 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Anywhere in Code Generation
Apr 02, 2026Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
Your Inference Request Will Become a Black Box: Confidential Inference for Cloud-based Large Language Models
Feb 27, 2026The increasing reliance on cloud-hosted Large Language Models (LLMs) exposes sensitive client data, such as prompts and responses, to potential privacy breaches by service providers. Existing approaches fail to ensure privacy, maintain model performance, and preserve computational efficiency simultaneously. To address this challenge, we propose Talaria, a confidential inference framework that partitions the LLM pipeline to protect client data without compromising the cloud's model intellectual property or inference quality. Talaria executes sensitive, weight-independent operations within a client-controlled Confidential Virtual Machine (CVM) while offloading weight-dependent computations to the cloud GPUs. The interaction between these environments is secured by our Reversible Masked Outsourcing (ReMO) protocol, which uses a hybrid masking technique to reversibly obscure intermediate data before outsourcing computations. Extensive evaluations show that Talaria can defend against state-of-the-art token inference attacks, reducing token reconstruction accuracy from over 97.5% to an average of 1.34%, all while being a lossless mechanism that guarantees output identical to the original model without significantly decreasing efficiency and scalability. To the best of our knowledge, this is the first work that ensures clients' prompts and responses remain inaccessible to the cloud, while also preserving model privacy, performance, and efficiency.
KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
Jan 19, 2026Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.
Mutual Evidential Deep Learning for Medical Image Segmentation
May 18, 2025Existing semi-supervised medical segmentation co-learning frameworks have realized that model performance can be diminished by the biases in model recognition caused by low-quality pseudo-labels. Due to the averaging nature of their pseudo-label integration strategy, they fail to explore the reliability of pseudo-labels from different sources. In this paper, we propose a mutual evidential deep learning (MEDL) framework that offers a potentially viable solution for pseudo-label generation in semi-supervised learning from two perspectives. First, we introduce networks with different architectures to generate