 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Anywhere in Code Generation
Apr 02, 2026Recent advances in reasoning Large Language Models (LLMs) have primarily relied on upfront thinking, where reasoning occurs before final answer. However, this approach suffers from critical limitations in code generation, where upfront thinking is often insufficient as problems' full complexity only reveals itself during code implementation. Moreover, it cannot adaptively allocate reasoning effort throughout the code generation process where difficulty varies significantly. In this paper, we propose Think-Anywhere, a novel reasoning mechanism that enables LLMs to invoke thinking on-demand at any token position during code generation. We achieve Think-Anywhere by first teaching LLMs to imitate the reasoning patterns through cold-start training, then leveraging outcome-based RL rewards to drive the model's autonomous exploration of when and where to invoke reasoning. Extensive experiments on four mainstream code generation benchmarks (i.e., LeetCode, LiveCodeBench, HumanEval, and MBPP) show that Think-Anywhere achieves state-of-the-art performance over both existing reasoning methods and recent post-training approaches, while demonstrating consistent generalization across diverse LLMs. Our analysis further reveals that Think-Anywhere enables the model to adaptively invoke reasoning at high-entropy positions, providing enhanced interpretability.
Your Inference Request Will Become a Black Box: Confidential Inference for Cloud-based Large Language Models
Feb 27, 2026The increasing reliance on cloud-hosted Large Language Models (LLMs) exposes sensitive client data, such as prompts and responses, to potential privacy breaches by service providers. Existing approaches fail to ensure privacy, maintain model performance, and preserve computational efficiency simultaneously. To address this challenge, we propose Talaria, a confidential inference framework that partitions the LLM pipeline to protect client data without compromising the cloud's model intellectual property or inference quality. Talaria executes sensitive, weight-independent operations within a client-controlled Confidential Virtual Machine (CVM) while offloading weight-dependent computations to the cloud GPUs. The interaction between these environments is secured by our Reversible Masked Outsourcing (ReMO) protocol, which uses a hybrid masking technique to reversibly obscure intermediate data before outsourcing computations. Extensive evaluations show that Talaria can defend against state-of-the-art token inference attacks, reducing token reconstruction accuracy from over 97.5% to an average of 1.34%, all while being a lossless mechanism that guarantees output identical to the original model without significantly decreasing efficiency and scalability. To the best of our knowledge, this is the first work that ensures clients' prompts and responses remain inaccessible to the cloud, while also preserving model privacy, performance, and efficiency.
FastPhysGS: Accelerating Physics-based Dynamic 3DGS Simulation via Interior Completion and Adaptive Optimization
Feb 02, 2026Extending 3D Gaussian Splatting (3DGS) to 4D physical simulation remains challenging. Based on the Material Point Method (MPM), existing methods either rely on manual parameter tuning or distill dynamics from video diffusion models, limiting the generalization and optimization efficiency. Recent attempts using LLMs/VLMs suffer from a text/image-to-3D perceptual gap, yielding unstable physics behavior. In addition, they often ignore the surface structure of 3DGS, leading to implausible motion. We propose FastPhysGS, a fast and robust framework for physics-based dynamic 3DGS simulation:(1) Instance-aware Particle Filling (IPF) with Monte Carlo Importance Sampling (MCIS) to efficiently populate interior particles while preserving geometric fidelity; (2) Bidirectional Graph Decoupling Optimization (BGDO), an adaptive strategy that rapidly optimizes material parameters predicted from a VLM. Experiments show FastPhysGS achieves high-fidelity physical simulation in 1 minute using only 7 GB runtime memory, outperforming prior works with broad potential applications.
Unifying Heterogeneous Degradations: Uncertainty-Aware Diffusion Bridge Model for All-in-One Image Restoration
Jan 29, 2026All-in-One Image Restoration (AiOIR) faces the fundamental challenge in reconciling conflicting optimization objectives across heterogeneous degradations. Existing methods are often constrained by coarse-grained control mechanisms or fixed mapping schedules, yielding suboptimal adaptation. To address this, we propose an Uncertainty-Aware Diffusion Bridge Model (UDBM), which innovatively reformulates AiOIR as a stochastic transport problem steered by pixel-wise uncertainty. By introducing a relaxed diffusion bridge formulation which replaces the strict terminal constraint with a relaxed constraint, we model the uncertainty of degradations while theoretically resolving the drift singularity inherent in standard diffusion bridges. Furthermore, we devise a dual modulation strategy: the noise schedule aligns diverse degradations into a shared high-entropy latent space, while the path schedule adaptively regulates the transport trajectory motivated by the viscous dynamics of entropy regularization. By effectively rectifying the transport geometry and dynamics, UDBM achieves state-of-the-art performance across diverse restoration tasks within a single inference step.
KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
Jan 19, 2026Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.
Weights to Code: Extracting Interpretable Algorithms from the Discrete Transformer
Jan 09, 2026Algorithm extraction aims to synthesize executable programs directly from models trained on specific algorithmic tasks, enabling de novo algorithm discovery without relying on human-written code. However, extending this paradigm to Transformer is hindered by superposition, where entangled features encoded in overlapping directions obstruct the extraction of symbolic expressions. In this work, we propose the Discrete Transformer, an architecture explicitly engineered to bridge the gap between continuous representations and discrete symbolic logic. By enforcing a strict functional disentanglement, which constrains Numerical Attention to information routing and Numerical MLP to element-wise arithmetic, and employing temperature-annealed sampling, our method effectively facilitates the extraction of human-readable programs. Empirically, the Discrete Transformer not only achieves performance comparable to RNN-based baselines but crucially extends interpretability to continuous variable domains. Moreover, our analysis of the annealing process shows that the efficient discrete search undergoes a clear phase transition from exploration to exploitation. We further demonstrate that our method enables fine-grained control over synthesized programs by imposing inductive biases. Collectively, these findings establish the Discrete Transformer as a robust framework for demonstration-free algorithm discovery, offering a rigorous pathway toward Transformer interpretability.
GUI-ARP: Enhancing Grounding with Adaptive Region Perception for GUI Agents
Sep 19, 2025Existing GUI grounding methods often struggle with fine-grained localization in high-resolution screenshots. To address this, we propose GUI-ARP, a novel framework that enables adaptive multi-stage inference. Equipped with the proposed Adaptive Region Perception (ARP) and Adaptive Stage Controlling (ASC), GUI-ARP dynamically exploits visual attention for cropping task-relevant regions and adapts its inference strategy, performing a single-stage inference for simple cases and a multi-stage analysis for more complex scenarios. This is achieved through a two-phase training pipeline that integrates supervised fine-tuning with reinforcement fine-tuning based on Group Relative Policy Optimization (GRPO). Extensive experiments demonstrate that the proposed GUI-ARP achieves state-of-the-art performance on challenging GUI grounding benchmarks, with a 7B model reaching 60.8% accuracy on ScreenSpot-Pro and 30.9% on UI-Vision benchmark. Notably, GUI-ARP-7B demonstrates strong competitiveness against open-source 72B models (UI-TARS-72B at 38.1%) and proprietary models.
Rethinking Testing for LLM Applications: Characteristics, Challenges, and a Lightweight Interaction Protocol
Aug 28, 2025Applications of Large Language Models~(LLMs) have evolved from simple text generators into complex software systems that integrate retrieval augmentation, tool invocation, and multi-turn interactions. Their inherent non-determinism, dynamism, and context dependence pose fundamental challenges for quality assurance. This paper decomposes LLM applications into a three-layer architecture: \textbf{\textit{System Shell Layer}}, \textbf{\textit{Prompt Orchestration Layer}}, and \textbf{\textit{LLM Inference Core}}. We then assess the applicability of traditional software testing methods in each layer: directly applicable at the shell layer, requiring semantic reinterpretation at the orchestration layer, and necessitating paradigm shifts at the inference core. A comparative analysis of Testing AI methods from the software engineering community and safety analysis techniques from the AI community reveals structural disconnects in testing unit abstraction, evaluation metrics, and lifecycle management. We identify four fundamental differences that underlie 6 core challenges. To address these, we propose four types of collaborative strategies (\emph{Retain}, \emph{Translate}, \emph{Integrate}, and \emph{Runtime}) and explore a closed-loop, trustworthy quality assurance framework that combines pre-deployment validation with runtime monitoring. Based on these strategies, we offer practical guidance and a protocol proposal to support the standardization and tooling of LLM application testing. We propose a protocol \textbf{\textit{Agent Interaction Communication Language}} (AICL) that is used to communicate between AI agents. AICL has the test-oriented features and is easily integrated in the current agent framework.
