 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Modalities Remember: Continual Learning for Multimodal Knowledge Graphs
Apr 03, 2026Real-world multimodal knowledge graphs (MMKGs) are dynamic, with new entities, relations, and multimodal knowledge emerging over time. Existing continual knowledge graph reasoning (CKGR) methods focus on structural triples and cannot fully exploit multimodal signals from new entities. Existing multimodal knowledge graph reasoning (MMKGR) methods, however, usually assume static graphs and suffer catastrophic forgetting as graphs evolve. To address this gap, we present a systematic study of continual multimodal knowledge graph reasoning (CMMKGR). We construct several continual multimodal knowledge graph benchmarks from existing MMKG datasets and propose MRCKG, a new CMMKGR model. Specifically, MRCKG employs a multimodal-structural collaborative curriculum to schedule progressive learning based on the structural connectivity of new triples to the historical graph and their multimodal compatibility. It also introduces a cross-modal knowledge preservation mechanism to mitigate forgetting through entity representation stability, relational semantic consistency, and modality anchoring. In addition, a multimodal contrastive replay scheme with a two-stage optimization strategy reinforces learned knowledge via multimodal importance sampling and representation alignment. Experiments on multiple datasets show that MRCKG preserves previously learned multimodal knowledge while substantially improving the learning of new knowledge.
Your Inference Request Will Become a Black Box: Confidential Inference for Cloud-based Large Language Models
Feb 27, 2026The increasing reliance on cloud-hosted Large Language Models (LLMs) exposes sensitive client data, such as prompts and responses, to potential privacy breaches by service providers. Existing approaches fail to ensure privacy, maintain model performance, and preserve computational efficiency simultaneously. To address this challenge, we propose Talaria, a confidential inference framework that partitions the LLM pipeline to protect client data without compromising the cloud's model intellectual property or inference quality. Talaria executes sensitive, weight-independent operations within a client-controlled Confidential Virtual Machine (CVM) while offloading weight-dependent computations to the cloud GPUs. The interaction between these environments is secured by our Reversible Masked Outsourcing (ReMO) protocol, which uses a hybrid masking technique to reversibly obscure intermediate data before outsourcing computations. Extensive evaluations show that Talaria can defend against state-of-the-art token inference attacks, reducing token reconstruction accuracy from over 97.5% to an average of 1.34%, all while being a lossless mechanism that guarantees output identical to the original model without significantly decreasing efficiency and scalability. To the best of our knowledge, this is the first work that ensures clients' prompts and responses remain inaccessible to the cloud, while also preserving model privacy, performance, and efficiency.
BrowseComp-$V^3$: A Visual, Vertical, and Verifiable Benchmark for Multimodal Browsing Agents
Feb 13, 2026Multimodal large language models (MLLMs), equipped with increasingly advanced planning and tool-use capabilities, are evolving into autonomous agents capable of performing multimodal web browsing and deep search in open-world environments. However, existing benchmarks for multimodal browsing remain limited in task complexity, evidence accessibility, and evaluation granularity, hindering comprehensive and reproducible assessments of deep search capabilities. To address these limitations, we introduce BrowseComp-$V^3$, a novel benchmark consisting of 300 carefully curated and challenging questions spanning diverse domains. The benchmark emphasizes deep, multi-level, and cross-modal multi-hop reasoning, where critical evidence is interleaved across textual and visual modalities within and across web pages. All supporting evidence is strictly required to be publicly searchable, ensuring fairness and reproducibility. Beyond final-answer accuracy, we incorporate an expert-validated, subgoal-driven process evaluation mechanism that enables fine-grained analysis of intermediate reasoning behaviors and systematic characterization of capability boundaries. In addition, we propose OmniSeeker, a unified multimodal browsing agent framework integrating diverse web search and visual perception tools. Comprehensive experiments demonstrate that even state-of-the-art models achieve only 36% accuracy on our benchmark, revealing critical bottlenecks in multimodal information integration and fine-grained perception. Our results highlight a fundamental gap between current model capabilities and robust multimodal deep search in real-world settings.
