 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making
Feb 06, 2026We introduce Baichuan-M3, a medical-enhanced large language model engineered to shift the paradigm from passive question-answering to active, clinical-grade decision support. Addressing the limitations of existing systems in open-ended consultations, Baichuan-M3 utilizes a specialized training pipeline to model the systematic workflow of a physician. Key capabilities include: (i) proactive information acquisition to resolve ambiguity; (ii) long-horizon reasoning that unifies scattered evidence into coherent diagnoses; and (iii) adaptive hallucination suppression to ensure factual reliability. Empirical evaluations demonstrate that Baichuan-M3 achieves state-of-the-art results on HealthBench, the newly introduced HealthBench-Hallu and ScanBench, significantly outperforming GPT-5.2 in clinical inquiry, advisory and safety. The models are publicly available at https://huggingface.co/collections/baichuan-inc/baichuan-m3.
PROPHET: An Inferable Future Forecasting Benchmark with Causal Intervened Likelihood Estimation
Apr 02, 2025Predicting future events stands as one of the ultimate aspirations of artificial intelligence. Recent advances in large language model (LLM)-based systems have shown remarkable potential in forecasting future events, thereby garnering significant interest in the research community. Currently, several benchmarks have been established to evaluate the forecasting capabilities by formalizing the event prediction as a retrieval-augmented generation (RAG) and reasoning task. In these benchmarks, each prediction question is answered with relevant retrieved news articles. However, because there is no consideration on whether the questions can be supported by valid or sufficient supporting rationales, some of the questions in these benchmarks may be inherently noninferable. To address this issue, we introduce a new benchmark, PROPHET, which comprises inferable forecasting questions paired with relevant news for retrieval. To ensure the inferability of the benchmark, we propose Causal Intervened Likelihood (CIL), a statistical measure that assesses inferability through causal inference. In constructing this benchmark, we first collected recent trend forecasting questions and then filtered the data using CIL, resulting in an inferable benchmark for event prediction. Through extensive experiments, we first demonstrate the validity of CIL and in-depth investigations into event prediction with the aid of CIL. Subsequently, we evaluate several representative prediction systems on PROPHET, drawing valuable insights for future directions.
Enhancing LLM Generation with Knowledge Hypergraph for Evidence-Based Medicine
Mar 18, 2025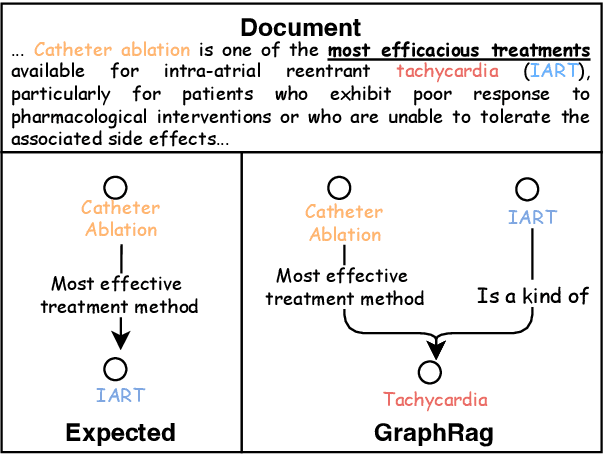
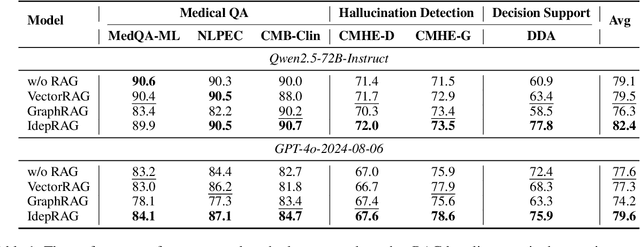
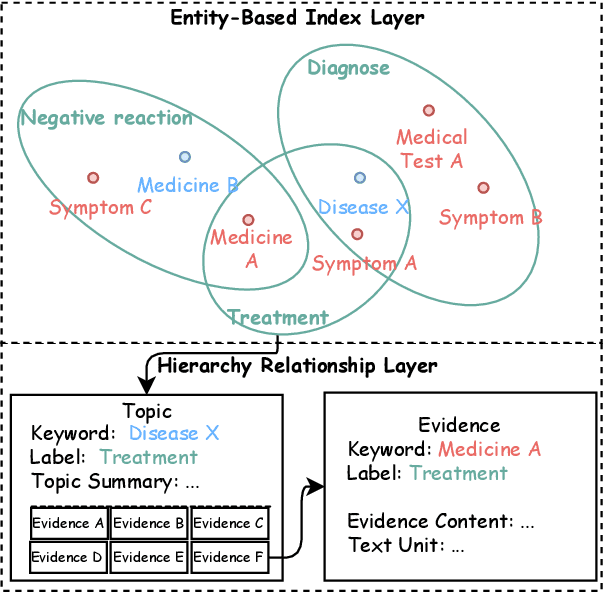
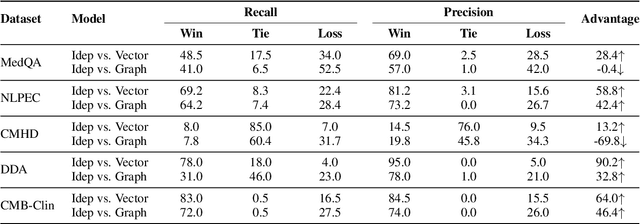
