 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Diffusion Priors via 3D Attention for Consistent Gaussian Splatting
Dec 16, 2025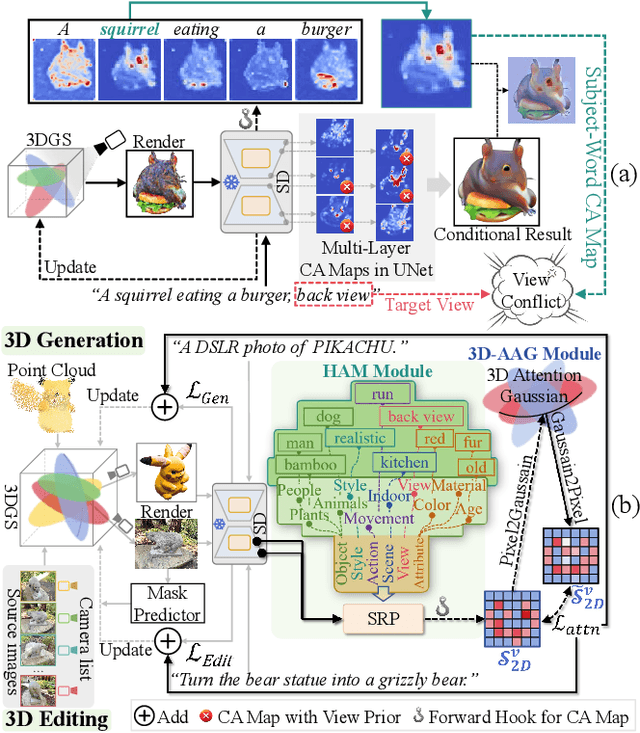
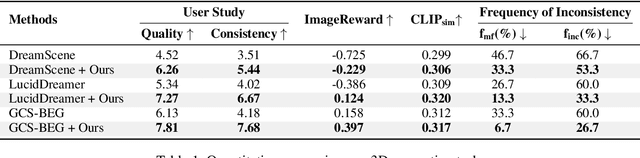

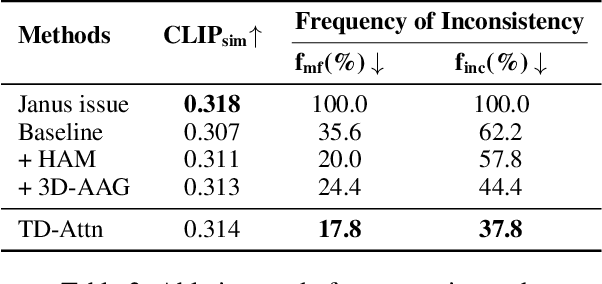
Versatile 3D tasks (e.g., generation or editing) that distill from Text-to-Image (T2I) diffusion models have attracted significant research interest for not relying on extensive 3D training data. However, T2I models exhibit limitations resulting from prior view bias, which produces conflicting appearances between different views of an object. This bias causes subject-words to preferentially activate prior view features during cross-attention (CA) computation, regardless of the target view condition. To overcome this limitation, we conduct a comprehensive mathematical analysis to reveal the root cause of the prior view bias in T2I models. Moreover, we find different UNet layers show different effects of prior view in CA. Therefore, we propose a novel framework, TD-Attn, which addresses multi-view inconsistency via two key components: (1) the 3D-Aware Attention Guidance Module (3D-AAG) constructs a view-consistent 3D attention Gaussian for subject-words to enforce spatial consistency across attention-focused regions, thereby compensating for the limited spatial information in 2D individual view CA maps; (2) the Hierarchical Attention Modulation Module (HAM) utilizes a Semantic Guidance Tree (SGT) to direct the Semantic Response Profiler (SRP) in localizing and modulating CA layers that are highly responsive to view conditions, where the enhanced CA maps further support the construction of more consistent 3D attention Gaussians. Notably, HAM facilitates semantic-specific interventions, enabling controllable and precise 3D editing. Extensive experiments firmly establish that TD-Attn has the potential to serve as a universal plugin, significantly enhancing multi-view consistency across 3D tasks.
