intensity and explore the detector's decision boundary. Guided by the detector's fake probability, R$^2$BA enhances/weakens the detector-vulnerable/detector-robust post-processing intensity to strike a balance between adversariality and invisibility. Extensive experiments on popular/commercial AIGC detectors and datasets demonstrate that R$^2$BA exhibits impressive anti-detection performance, excellent invisibility, and strong robustness in GAN-based and diffusion-based cases. Compared to state-of-the-art white-box and black-box attacks, R$^2$BA shows significant improvements of 15% and 21% in anti-detection performance under the original and robust scenario respectively, offering valuable insights for the security of AIGC detection in real-world applications.