complementary evidence for unlabeled samples and adopt an improved class-aware evidential fusion to guide the confident synthesis of evidential predictions sourced from diverse architectural networks. Second, utilizing the uncertainty in the fused evidence, we design an asymptotic Fisher information-based evidential learning strategy. This strategy enables the model to initially focus on unlabeled samples with more reliable pseudo-labels, gradually shifting attention to samples with lower-quality pseudo-labels while avoiding over-penalization of mislabeled classes in high data uncertainty samples. Additionally, for labeled data, we continue to adopt an uncertainty-driven asymptotic learning strategy, gradually guiding the model to focus on challenging voxels. Extensive experiments on five mainstream datasets have demonstrated that MEDL achieves state-of-the-art performance.
Enhancing LLM Generation with Knowledge Hypergraph for Evidence-Based Medicine
Mar 18, 2025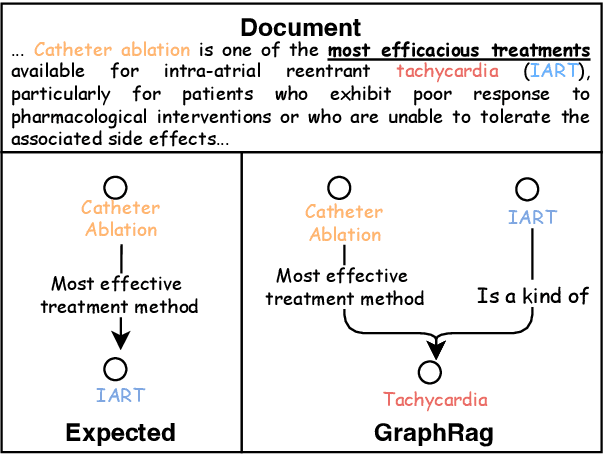
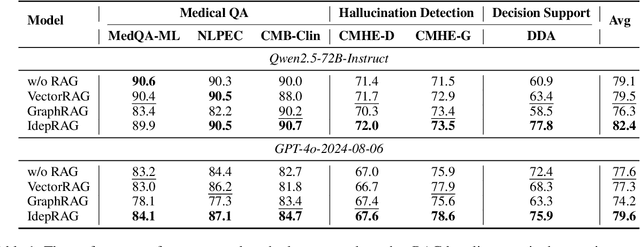
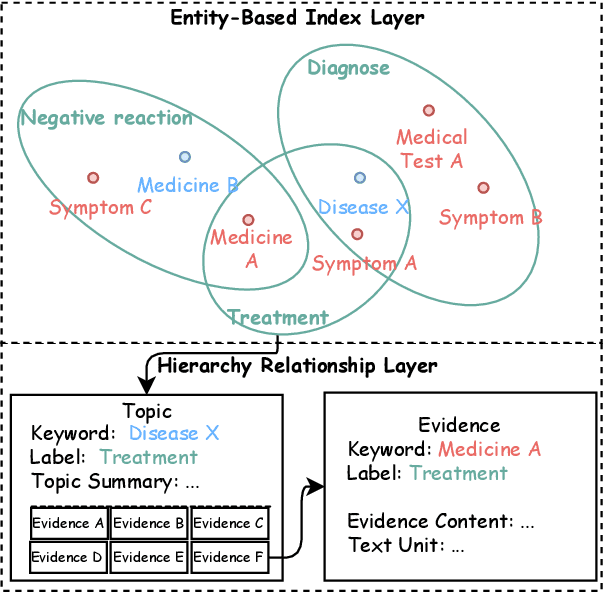
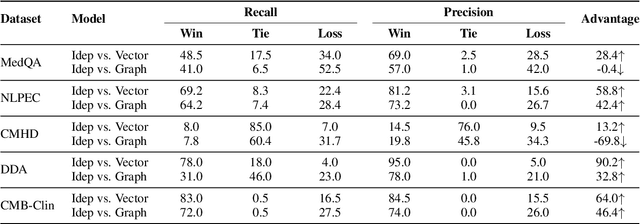
Evidence-based medicine (EBM) plays a crucial role in the application of large language models (LLMs) in healthcare, as it provides reliable support for medical decision-making processes. Although it benefits from current retrieval-augmented generation~(RAG) technologies, it still faces two significant challenges: the collection of dispersed evidence and the efficient organization of this evidence to support the complex queries necessary for EBM. To tackle these issues, we propose using LLMs to gather scattered evidence from multiple sources and present a knowledge hypergraph-based evidence management model to integrate these evidence while capturing intricate relationships. Furthermore, to better support complex queries, we have developed an Importance-Driven Evidence Prioritization (IDEP) algorithm that utilizes the LLM to generate multiple evidence features, each with an associated importance score, which are then used to rank the evidence and produce the final retrieval results. Experimental results from six datasets demonstrate that our approach outperforms existing RAG techniques in application domains of interest to EBM, such as medical quizzing, hallucination detection, and decision support. Testsets and the constructed knowledge graph can be accessed at \href{https://drive.google.com/file/d/1WJ9QTokK3MdkjEmwuFQxwH96j_Byawj_/view?usp=drive_link}{https://drive.google.com/rag4ebm}.
