 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring LLM-based Data Annotation Strategies for Medical Dialogue Preference Alignment
Paper and Code



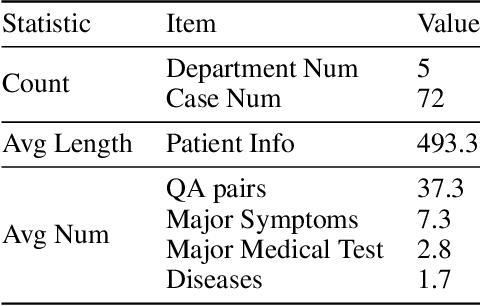
This research examines the use of Reinforcement Learning from AI Feedback (RLAIF) techniques to improve healthcare dialogue models, with the aim of tackling the challenges of preference-aligned data annotation while reducing the reliance on medical experts. We argue that the primary challenges in current RLAIF research for healthcare are the limitations of automated evaluation methods and the difficulties in accurately representing physician preferences. To address these challenges, we present a new evaluation framework based on standardized patient examinations. This framework is designed to objectively assess the effectiveness of large language models (LLMs) in guiding users and following instructions, enabling a comprehensive comparison across different models. Furthermore, our investigation of effective ways to express physician preferences using Constitutional AI algorithms highlighted the particular effectiveness of flowcharts. Utilizing this finding, we introduce an innovative agent-based approach for annotating preference data. This approach autonomously creates medical dialogue flows tailored to the patient's condition, demonstrates strong generalization abilities, and reduces the need for expert involvement. Our results show that the agent-based approach outperforms existing RLAIF annotation methods in standardized patient examinations and surpasses current open source medical dialogue LLMs in various test scenarios.