 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementarity-driven Representation Learning for Multi-modal Knowledge Graph Completion
Jul 28, 2025Multi-modal Knowledge Graph Completion (MMKGC) aims to uncover hidden world knowledge in multimodal knowledge graphs by leveraging both multimodal and structural entity information. However, the inherent imbalance in multimodal knowledge graphs, where modality distributions vary across entities, poses challenges in utilizing additional modality data for robust entity representation. Existing MMKGC methods typically rely on attention or gate-based fusion mechanisms but overlook complementarity contained in multi-modal data. In this paper, we propose a novel framework named Mixture of Complementary Modality Experts (MoCME), which consists of a Complementarity-guided Modality Knowledge Fusion (CMKF) module and an Entropy-guided Negative Sampling (EGNS) mechanism. The CMKF module exploits both intra-modal and inter-modal complementarity to fuse multi-view and multi-modal embeddings, enhancing representations of entities. Additionally, we introduce an Entropy-guided Negative Sampling mechanism to dynamically prioritize informative and uncertain negative samples to enhance training effectiveness and model robustness. Extensive experiments on five benchmark datasets demonstrate that our MoCME achieves state-of-the-art performance, surpassing existing approaches.
Adaptive Fuzzy Time Series Forecasting via Partially Asymmetric Convolution and Sub-Sliding Window Fusion
Jul 28, 2025At present, state-of-the-art forecasting models are short of the ability to capture spatio-temporal dependency and synthesize global information at the stage of learning. To address this issue, in this paper, through the adaptive fuzzified construction of temporal data, we propose a novel convolutional architecture with partially asymmetric design based on the scheme of sliding window to realize accurate time series forecasting. First, the construction strategy of traditional fuzzy time series is improved to further extract short and long term temporal interrelation, which enables every time node to automatically possess corresponding global information and inner relationships among them in a restricted sliding window and the process does not require human involvement. Second, a bilateral Atrous algorithm is devised to reduce calculation demand of the proposed model without sacrificing global characteristics of elements. And it also allows the model to avoid processing redundant information. Third, after the transformation of time series, a partially asymmetric convolutional architecture is designed to more flexibly mine data features by filters in different directions on feature maps, which gives the convolutional neural network (CNN) the ability to construct sub-windows within existing sliding windows to model at a more fine-grained level. And after obtaining the time series information at different levels, the multi-scale features from different sub-windows will be sent to the corresponding network layer for time series information fusion. Compared with other competitive modern models, the proposed method achieves state-of-the-art results on most of popular time series datasets, which is fully verified by the experimental results.
Efficient Prototype Consistency Learning in Medical Image Segmentation via Joint Uncertainty and Data Augmentation
May 22, 2025Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To overcome this issue, we propose an efficient prototype consistency learning via joint uncertainty quantification and data augmentation (EPCL-JUDA) to enhance the semantic expression of prototypes based on the framework of Mean-Teacher. The concatenation of original and augmented labeled data is fed into student network to generate expressive prototypes. Then, a joint uncertainty quantification method is devised to optimize pseudo-labels and generate reliable prototypes for original and augmented unlabeled data separately. High-quality global prototypes for each class are formed by fusing labeled and unlabeled prototypes, which are utilized to generate prototype-to-features to conduct consistency learning. Notably, a prototype network is proposed to reduce high memory requirements brought by the introduction of augmented data. Extensive experiments on Left Atrium, Pancreas-NIH, Type B Aortic Dissection datasets demonstrate EPCL-JUDA's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
Mutual Evidential Deep Learning for Medical Image Segmentation
May 18, 2025Existing semi-supervised medical segmentation co-learning frameworks have realized that model performance can be diminished by the biases in model recognition caused by low-quality pseudo-labels. Due to the averaging nature of their pseudo-label integration strategy, they fail to explore the reliability of pseudo-labels from different sources. In this paper, we propose a mutual evidential deep learning (MEDL) framework that offers a potentially viable solution for pseudo-label generation in semi-supervised learning from two perspectives. First, we introduce networks with different architectures to generate complementary evidence for unlabeled samples and adopt an improved class-aware evidential fusion to guide the confident synthesis of evidential predictions sourced from diverse architectural networks. Second, utilizing the uncertainty in the fused evidence, we design an asymptotic Fisher information-based evidential learning strategy. This strategy enables the model to initially focus on unlabeled samples with more reliable pseudo-labels, gradually shifting attention to samples with lower-quality pseudo-labels while avoiding over-penalization of mislabeled classes in high data uncertainty samples. Additionally, for labeled data, we continue to adopt an uncertainty-driven asymptotic learning strategy, gradually guiding the model to focus on challenging voxels. Extensive experiments on five mainstream datasets have demonstrated that MEDL achieves state-of-the-art performance.