RPD-Diff: Region-Adaptive Physics-Guided Diffusion Model for Visibility Enhancement under Dense and Non-Uniform Haze
Aug 23, 2025Single-image dehazing under dense and non-uniform haze conditions remains challenging due to severe information degradation and spatial heterogeneity. Traditional diffusion-based dehazing methods struggle with insufficient generation conditioning and lack of adaptability to spatially varying haze distributions, which leads to suboptimal restoration. To address these limitations, we propose RPD-Diff, a Region-adaptive Physics-guided Dehazing Diffusion Model for robust visibility enhancement in complex haze scenarios. RPD-Diff introduces a Physics-guided Intermediate State Targeting (PIST) strategy, which leverages physical priors to reformulate the diffusion Markov chain by generation target transitions, mitigating the issue of insufficient conditioning in dense haze scenarios. Additionally, the Haze-Aware Denoising Timestep Predictor (HADTP) dynamically adjusts patch-specific denoising timesteps employing a transmission map cross-attention mechanism, adeptly managing non-uniform haze distributions. Extensive experiments across four real-world datasets demonstrate that RPD-Diff achieves state-of-the-art performance in challenging dense and non-uniform haze scenarios, delivering high-quality, haze-free images with superior detail clarity and color fidelity.
A Survey on Code Generation with LLM-based Agents
Jul 31, 2025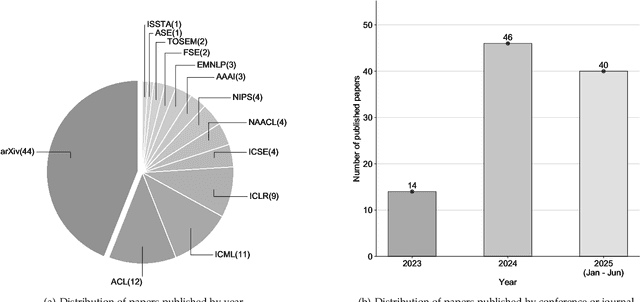
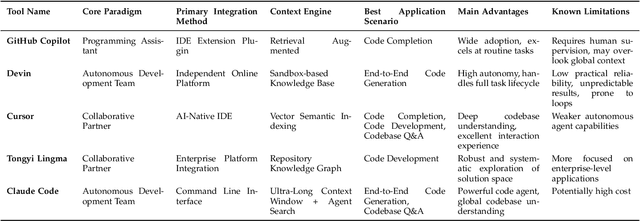
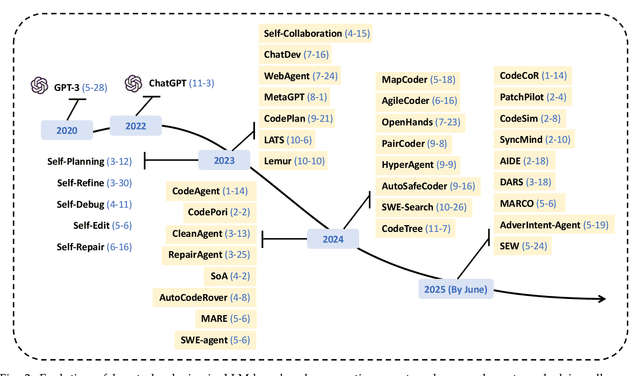
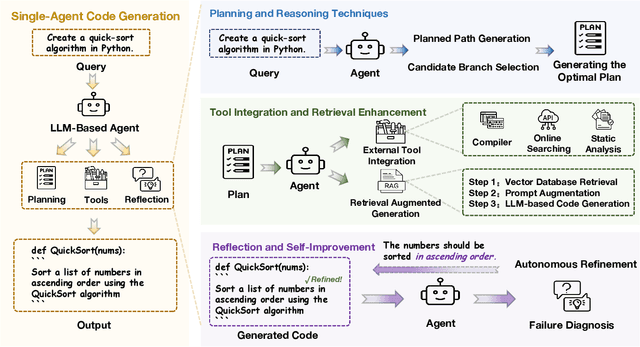
Code generation agents powered by large language models (LLMs) are revolutionizing the software development paradigm. Distinct from previous code generation techniques, code generation agents are characterized by three core features. 1) Autonomy: the ability to independently manage the entire workflow, from task decomposition to coding and debugging. 2) Expanded task scope: capabilities that extend beyond generating code snippets to encompass the full software development lifecycle (SDLC). 3) Enhancement of engineering practicality: a shift in research emphasis from algorithmic innovation toward practical engineering challenges, such as system reliability, process management, and tool integration. This domain has recently witnessed rapid development and an explosion in research, demonstrating significant application potential. This paper presents a systematic survey of the field of LLM-based code generation agents. We trace the technology's developmental trajectory from its inception and systematically categorize its core techniques, including both single-agent and multi-agent architectures. Furthermore, this survey details the applications of LLM-based agents across the full SDLC, summarizes mainstream evaluation benchmarks and metrics, and catalogs representative tools. Finally, by analyzing the primary challenges, we identify and propose several foundational, long-term research directions for the future work of the field.