UniTrans: A Unified Vertical Federated Knowledge Transfer Framework for Enhancing Cross-Hospital Collaboration
Jan 20, 2025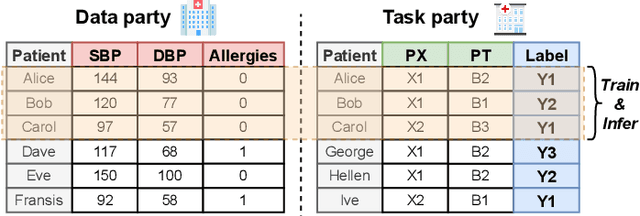
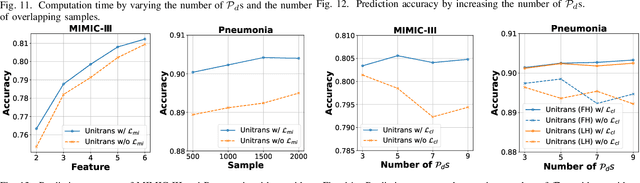
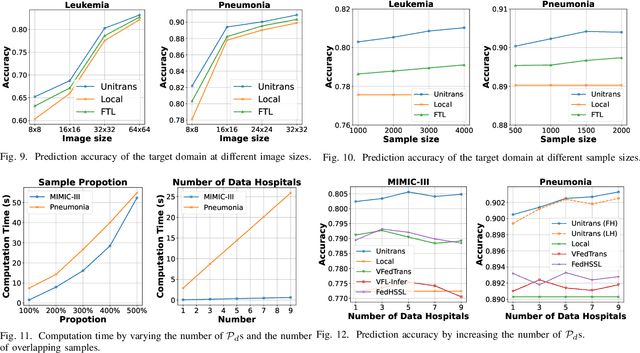
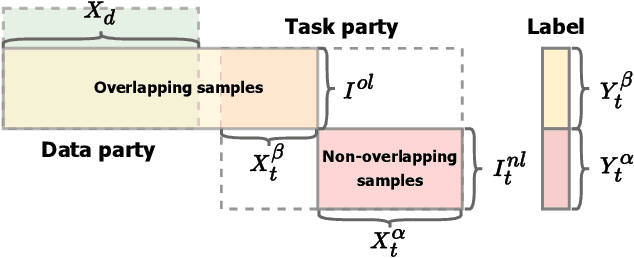
Cross-hospital collaboration has the potential to address disparities in medical resources across different regions. However, strict privacy regulations prohibit the direct sharing of sensitive patient information between hospitals. Vertical federated learning (VFL) offers a novel privacy-preserving machine learning paradigm that maximizes data utility across multiple hospitals. Traditional VFL methods, however, primarily benefit patients with overlapping data, leaving vulnerable non-overlapping patients without guaranteed improvements in medical prediction services. While some knowledge transfer techniques can enhance the prediction performance for non-overlapping patients, they fall short in addressing scenarios where overlapping and non-overlapping patients belong to different domains, resulting in challenges such as feature heterogeneity and label heterogeneity. To address these issues, we propose a novel unified vertical federated knowledge transfer framework (Unitrans). Our framework consists of three key steps. First, we extract the federated representation of overlapping patients by employing an effective vertical federated representation learning method to model multi-party joint features online. Next, each hospital learns a local knowledge transfer module offline, enabling the transfer of knowledge from the federated representation of overlapping patients to the enriched representation of local non-overlapping patients in a domain-adaptive manner. Finally, hospitals utilize these enriched local representations to enhance performance across various downstream medical prediction tasks. Experiments on real-world medical datasets validate the framework's dual effectiveness in both intra-domain and cross-domain knowledge transfer. The code of \method is available at \url{https://github.com/Chung-ju/Unitrans}.
Generalized Uncertainty-Based Evidential Fusion with Hybrid Multi-Head Attention for Weak-Supervised Temporal Action Localization
Dec 27, 2024Weakly supervised temporal action localization (WS-TAL) is a task of targeting at localizing complete action instances and categorizing them with video-level labels. Action-background ambiguity, primarily caused by background noise resulting from aggregation and intra-action variation, is a significant challenge for existing WS-TAL methods. In this paper, we introduce a hybrid multi-head attention (HMHA) module and generalized uncertainty-based evidential fusion (GUEF) module to address the problem. The proposed HMHA effectively enhances RGB and optical flow features by filtering redundant information and adjusting their feature distribution to better align with the WS-TAL task. Additionally, the proposed GUEF adaptively eliminates the interference of background noise by fusing snippet-level evidences to refine uncertainty measurement and select superior foreground feature information, which enables the model to concentrate on integral action instances to achieve better action localization and classification performance. Experimental results conducted on the THUMOS14 dataset demonstrate that our method outperforms state-of-the-art methods. Our code is available in \url{https://github.com/heyuanpengpku/GUEF/tree/main}.