ReaSon: Reinforced Causal Search with Information Bottleneck for Video Understanding
Nov 16, 2025
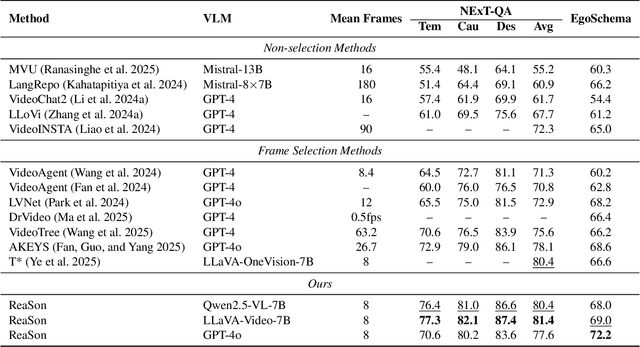
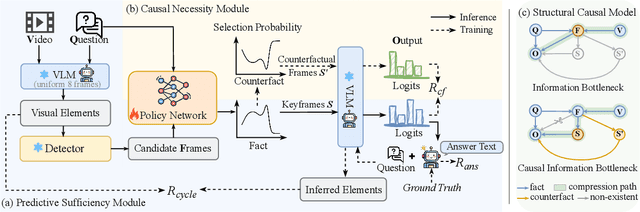
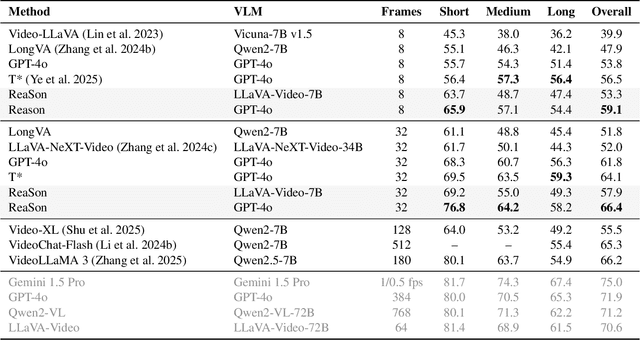
Keyframe selection has become essential for video understanding with vision-language models (VLMs) due to limited input tokens and the temporal sparsity of relevant information across video frames. Video understanding often relies on effective keyframes that are not only informative but also causally decisive. To this end, we propose Reinforced Causal Search with Information Bottleneck (ReaSon), a framework that formulates keyframe selection as an optimization problem with the help of a novel Causal Information Bottleneck (CIB), which explicitly defines keyframes as those satisfying both predictive sufficiency and causal necessity. Specifically, ReaSon employs a learnable policy network to select keyframes from a visually relevant pool of candidate frames to capture predictive sufficiency, and then assesses causal necessity via counterfactual interventions. Finally, a composite reward aligned with the CIB principle is designed to guide the selection policy through reinforcement learning. Extensive experiments on NExT-QA, EgoSchema, and Video-MME demonstrate that ReaSon consistently outperforms existing state-of-the-art methods under limited-frame settings, validating its effectiveness and generalization ability.
vMFCoOp: Towards Equilibrium on a Unified Hyperspherical Manifold for Prompting Biomedical VLMs
Nov 13, 2025Recent advances in context optimization (CoOp) guided by large language model (LLM)-distilled medical semantic priors offer a scalable alternative to manual prompt engineering and full fine-tuning for adapting biomedical CLIP-based vision-language models (VLMs). However, prompt learning in this context is challenged by semantic misalignment between LLMs and CLIP variants due to divergent training corpora and model architectures; it further lacks scalability across continuously evolving families of foundation models. More critically, pairwise multimodal alignment via conventional Euclidean-space optimization lacks the capacity to model unified representations or apply localized geometric constraints, which tends to amplify modality gaps in complex biomedical imaging and destabilize few-shot adaptation. In this work, we propose vMFCoOp, a framework that inversely estimates von Mises-Fisher (vMF) distributions on a shared Hyperspherical Manifold, aligning semantic biases between arbitrary LLMs and CLIP backbones via Unified Semantic Anchors to achieve robust biomedical prompting and superior few-shot classification. Grounded in three complementary constraints, vMFCoOp demonstrates consistent improvements across 14 medical datasets, 12 medical imaging modalities, and 13 anatomical regions, outperforming state-of-the-art methods in accuracy, generalization, and clinical applicability. This work aims to continuously expand to encompass more downstream applications, and the corresponding resources are intended to be shared through https://github.com/VinyehShaw/UniEqui.