Generalized Uncertainty-Based Evidential Fusion with Hybrid Multi-Head Attention for Weak-Supervised Temporal Action Localization
Dec 27, 2024Weakly supervised temporal action localization (WS-TAL) is a task of targeting at localizing complete action instances and categorizing them with video-level labels. Action-background ambiguity, primarily caused by background noise resulting from aggregation and intra-action variation, is a significant challenge for existing WS-TAL methods. In this paper, we introduce a hybrid multi-head attention (HMHA) module and generalized uncertainty-based evidential fusion (GUEF) module to address the problem. The proposed HMHA effectively enhances RGB and optical flow features by filtering redundant information and adjusting their feature distribution to better align with the WS-TAL task. Additionally, the proposed GUEF adaptively eliminates the interference of background noise by fusing snippet-level evidences to refine uncertainty measurement and select superior foreground feature information, which enables the model to concentrate on integral action instances to achieve better action localization and classification performance. Experimental results conducted on the THUMOS14 dataset demonstrate that our method outperforms state-of-the-art methods. Our code is available in \url{https://github.com/heyuanpengpku/GUEF/tree/main}.
Residual Feature-Reutilization Inception Network for Image Classification
Dec 27, 2024Capturing feature information effectively is of great importance in the field of computer vision. With the development of convolutional neural networks (CNNs), concepts like residual connection and multiple scales promote continual performance gains in diverse deep learning vision tasks. In this paper, we propose a novel CNN architecture that it consists of residual feature-reutilization inceptions (ResFRI) or split-residual feature-reutilization inceptions (Split-ResFRI). And it is composed of four convolutional combinations of different structures connected by specially designed information interaction passages, which are utilized to extract multi-scale feature information and effectively increase the receptive field of the model. Moreover, according to the network structure designed above, Split-ResFRI can adjust the segmentation ratio of the input information, thereby reducing the number of parameters and guaranteeing the model performance. Specifically, in experiments based on popular vision datasets, such as CIFAR10 ($97.94$\%), CIFAR100 ($85.91$\%) and Tiny Imagenet ($70.54$\%), we obtain state-of-the-art results compared with other modern models under the premise that the model size is approximate and no additional data is used.
An Adaptive Framework for Multi-View Clustering Leveraging Conditional Entropy Optimization
Dec 23, 2024Multi-view clustering (MVC) has emerged as a powerful technique for extracting valuable insights from data characterized by multiple perspectives or modalities. Despite significant advancements, existing MVC methods struggle with effectively quantifying the consistency and complementarity among views, and are particularly susceptible to the adverse effects of noisy views, known as the Noisy-View Drawback (NVD). To address these challenges, we propose CE-MVC, a novel framework that integrates an adaptive weighting algorithm with a parameter-decoupled deep model. Leveraging the concept of conditional entropy and normalized mutual information, CE-MVC quantitatively assesses and weights the informative contribution of each view, facilitating the construction of robust unified representations. The parameter-decoupled design enables independent processing of each view, effectively mitigating the influence of noise and enhancing overall clustering performance. Extensive experiments demonstrate that CE-MVC outperforms existing approaches, offering a more resilient and accurate solution for multi-view clustering tasks.