Learning to Factorize and Adapt: A Versatile Approach Toward Universal Spatio-Temporal Foundation Models
Jan 17, 2026Spatio-Temporal (ST) Foundation Models (STFMs) promise cross-dataset generalization, yet joint ST pretraining is computationally expensive and grapples with the heterogeneity of domain-specific spatial patterns. Substantially extending our preliminary conference version, we present FactoST-v2, an enhanced factorized framework redesigned for full weight transfer and arbitrary-length generalization. FactoST-v2 decouples universal temporal learning from domain-specific spatial adaptation. The first stage pretrains a minimalist encoder-only backbone using randomized sequence masking to capture invariant temporal dynamics, enabling probabilistic quantile prediction across variable horizons. The second stage employs a streamlined adapter to rapidly inject spatial awareness via meta adaptive learning and prompting. Comprehensive evaluations across diverse domains demonstrate that FactoST-v2 achieves state-of-the-art accuracy with linear efficiency - significantly outperforming existing foundation models in zero-shot and few-shot scenarios while rivaling domain-specific expert baselines. This factorized paradigm offers a practical, scalable path toward truly universal STFMs. Code is available at https://github.com/CityMind-Lab/FactoST.
Rethinking Regularization Methods for Knowledge Graph Completion
May 29, 2025



Knowledge graph completion (KGC) has attracted considerable attention in recent years because it is critical to improving the quality of knowledge graphs. Researchers have continuously explored various models. However, most previous efforts have neglected to take advantage of regularization from a deeper perspective and therefore have not been used to their full potential. This paper rethinks the application of regularization methods in KGC. Through extensive empirical studies on various KGC models, we find that carefully designed regularization not only alleviates overfitting and reduces variance but also enables these models to break through the upper bounds of their original performance. Furthermore, we introduce a novel sparse-regularization method that embeds the concept of rank-based selective sparsity into the KGC regularizer. The core idea is to selectively penalize those components with significant features in the embedding vector, thus effectively ignoring many components that contribute little and may only represent noise. Various comparative experiments on multiple datasets and multiple models show that the SPR regularization method is better than other regularization methods and can enable the KGC model to further break through the performance margin.
Efficient Prototype Consistency Learning in Medical Image Segmentation via Joint Uncertainty and Data Augmentation
May 22, 2025Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To overcome this issue, we propose an efficient prototype consistency learning via joint uncertainty quantification and data augmentation (EPCL-JUDA) to enhance the semantic expression of prototypes based on the framework of Mean-Teacher. The concatenation of original and augmented labeled data is fed into student network to generate expressive prototypes. Then, a joint uncertainty quantification method is devised to optimize pseudo-labels and generate reliable prototypes for original and augmented unlabeled data separately. High-quality global prototypes for each class are formed by fusing labeled and unlabeled prototypes, which are utilized to generate prototype-to-features to conduct consistency learning. Notably, a prototype network is proposed to reduce high memory requirements brought by the introduction of augmented data. Extensive experiments on Left Atrium, Pancreas-NIH, Type B Aortic Dissection datasets demonstrate EPCL-JUDA's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
Mutual Evidential Deep Learning for Medical Image Segmentation
May 18, 2025Existing semi-supervised medical segmentation co-learning frameworks have realized that model performance can be diminished by the biases in model recognition caused by low-quality pseudo-labels. Due to the averaging nature of their pseudo-label integration strategy, they fail to explore the reliability of pseudo-labels from different sources. In this paper, we propose a mutual evidential deep learning (MEDL) framework that offers a potentially viable solution for pseudo-label generation in semi-supervised learning from two perspectives. First, we introduce networks with different architectures to generate complementary evidence for unlabeled samples and adopt an improved class-aware evidential fusion to guide the confident synthesis of evidential predictions sourced from diverse architectural networks. Second, utilizing the uncertainty in the fused evidence, we design an asymptotic Fisher information-based evidential learning strategy. This strategy enables the model to initially focus on unlabeled samples with more reliable pseudo-labels, gradually shifting attention to samples with lower-quality pseudo-labels while avoiding over-penalization of mislabeled classes in high data uncertainty samples. Additionally, for labeled data, we continue to adopt an uncertainty-driven asymptotic learning strategy, gradually guiding the model to focus on challenging voxels. Extensive experiments on five mainstream datasets have demonstrated that MEDL achieves state-of-the-art performance.