Rethinking Brain Tumor Segmentation from the Frequency Domain Perspective
Jun 11, 2025Precise segmentation of brain tumors, particularly contrast-enhancing regions visible in post-contrast MRI (areas highlighted by contrast agent injection), is crucial for accurate clinical diagnosis and treatment planning but remains challenging. However, current methods exhibit notable performance degradation in segmenting these enhancing brain tumor areas, largely due to insufficient consideration of MRI-specific tumor features such as complex textures and directional variations. To address this, we propose the Harmonized Frequency Fusion Network (HFF-Net), which rethinks brain tumor segmentation from a frequency-domain perspective. To comprehensively characterize tumor regions, we develop a Frequency Domain Decomposition (FDD) module that separates MRI images into low-frequency components, capturing smooth tumor contours and high-frequency components, highlighting detailed textures and directional edges. To further enhance sensitivity to tumor boundaries, we introduce an Adaptive Laplacian Convolution (ALC) module that adaptively emphasizes critical high-frequency details using dynamically updated convolution kernels. To effectively fuse tumor features across multiple scales, we design a Frequency Domain Cross-Attention (FDCA) integrating semantic, positional, and slice-specific information. We further validate and interpret frequency-domain improvements through visualization, theoretical reasoning, and experimental analyses. Extensive experiments on four public datasets demonstrate that HFF-Net achieves an average relative improvement of 4.48\% (ranging from 2.39\% to 7.72\%) in the mean Dice scores across the three major subregions, and an average relative improvement of 7.33% (ranging from 5.96% to 8.64%) in the segmentation of contrast-enhancing tumor regions, while maintaining favorable computational efficiency and clinical applicability. Code: https://github.com/VinyehShaw/HFF.
THU-Warwick Submission for EPIC-KITCHEN Challenge 2025: Semi-Supervised Video Object Segmentation
Jun 07, 2025In this report, we describe our approach to egocentric video object segmentation. Our method combines large-scale visual pretraining from SAM2 with depth-based geometric cues to handle complex scenes and long-term tracking. By integrating these signals in a unified framework, we achieve strong segmentation performance. On the VISOR test set, our method reaches a J&F score of 90.1%.
Rethinking Regularization Methods for Knowledge Graph Completion
May 29, 2025



Knowledge graph completion (KGC) has attracted considerable attention in recent years because it is critical to improving the quality of knowledge graphs. Researchers have continuously explored various models. However, most previous efforts have neglected to take advantage of regularization from a deeper perspective and therefore have not been used to their full potential. This paper rethinks the application of regularization methods in KGC. Through extensive empirical studies on various KGC models, we find that carefully designed regularization not only alleviates overfitting and reduces variance but also enables these models to break through the upper bounds of their original performance. Furthermore, we introduce a novel sparse-regularization method that embeds the concept of rank-based selective sparsity into the KGC regularizer. The core idea is to selectively penalize those components with significant features in the embedding vector, thus effectively ignoring many components that contribute little and may only represent noise. Various comparative experiments on multiple datasets and multiple models show that the SPR regularization method is better than other regularization methods and can enable the KGC model to further break through the performance margin.
Rethinking Score Distilling Sampling for 3D Editing and Generation
May 03, 2025Score Distillation Sampling (SDS) has emerged as a prominent method for text-to-3D generation by leveraging the strengths of 2D diffusion models. However, SDS is limited to generation tasks and lacks the capability to edit existing 3D assets. Conversely, variants of SDS that introduce editing capabilities often can not generate new 3D assets effectively. In this work, we observe that the processes of generation and editing within SDS and its variants have unified underlying gradient terms. Building on this insight, we propose Unified Distillation Sampling (UDS), a method that seamlessly integrates both the generation and editing of 3D assets. Essentially, UDS refines the gradient terms used in vanilla SDS methods, unifying them to support both tasks. Extensive experiments demonstrate that UDS not only outperforms baseline methods in generating 3D assets with richer details but also excels in editing tasks, thereby bridging the gap between 3D generation and editing. The code is available on: https://github.com/xingy038/UDS.