Towards Realistic Long-tailed Semi-supervised Learning in an Open World
May 23, 2024Open-world long-tailed semi-supervised learning (OLSSL) has increasingly attracted attention. However, existing OLSSL algorithms generally assume that the distributions between known and novel categories are nearly identical. Against this backdrop, we construct a more \emph{Realistic Open-world Long-tailed Semi-supervised Learning} (\textbf{ROLSSL}) setting where there is no premise on the distribution relationships between known and novel categories. Furthermore, even within the known categories, the number of labeled samples is significantly smaller than that of the unlabeled samples, as acquiring valid annotations is often prohibitively costly in the real world. Under the proposed ROLSSL setting, we propose a simple yet potentially effective solution called dual-stage post-hoc logit adjustments. The proposed approach revisits the logit adjustment strategy by considering the relationships among the frequency of samples, the total number of categories, and the overall size of data. Then, it estimates the distribution of unlabeled data for both known and novel categories to dynamically readjust the corresponding predictive probabilities, effectively mitigating category bias during the learning of known and novel classes with more selective utilization of imbalanced unlabeled data. Extensive experiments on datasets such as CIFAR100 and ImageNet100 have demonstrated performance improvements of up to 50.1\%, validating the superiority of our proposed method and establishing a strong baseline for this task. For further researches, the anonymous link to the experimental code is at \href{https://github.com/heyuanpengpku/ROLSSL}{\textcolor{brightpink}{https://github.com/heyuanpengpku/ROLSSL}}
Mixed Prototype Consistency Learning for Semi-supervised Medical Image Segmentation
Apr 16, 2024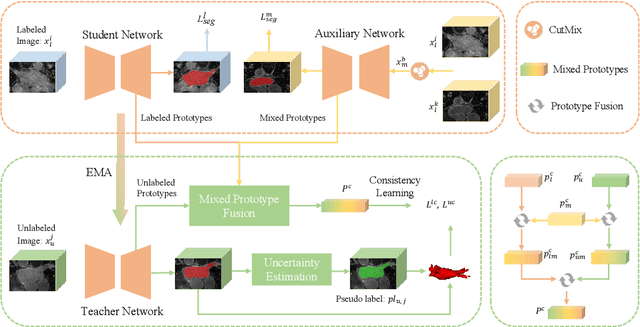


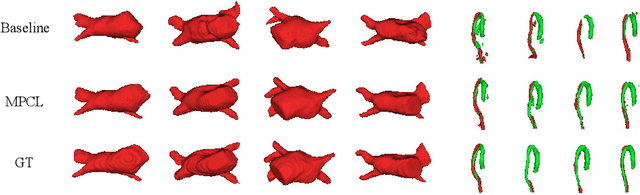
Recently, prototype learning has emerged in semi-supervised medical image segmentation and achieved remarkable performance. However, the scarcity of labeled data limits the expressiveness of prototypes in previous methods, potentially hindering the complete representation of prototypes for class embedding. To address this problem, we propose the Mixed Prototype Consistency Learning (MPCL) framework, which includes a Mean Teacher and an auxiliary network. The Mean Teacher generates prototypes for labeled and unlabeled data, while the auxiliary network produces additional prototypes for mixed data processed by CutMix. Through prototype fusion, mixed prototypes provide extra semantic information to both labeled and unlabeled prototypes. High-quality global prototypes for each class are formed by fusing two enhanced prototypes, optimizing the distribution of hidden embeddings used in consistency learning. Extensive experiments on the left atrium and type B aortic dissection datasets demonstrate MPCL's superiority over previous state-of-the-art approaches, confirming the effectiveness of our framework. The code will be released soon.
Uncertainty-aware Evidential Fusion-based Learning for Semi-supervised Medical Image Segmentation
Apr 11, 2024Although the existing uncertainty-based semi-supervised medical segmentation methods have achieved excellent performance, they usually only consider a single uncertainty evaluation, which often fails to solve the problem related to credibility completely. Therefore, based on the framework of evidential deep learning, this paper integrates the evidential predictive results in the cross-region of mixed and original samples to reallocate the confidence degree and uncertainty measure of each voxel, which is realized by emphasizing uncertain information of probability assignments fusion rule of traditional evidence theory. Furthermore, we design a voxel-level asymptotic learning strategy by introducing information entropy to combine with the fused uncertainty measure to estimate voxel prediction more precisely. The model will gradually pay attention to the prediction results with high uncertainty in the learning process, to learn the features that are difficult to master. The experimental results on LA, Pancreas-CT, ACDC and TBAD datasets demonstrate the superior performance of our proposed method in comparison with the existing state of the arts.