Residual Feature-Reutilization Inception Network for Image Classification
Dec 27, 2024Capturing feature information effectively is of great importance in the field of computer vision. With the development of convolutional neural networks (CNNs), concepts like residual connection and multiple scales promote continual performance gains in diverse deep learning vision tasks. In this paper, we propose a novel CNN architecture that it consists of residual feature-reutilization inceptions (ResFRI) or split-residual feature-reutilization inceptions (Split-ResFRI). And it is composed of four convolutional combinations of different structures connected by specially designed information interaction passages, which are utilized to extract multi-scale feature information and effectively increase the receptive field of the model. Moreover, according to the network structure designed above, Split-ResFRI can adjust the segmentation ratio of the input information, thereby reducing the number of parameters and guaranteeing the model performance. Specifically, in experiments based on popular vision datasets, such as CIFAR10 ($97.94$\%), CIFAR100 ($85.91$\%) and Tiny Imagenet ($70.54$\%), we obtain state-of-the-art results compared with other modern models under the premise that the model size is approximate and no additional data is used.
Why language models collapse when trained on recursively generated text
Dec 19, 2024



Language models (LMs) have been widely used to generate text on the Internet. The generated text is often collected into the training corpus of the next generations of LMs. Previous work has experimentally found that LMs collapse when trained on recursively generated text. This paper contributes to existing knowledge from two aspects. We present a theoretical proof of LM collapse. Our proof reveals the cause of LM collapse and proves that all auto-regressive LMs will definitely collapse. We present a new finding: the performance of LMs gradually declines when trained on recursively generated text until they perform no better than a randomly initialized LM. The trained LMs produce large amounts of repetitive text and perform poorly across a wide range of natural language tasks. The above proof and new findings deepen our understanding of LM collapse and offer valuable insights that may inspire new training techniques to mitigate this threat.
Exploring LLM-based Data Annotation Strategies for Medical Dialogue Preference Alignment
Oct 05, 2024


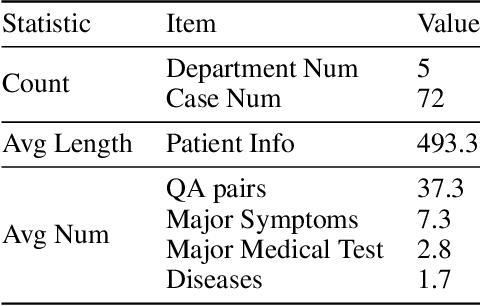
This research examines the use of Reinforcement Learning from AI Feedback (RLAIF) techniques to improve healthcare dialogue models, with the aim of tackling the challenges of preference-aligned data annotation while reducing the reliance on medical experts. We argue that the primary challenges in current RLAIF research for healthcare are the limitations of automated evaluation methods and the difficulties in accurately representing physician preferences. To address these challenges, we present a new evaluation framework based on standardized patient examinations. This framework is designed to objectively assess the effectiveness of large language models (LLMs) in guiding users and following instructions, enabling a comprehensive comparison across different models. Furthermore, our investigation of effective ways to express physician preferences using Constitutional AI algorithms highlighted the particular effectiveness of flowcharts. Utilizing this finding, we introduce an innovative agent-based approach for annotating preference data. This approach autonomously creates medical dialogue flows tailored to the patient's condition, demonstrates strong generalization abilities, and reduces the need for expert involvement. Our results show that the agent-based approach outperforms existing RLAIF annotation methods in standardized patient examinations and surpasses current open source medical dialogue LLMs in various test scenarios.