Evidence-based medicine (EBM) plays a crucial role in the application of large language models (LLMs) in healthcare, as it provides reliable support for medical decision-making processes. Although it benefits from current retrieval-augmented generation~(RAG) technologies, it still faces two significant challenges: the collection of dispersed evidence and the efficient organization of this evidence to support the complex queries necessary for EBM. To tackle these issues, we propose using LLMs to gather scattered evidence from multiple sources and present a knowledge hypergraph-based evidence management model to integrate these evidence while capturing intricate relationships. Furthermore, to better support complex queries, we have developed an Importance-Driven Evidence Prioritization (IDEP) algorithm that utilizes the LLM to generate multiple evidence features, each with an associated importance score, which are then used to rank the evidence and produce the final retrieval results. Experimental results from six datasets demonstrate that our approach outperforms existing RAG techniques in application domains of interest to EBM, such as medical quizzing, hallucination detection, and decision support. Testsets and the constructed knowledge graph can be accessed at \href{https://drive.google.com/file/d/1WJ9QTokK3MdkjEmwuFQxwH96j_Byawj_/view?usp=drive_link}{https://drive.google.com/rag4ebm}.
Exploring LLM-based Data Annotation Strategies for Medical Dialogue Preference Alignment
Oct 05, 2024


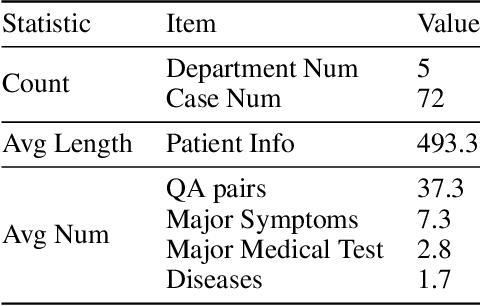
This research examines the use of Reinforcement Learning from AI Feedback (RLAIF) techniques to improve healthcare dialogue models, with the aim of tackling the challenges of preference-aligned data annotation while reducing the reliance on medical experts. We argue that the primary challenges in current RLAIF research for healthcare are the limitations of automated evaluation methods and the difficulties in accurately representing physician preferences. To address these challenges, we present a new evaluation framework based on standardized patient examinations. This framework is designed to objectively assess the effectiveness of large language models (LLMs) in guiding users and following instructions, enabling a comprehensive comparison across different models. Furthermore, our investigation of effective ways to express physician preferences using Constitutional AI algorithms highlighted the particular effectiveness of flowcharts. Utilizing this finding, we introduce an innovative agent-based approach for annotating preference data. This approach autonomously creates medical dialogue flows tailored to the patient's condition, demonstrates strong generalization abilities, and reduces the need for expert involvement. Our results show that the agent-based approach outperforms existing RLAIF annotation methods in standardized patient examinations and surpasses current open source medical dialogue LLMs in various test scenarios.
