 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3CoTBench: Benchmark Chain-of-Thought of MLLMs in Medical Image Understanding
Jan 13, 2026Chain-of-Thought (CoT) reasoning has proven effective in enhancing large language models by encouraging step-by-step intermediate reasoning, and recent advances have extended this paradigm to Multimodal Large Language Models (MLLMs). In the medical domain, where diagnostic decisions depend on nuanced visual cues and sequential reasoning, CoT aligns naturally with clinical thinking processes. However, Current benchmarks for medical image understanding generally focus on the final answer while ignoring the reasoning path. An opaque process lacks reliable bases for judgment, making it difficult to assist doctors in diagnosis. To address this gap, we introduce a new M3CoTBench benchmark specifically designed to evaluate the correctness, efficiency, impact, and consistency of CoT reasoning in medical image understanding. M3CoTBench features 1) a diverse, multi-level difficulty dataset covering 24 examination types, 2) 13 varying-difficulty tasks, 3) a suite of CoT-specific evaluation metrics (correctness, efficiency, impact, and consistency) tailored to clinical reasoning, and 4) a performance analysis of multiple MLLMs. M3CoTBench systematically evaluates CoT reasoning across diverse medical imaging tasks, revealing current limitations of MLLMs in generating reliable and clinically interpretable reasoning, and aims to foster the development of transparent, trustworthy, and diagnostically accurate AI systems for healthcare. Project page at https://juntaojianggavin.github.io/projects/M3CoTBench/.
Mutual Evidential Deep Learning for Medical Image Segmentation
May 18, 2025Existing semi-supervised medical segmentation co-learning frameworks have realized that model performance can be diminished by the biases in model recognition caused by low-quality pseudo-labels. Due to the averaging nature of their pseudo-label integration strategy, they fail to explore the reliability of pseudo-labels from different sources. In this paper, we propose a mutual evidential deep learning (MEDL) framework that offers a potentially viable solution for pseudo-label generation in semi-supervised learning from two perspectives. First, we introduce networks with different architectures to generate complementary evidence for unlabeled samples and adopt an improved class-aware evidential fusion to guide the confident synthesis of evidential predictions sourced from diverse architectural networks. Second, utilizing the uncertainty in the fused evidence, we design an asymptotic Fisher information-based evidential learning strategy. This strategy enables the model to initially focus on unlabeled samples with more reliable pseudo-labels, gradually shifting attention to samples with lower-quality pseudo-labels while avoiding over-penalization of mislabeled classes in high data uncertainty samples. Additionally, for labeled data, we continue to adopt an uncertainty-driven asymptotic learning strategy, gradually guiding the model to focus on challenging voxels. Extensive experiments on five mainstream datasets have demonstrated that MEDL achieves state-of-the-art performance.