Multi-Prototype Embedding Refinement for Semi-Supervised Medical Image Segmentation
Mar 18, 2025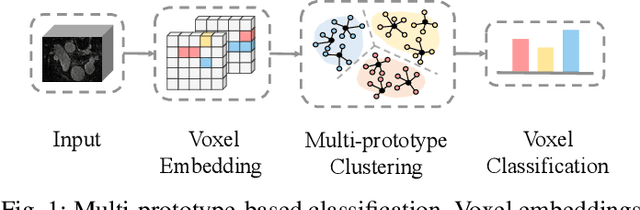
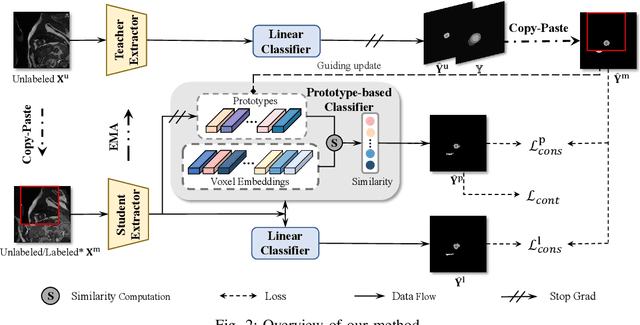
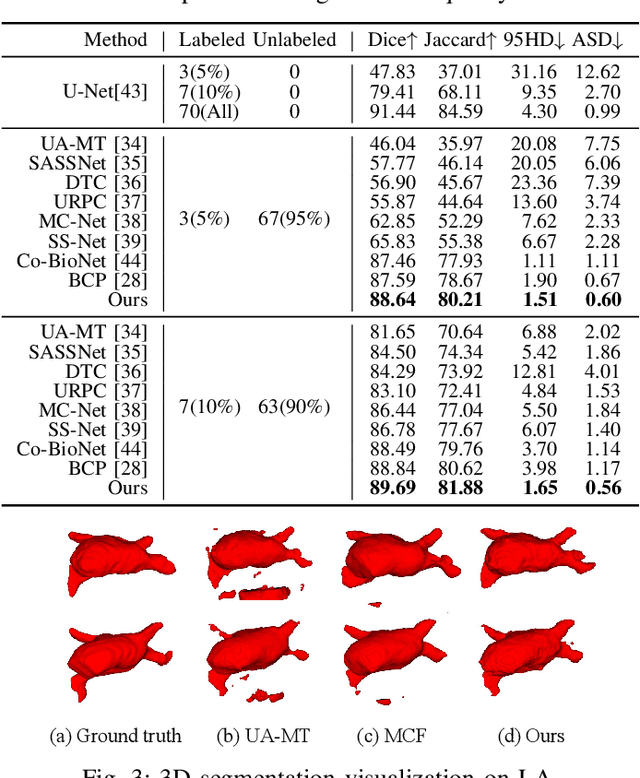
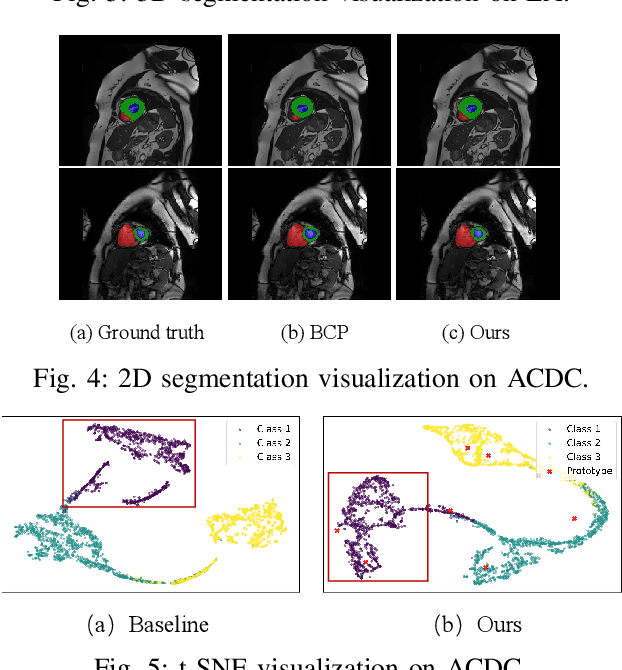
Medical image segmentation aims to identify anatomical structures at the voxel-level. Segmentation accuracy relies on distinguishing voxel differences. Compared to advancements achieved in studies of the inter-class variance, the intra-class variance receives less attention. Moreover, traditional linear classifiers, limited by a single learnable weight per class, struggle to capture this finer distinction. To address the above challenges, we propose a Multi-Prototype-based Embedding Refinement method for semi-supervised medical image segmentation. Specifically, we design a multi-prototype-based classification strategy, rethinking the segmentation from the perspective of structural relationships between voxel embeddings. The intra-class variations are explored by clustering voxels along the distribution of multiple prototypes in each class. Next, we introduce a consistency constraint to alleviate the limitation of linear classifiers. This constraint integrates different classification granularities from a linear classifier and the proposed prototype-based classifier. In the thorough evaluation on two popular benchmarks, our method achieves superior performance compared with state-of-the-art methods. Code is available at https://github.com/Briley-byl123/MPER.
