 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake the Most of Everything: Further Considerations on Disrupting Diffusion-based Customization
Mar 18, 2025The fine-tuning technique for text-to-image diffusion models facilitates image customization but risks privacy breaches and opinion manipulation. Current research focuses on prompt- or image-level adversarial attacks for anti-customization, yet it overlooks the correlation between these two levels and the relationship between internal modules and inputs. This hinders anti-customization performance in practical threat scenarios. We propose Dual Anti-Diffusion (DADiff), a two-stage adversarial attack targeting diffusion customization, which, for the first time, integrates the adversarial prompt-level attack into the generation process of image-level adversarial examples. In stage 1, we generate prompt-level adversarial vectors to guide the subsequent image-level attack. In stage 2, besides conducting the end-to-end attack on the UNet model, we disrupt its self- and cross-attention modules, aiming to break the correlations between image pixels and align the cross-attention results computed using instance prompts and adversarial prompt vectors within the images. Furthermore, we introduce a local random timestep gradient ensemble strategy, which updates adversarial perturbations by integrating random gradients from multiple segmented timesets. Experimental results on various mainstream facial datasets demonstrate 10%-30% improvements in cross-prompt, keyword mismatch, cross-model, and cross-mechanism anti-customization with DADiff compared to existing methods.
Three-in-One: Robust Enhanced Universal Transferable Anti-Facial Retrieval in Online Social Networks
Dec 23, 2024



Deep hash-based retrieval techniques are widely used in facial retrieval systems to improve the efficiency of facial matching. However, it also carries the danger of exposing private information. Deep hash models are easily influenced by adversarial examples, which can be leveraged to protect private images from malicious retrieval. The existing adversarial example methods against deep hash models focus on universality and transferability, lacking the research on its robustness in online social networks (OSNs), which leads to their failure in anti-retrieval after post-processing. Therefore, we provide the first in-depth discussion on robustness adversarial perturbation in universal transferable anti-facial retrieval and propose Three-in-One Adversarial Perturbation (TOAP). Specifically, we construct a local and global Compression Generator (CG) to simulate complex post-processing scenarios, which can be used to mitigate perturbation. Then, we propose robust optimization objectives based on the discovery of the variation patterns of model's distribution after post-processing, and generate adversarial examples using these objectives and meta-learning. Finally, we iteratively optimize perturbation by alternately generating adversarial examples and fine-tuning the CG, balancing the performance of perturbation while enhancing CG's ability to mitigate them. Numerous experiments demonstrate that, in addition to its advantages in universality and transferability, TOAP significantly outperforms current state-of-the-art methods in multiple robustness metrics. It further improves universality and transferability by 5% to 28%, and achieves up to about 33% significant improvement in several simulated post-processing scenarios as well as mainstream OSNs, demonstrating that TOAP can effectively protect private images from malicious retrieval in real-world scenarios.
TOAP: Towards Better Robustness in Universal Transferable Anti-Facial Retrieval
Dec 12, 2024Deep hash-based retrieval techniques are widely used in facial retrieval systems to improve the efficiency of facial matching. However, it also brings the risk of privacy leakage. Deep hash models are easily influenced by adversarial examples, which can be leveraged to prevent the malicious retrieval of private images. The existing adversarial example methods against deep hash models focus on universality and transferability, lacking the research on its robustness in online social networks (OSNs), which leads to their failure in anti-retrieval after post-processing. Therefore, we provide the first in-depth discussion on robustness adversarial perturbation in universal transferable anti-facial retrieval and propose Three-in-One Adversarial Perturbation (TOAP). Specifically, we firstly analyze the performance of deep hash models after post-processing and construct a local and global Compression Generator (CG) to simulate complex post-processing scenarios. Then, we explore the variation patterns of the model's objective under image post-processing and propose robust optimization objectives, cluster centers and data space centers, optimizing them using meta-learning. Finally, we iteratively optimize perturbation by alternately generating adversarial examples and fine-tuning the CG, balancing the performance of perturbation while enhancing CG's ability to mitigate them. Numerous experiments demonstrate that, in addition to its advantages in universality and transferability, TOAP significantly outperforms current state-of-the-art methods in multiple robustness metrics. It further improves universality and transferability by 5% to 28%, and achieves up to about 33% significant improvement in several simulated post-processing scenarios as well as mainstream OSNs, demonstrating that TOAP can effectively protect private images from malicious retrieval in real-world scenarios.
Take Fake as Real: Realistic-like Robust Black-box Adversarial Attack to Evade AIGC Detection
Dec 09, 2024


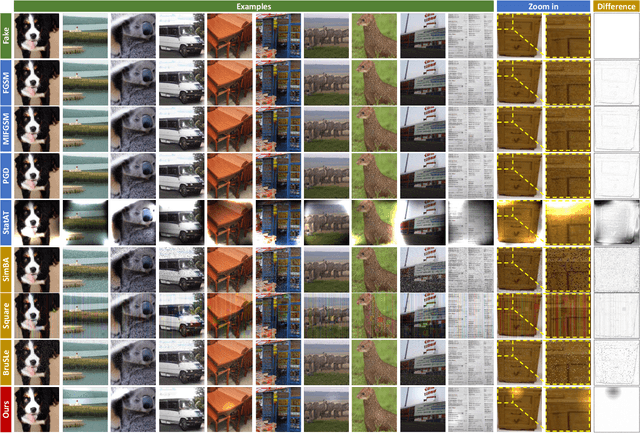
The security of AI-generated content (AIGC) detection based on GANs and diffusion models is closely related to the credibility of multimedia content. Malicious adversarial attacks can evade these developing AIGC detection. However, most existing adversarial attacks focus only on GAN-generated facial images detection, struggle to be effective on multi-class natural images and diffusion-based detectors, and exhibit poor invisibility. To fill this gap, we first conduct an in-depth analysis of the vulnerability of AIGC detectors and discover the feature that detectors vary in vulnerability to different post-processing. Then, considering the uncertainty of detectors in real-world scenarios, and based on the discovery, we propose a Realistic-like Robust Black-box Adversarial attack (R$^2$BA) with post-processing fusion optimization. Unlike typical perturbations, R$^2$BA uses real-world post-processing, i.e., Gaussian blur, JPEG compression, Gaussian noise and light spot to generate adversarial examples. Specifically, we use a stochastic particle swarm algorithm with inertia decay to optimize post-processing fusion intensity and explore the detector's decision boundary. Guided by the detector's fake probability, R$^2$BA enhances/weakens the detector-vulnerable/detector-robust post-processing intensity to strike a balance between adversariality and invisibility. Extensive experiments on popular/commercial AIGC detectors and datasets demonstrate that R$^2$BA exhibits impressive anti-detection performance, excellent invisibility, and strong robustness in GAN-based and diffusion-based cases. Compared to state-of-the-art white-box and black-box attacks, R$^2$BA shows significant improvements of 15% and 21% in anti-detection performance under the original and robust scenario respectively, offering valuable insights for the security of AIGC detection in real-world applications.