Multi-Prototype Embedding Refinement for Semi-Supervised Medical Image Segmentation
Mar 18, 2025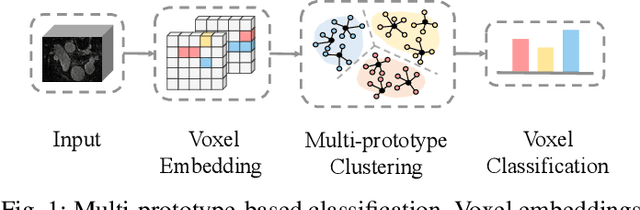
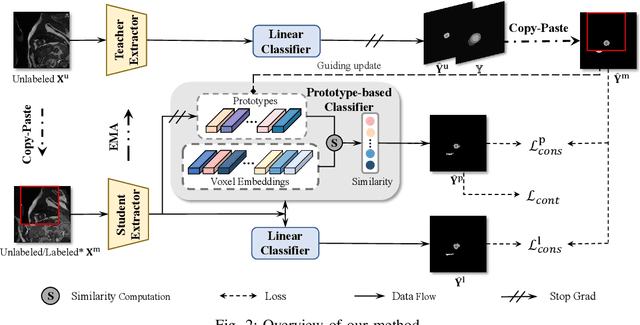
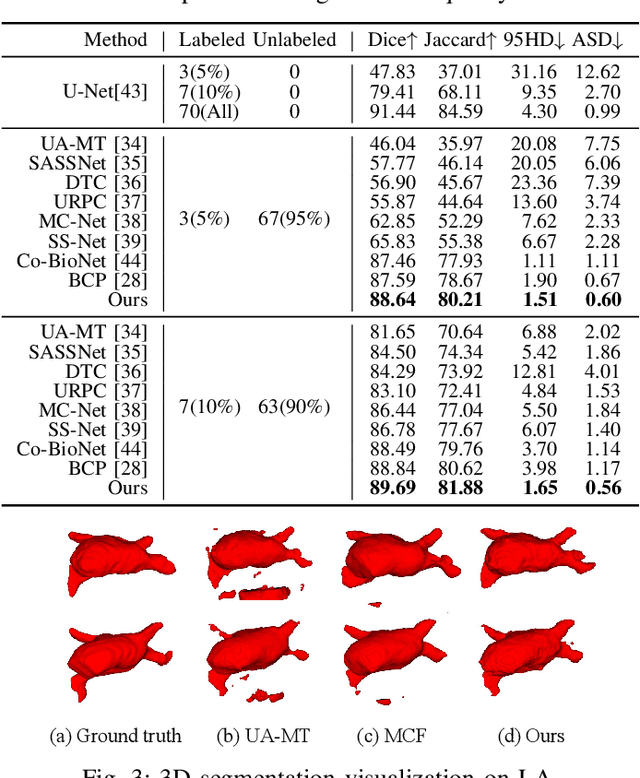
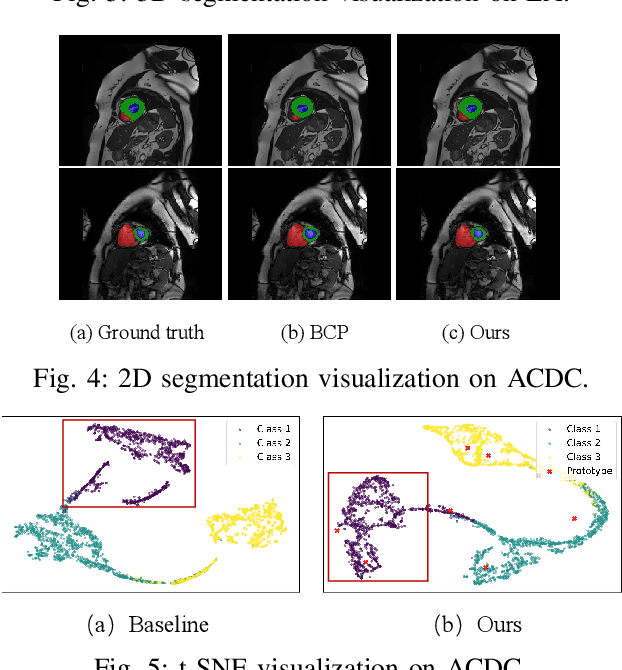
Medical image segmentation aims to identify anatomical structures at the voxel-level. Segmentation accuracy relies on distinguishing voxel differences. Compared to advancements achieved in studies of the inter-class variance, the intra-class variance receives less attention. Moreover, traditional linear classifiers, limited by a single learnable weight per class, struggle to capture this finer distinction. To address the above challenges, we propose a Multi-Prototype-based Embedding Refinement method for semi-supervised medical image segmentation. Specifically, we design a multi-prototype-based classification strategy, rethinking the segmentation from the perspective of structural relationships between voxel embeddings. The intra-class variations are explored by clustering voxels along the distribution of multiple prototypes in each class. Next, we introduce a consistency constraint to alleviate the limitation of linear classifiers. This constraint integrates different classification granularities from a linear classifier and the proposed prototype-based classifier. In the thorough evaluation on two popular benchmarks, our method achieves superior performance compared with state-of-the-art methods. Code is available at https://github.com/Briley-byl123/MPER.
Image Inversion: A Survey from GANs to Diffusion and Beyond
Feb 17, 2025Image inversion is a fundamental task in generative models, aiming to map images back to their latent representations to enable downstream applications such as editing, restoration, and style transfer. This paper provides a comprehensive review of the latest advancements in image inversion techniques, focusing on two main paradigms: Generative Adversarial Network (GAN) inversion and diffusion model inversion. We categorize these techniques based on their optimization methods. For GAN inversion, we systematically classify existing methods into encoder-based approaches, latent optimization approaches, and hybrid approaches, analyzing their theoretical foundations, technical innovations, and practical trade-offs. For diffusion model inversion, we explore training-free strategies, fine-tuning methods, and the design of additional trainable modules, highlighting their unique advantages and limitations. Additionally, we discuss several popular downstream applications and emerging applications beyond image tasks, identifying current challenges and future research directions. By synthesizing the latest developments, this paper aims to provide researchers and practitioners with a valuable reference resource, promoting further advancements in the field of image inversion. We keep track of the latest works at https://github.com/RyanChenYN/ImageInversion