From Gaze to Insight: Bridging Human Visual Attention and Vision Language Model Explanation for Weakly-Supervised Medical Image Segmentation
Apr 15, 2025Medical image segmentation remains challenging due to the high cost of pixel-level annotations for training. In the context of weak supervision, clinician gaze data captures regions of diagnostic interest; however, its sparsity limits its use for segmentation. In contrast, vision-language models (VLMs) provide semantic context through textual descriptions but lack the explanation precision required. Recognizing that neither source alone suffices, we propose a teacher-student framework that integrates both gaze and language supervision, leveraging their complementary strengths. Our key insight is that gaze data indicates where clinicians focus during diagnosis, while VLMs explain why those regions are significant. To implement this, the teacher model first learns from gaze points enhanced by VLM-generated descriptions of lesion morphology, establishing a foundation for guiding the student model. The teacher then directs the student through three strategies: (1) Multi-scale feature alignment to fuse visual cues with textual semantics; (2) Confidence-weighted consistency constraints to focus on reliable predictions; (3) Adaptive masking to limit error propagation in uncertain areas. Experiments on the Kvasir-SEG, NCI-ISBI, and ISIC datasets show that our method achieves Dice scores of 80.78%, 80.53%, and 84.22%, respectively-improving 3-5% over gaze baselines without increasing the annotation burden. By preserving correlations among predictions, gaze data, and lesion descriptions, our framework also maintains clinical interpretability. This work illustrates how integrating human visual attention with AI-generated semantic context can effectively overcome the limitations of individual weak supervision signals, thereby advancing the development of deployable, annotation-efficient medical AI systems. Code is available at: https://github.com/jingkunchen/FGI.git.
ConsDreamer: Advancing Multi-View Consistency for Zero-Shot Text-to-3D Generation
Apr 03, 2025Recent advances in zero-shot text-to-3D generation have revolutionized 3D content creation by enabling direct synthesis from textual descriptions. While state-of-the-art methods leverage 3D Gaussian Splatting with score distillation to enhance multi-view rendering through pre-trained text-to-image (T2I) models, they suffer from inherent view biases in T2I priors. These biases lead to inconsistent 3D generation, particularly manifesting as the multi-face Janus problem, where objects exhibit conflicting features across views. To address this fundamental challenge, we propose ConsDreamer, a novel framework that mitigates view bias by refining both the conditional and unconditional terms in the score distillation process: (1) a View Disentanglement Module (VDM) that eliminates viewpoint biases in conditional prompts by decoupling irrelevant view components and injecting precise camera parameters; and (2) a similarity-based partial order loss that enforces geometric consistency in the unconditional term by aligning cosine similarities with azimuth relationships. Extensive experiments demonstrate that ConsDreamer effectively mitigates the multi-face Janus problem in text-to-3D generation, outperforming existing methods in both visual quality and consistency.
D2Fusion: Dual-domain Fusion with Feature Superposition for Deepfake Detection
Mar 21, 2025Deepfake detection is crucial for curbing the harm it causes to society. However, current Deepfake detection methods fail to thoroughly explore artifact information across different domains due to insufficient intrinsic interactions. These interactions refer to the fusion and coordination after feature extraction processes across different domains, which are crucial for recognizing complex forgery clues. Focusing on more generalized Deepfake detection, in this work, we introduce a novel bi-directional attention module to capture the local positional information of artifact clues from the spatial domain. This enables accurate artifact localization, thus addressing the coarse processing with artifact features. To further address the limitation that the proposed bi-directional attention module may not well capture global subtle forgery information in the artifact feature (e.g., textures or edges), we employ a fine-grained frequency attention module in the frequency domain. By doing so, we can obtain high-frequency information in the fine-grained features, which contains the global and subtle forgery information. Although these features from the diverse domains can be effectively and independently improved, fusing them directly does not effectively improve the detection performance. Therefore, we propose a feature superposition strategy that complements information from spatial and frequency domains. This strategy turns the feature components into the form of wave-like tokens, which are updated based on their phase, such that the distinctions between authentic and artifact features can be amplified. Our method demonstrates significant improvements over state-of-the-art (SOTA) methods on five public Deepfake datasets in capturing abnormalities across different manipulated operations and real-life.