UniTrans: A Unified Vertical Federated Knowledge Transfer Framework for Enhancing Cross-Hospital Collaboration
Jan 20, 2025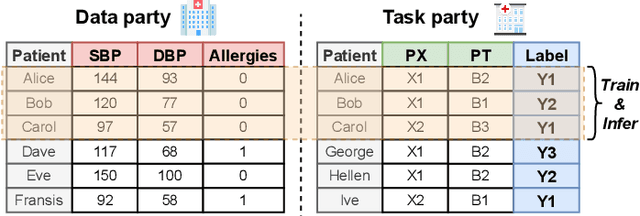
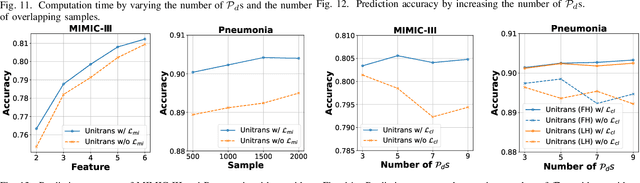
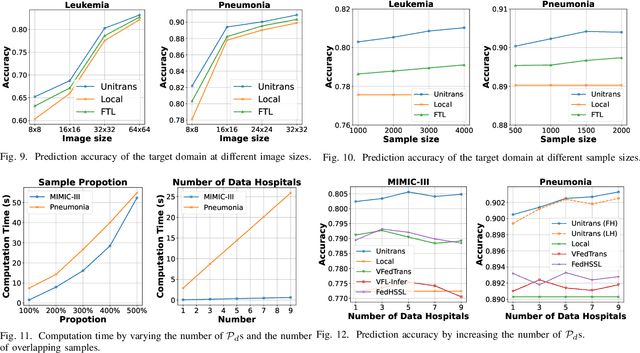
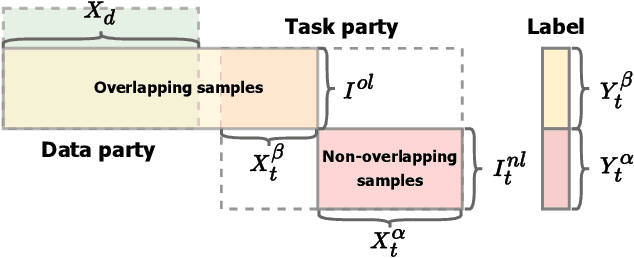
Cross-hospital collaboration has the potential to address disparities in medical resources across different regions. However, strict privacy regulations prohibit the direct sharing of sensitive patient information between hospitals. Vertical federated learning (VFL) offers a novel privacy-preserving machine learning paradigm that maximizes data utility across multiple hospitals. Traditional VFL methods, however, primarily benefit patients with overlapping data, leaving vulnerable non-overlapping patients without guaranteed improvements in medical prediction services. While some knowledge transfer techniques can enhance the prediction performance for non-overlapping patients, they fall short in addressing scenarios where overlapping and non-overlapping patients belong to different domains, resulting in challenges such as feature heterogeneity and label heterogeneity. To address these issues, we propose a novel unified vertical federated knowledge transfer framework (Unitrans). Our framework consists of three key steps. First, we extract the federated representation of overlapping patients by employing an effective vertical federated representation learning method to model multi-party joint features online. Next, each hospital learns a local knowledge transfer module offline, enabling the transfer of knowledge from the federated representation of overlapping patients to the enriched representation of local non-overlapping patients in a domain-adaptive manner. Finally, hospitals utilize these enriched local representations to enhance performance across various downstream medical prediction tasks. Experiments on real-world medical datasets validate the framework's dual effectiveness in both intra-domain and cross-domain knowledge transfer. The code of \method is available at \url{https://github.com/Chung-ju/Unitrans}.
Residual Feature-Reutilization Inception Network for Image Classification
Dec 27, 2024Capturing feature information effectively is of great importance in the field of computer vision. With the development of convolutional neural networks (CNNs), concepts like residual connection and multiple scales promote continual performance gains in diverse deep learning vision tasks. In this paper, we propose a novel CNN architecture that it consists of residual feature-reutilization inceptions (ResFRI) or split-residual feature-reutilization inceptions (Split-ResFRI). And it is composed of four convolutional combinations of different structures connected by specially designed information interaction passages, which are utilized to extract multi-scale feature information and effectively increase the receptive field of the model. Moreover, according to the network structure designed above, Split-ResFRI can adjust the segmentation ratio of the input information, thereby reducing the number of parameters and guaranteeing the model performance. Specifically, in experiments based on popular vision datasets, such as CIFAR10 ($97.94$\%), CIFAR100 ($85.91$\%) and Tiny Imagenet ($70.54$\%), we obtain state-of-the-art results compared with other modern models under the premise that the model size is approximate and no additional data is used.