Integrating Physician Diagnostic Logic into Large Language Models: Preference Learning from Process Feedback
Jan 11, 2024The use of large language models in medical dialogue generation has garnered significant attention, with a focus on improving response quality and fluency. While previous studies have made progress in optimizing model performance for single-round medical Q&A tasks, there is a need to enhance the model's capability for multi-round conversations to avoid logical inconsistencies. To address this, we propose an approach called preference learning from process feedback~(PLPF), which integrates the doctor's diagnostic logic into LLMs. PLPF involves rule modeling, preference data generation, and preference alignment to train the model to adhere to the diagnostic process. Experimental results using Standardized Patient Testing show that PLPF enhances the diagnostic accuracy of the baseline model in medical conversations by 17.6%, outperforming traditional reinforcement learning from human feedback. Additionally, PLPF demonstrates effectiveness in both multi-round and single-round dialogue tasks, showcasing its potential for improving medical dialogue generation.
Enhancing the Spatial Awareness Capability of Multi-Modal Large Language Model
Nov 01, 2023The Multi-Modal Large Language Model (MLLM) refers to an extension of the Large Language Model (LLM) equipped with the capability to receive and infer multi-modal data. Spatial awareness stands as one of the crucial abilities of MLLM, encompassing diverse skills related to understanding spatial relationships among objects and between objects and the scene area. Industries such as autonomous driving, smart healthcare, robotics, virtual, and augmented reality heavily demand MLLM's spatial awareness capabilities. However, there exists a noticeable gap between the current spatial awareness capabilities of MLLM and the requirements set by human needs. To address this issue, this paper proposes using more precise spatial position information between objects to guide MLLM in providing more accurate responses to user-related inquiries. Specifically, for a particular multi-modal task, we utilize algorithms for acquiring geometric spatial information and scene graphs to obtain relevant geometric spatial information and scene details of objects involved in the query. Subsequently, based on this information, we direct MLLM to address spatial awareness-related queries posed by the user. Extensive experiments were conducted in benchmarks such as MME, MM-Vet, and other multi-modal large language models. The experimental results thoroughly confirm the efficacy of the proposed method in enhancing the spatial awareness tasks and associated tasks of MLLM.
Plug-and-Play Medical Dialogue System
May 19, 2023Medical dialogue systems aim to provide accurate answers to patients, necessitating specific domain knowledge. Recent advancements in Large Language Models (LLMs) have demonstrated their exceptional capabilities in the medical Q&A domain, indicating a rich understanding of common sense. However, LLMs are insufficient for direct diagnosis due to the absence of diagnostic strategies. The conventional approach to address this challenge involves expensive fine-tuning of LLMs. Alternatively, a more appealing solution is the development of a plugin that empowers LLMs to perform medical conversation tasks. Drawing inspiration from in-context learning, we propose PlugMed, a Plug-and-Play Medical Dialogue System that facilitates appropriate dialogue actions by LLMs through two modules: the prompt generation (PG) module and the response ranking (RR) module. The PG module is designed to capture dialogue information from both global and local perspectives. It selects suitable prompts by assessing their similarity to the entire dialogue history and recent utterances grouped by patient symptoms, respectively. Additionally, the RR module incorporates fine-tuned SLMs as response filters and selects appropriate responses generated by LLMs. Moreover, we devise a novel evaluation method based on intent and medical entities matching to assess the efficacy of dialogue strategies in medical conversations more effectively. Experimental evaluations conducted on three unlabeled medical dialogue datasets, including both automatic and manual assessments, demonstrate that our model surpasses the strong fine-tuning baselines.