 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Spatial Awareness Capability of Multi-Modal Large Language Model
Nov 01, 2023The Multi-Modal Large Language Model (MLLM) refers to an extension of the Large Language Model (LLM) equipped with the capability to receive and infer multi-modal data. Spatial awareness stands as one of the crucial abilities of MLLM, encompassing diverse skills related to understanding spatial relationships among objects and between objects and the scene area. Industries such as autonomous driving, smart healthcare, robotics, virtual, and augmented reality heavily demand MLLM's spatial awareness capabilities. However, there exists a noticeable gap between the current spatial awareness capabilities of MLLM and the requirements set by human needs. To address this issue, this paper proposes using more precise spatial position information between objects to guide MLLM in providing more accurate responses to user-related inquiries. Specifically, for a particular multi-modal task, we utilize algorithms for acquiring geometric spatial information and scene graphs to obtain relevant geometric spatial information and scene details of objects involved in the query. Subsequently, based on this information, we direct MLLM to address spatial awareness-related queries posed by the user. Extensive experiments were conducted in benchmarks such as MME, MM-Vet, and other multi-modal large language models. The experimental results thoroughly confirm the efficacy of the proposed method in enhancing the spatial awareness tasks and associated tasks of MLLM.
Enhancing Subtask Performance of Multi-modal Large Language Model
Aug 31, 2023
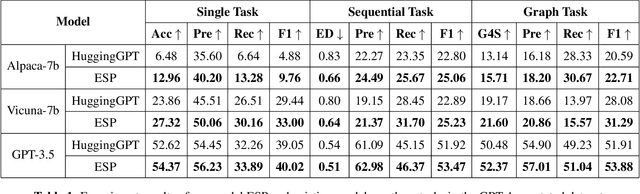
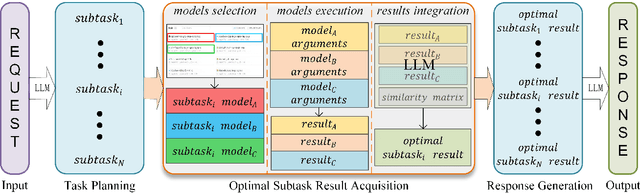
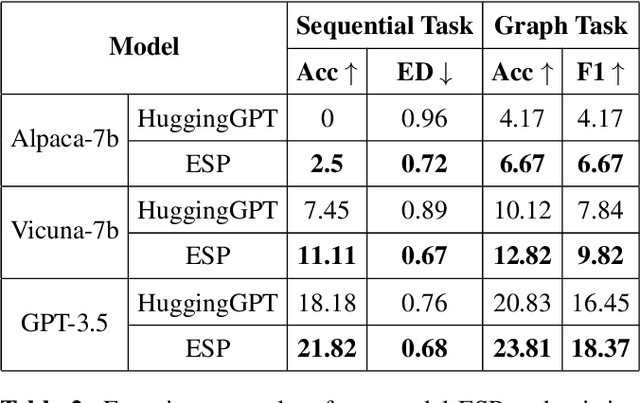
Multi-modal Large Language Model (MLLM) refers to a model expanded from a Large Language Model (LLM) that possesses the capability to handle and infer multi-modal data. Current MLLMs typically begin by using LLMs to decompose tasks into multiple subtasks, then employing individual pre-trained models to complete specific subtasks, and ultimately utilizing LLMs to integrate the results of each subtasks to obtain the results of the task. In real-world scenarios, when dealing with large projects, it is common practice to break down the project into smaller sub-projects, with different teams providing corresponding solutions or results. The project owner then decides which solution or result to use, ensuring the best possible outcome for each subtask and, consequently, for the entire project. Inspired by this, this study considers selecting multiple pre-trained models to complete the same subtask. By combining the results from multiple pre-trained models, the optimal subtask result is obtained, enhancing the performance of the MLLM. Specifically, this study first selects multiple pre-trained models focused on the same subtask based on distinct evaluation approaches, and then invokes these models in parallel to process input data and generate corresponding subtask results. Finally, the results from multiple pre-trained models for the same subtask are compared using the LLM, and the best result is chosen as the outcome for that subtask. Extensive experiments are conducted in this study using GPT-4 annotated datasets and human-annotated datasets. The results of various evaluation metrics adequately demonstrate the effectiveness of the proposed approach in this paper.