 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCVR Scene Generation: High Compatibility Virtual Reality Environment Generation for Extended Redirected Walking
Jan 21, 2026Natural walking enhances immersion in virtual environments (VEs), but physical space limitations and obstacles hinder exploration, especially in large virtual scenes. Redirected Walking (RDW) techniques mitigate this by subtly manipulating the virtual camera to guide users away from physical collisions within pre-defined VEs. However, RDW efficacy diminishes significantly when substantial geometric divergence exists between the physical and virtual environments, leading to unavoidable collisions. Existing scene generation methods primarily focus on object relationships or layout aesthetics, often neglecting the crucial aspect of physical compatibility required for effective RDW. To address this, we introduce HCVR (High Compatibility Virtual Reality Environment Generation), a novel framework that generates virtual scenes inherently optimized for alignment-based RDW controllers. HCVR first employs ENI++, a novel, boundary-sensitive metric to evaluate the incompatibility between physical and virtual spaces by comparing rotation-sensitive visibility polygons. Guided by the ENI++ compatibility map and user prompts, HCVR utilizes a Large Language Model (LLM) for context-aware 3D asset retrieval and initial layout generation. The framework then strategically adjusts object selection, scaling, and placement to maximize coverage of virtually incompatible regions, effectively guiding users towards RDW-feasible paths. User studies evaluating physical collisions and layout quality demonstrate HCVR's effectiveness with HCVR-generated scenes, resulting in 22.78 times fewer physical collisions and received 35.89\% less on ENI++ score compared to LLM-based generation with RDW, while also receiving 12.5\% higher scores on user feedback to layout design.
Global Context Compression with Interleaved Vision-Text Transformation
Jan 15, 2026Recent achievements of vision-language models in end-to-end OCR point to a new avenue for low-loss compression of textual information. This motivates earlier works that render the Transformer's input into images for prefilling, which effectively reduces the number of tokens through visual encoding, thereby alleviating the quadratically increased Attention computations. However, this partial compression fails to save computational or memory costs at token-by-token inference. In this paper, we investigate global context compression, which saves tokens at both prefilling and inference stages. Consequently, we propose VIST2, a novel Transformer that interleaves input text chunks alongside their visual encoding, while depending exclusively on visual tokens in the pre-context to predict the next text token distribution. Around this idea, we render text chunks into sketch images and train VIST2 in multiple stages, starting from curriculum-scheduled pretraining for optical language modeling, followed by modal-interleaved instruction tuning. We conduct extensive experiments using VIST2 families scaled from 0.6B to 8B to explore the training recipe and hyperparameters. With a 4$\times$ compression ratio, the resulting models demonstrate significant superiority over baselines on long writing tasks, achieving, on average, a 3$\times$ speedup in first-token generation, 77% reduction in memory usage, and 74% reduction in FLOPS. Our codes and datasets will be public to support further studies.
CogMem: A Cognitive Memory Architecture for Sustained Multi-Turn Reasoning in Large Language Models
Dec 16, 2025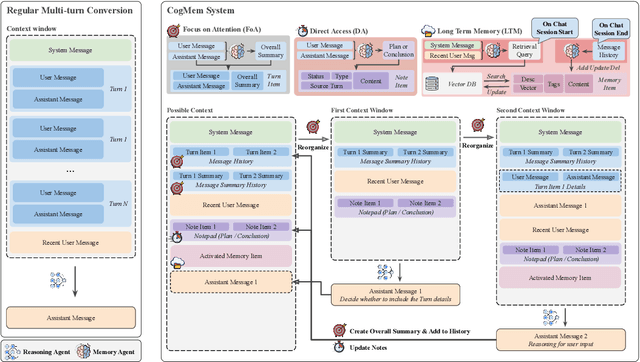
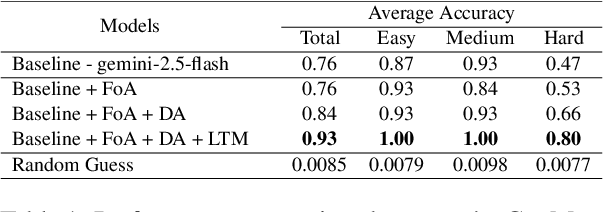
Large language models (LLMs) excel at single-turn reasoning but often lose accuracy and coherence over extended, multi-turn interactions. Recent evaluations such as TurnBench highlight recurring failure modes-reasoning bias, task drift, hallucination, overconfidence, and memory decay. Current approaches typically append full conversational histories, causing unbounded context growth, higher computational costs, and degraded reasoning efficiency. We introduce CogMem, a cognitively inspired, memory-augmented LLM architecture that supports sustained iterative reasoning through structured, persistent memory. CogMem incorporates three layers: a Long-Term Memory (LTM) that consolidates cross-session reasoning strategies; a Direct Access (DA) memory that maintains session-level notes and retrieves relevant long-term memories; and a Focus of Attention (FoA) mechanism that dynamically reconstructs concise, task-relevant context at each turn. Experiments on TurnBench show that this layered design mitigates reasoning failures, controls context growth, and improves consistency across extended reasoning chains, moving toward more reliable, human-like reasoning in LLMs.
Beyond the Black Box: Demystifying Multi-Turn LLM Reasoning with VISTA
Nov 13, 2025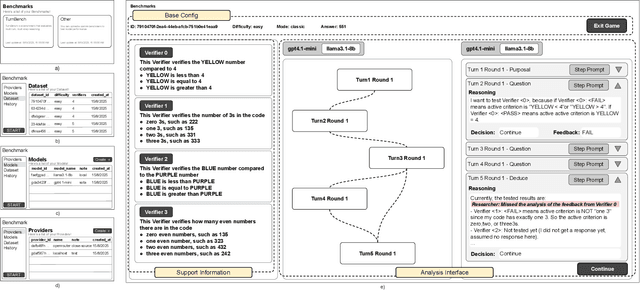
Recent research has increasingly focused on the reasoning capabilities of Large Language Models (LLMs) in multi-turn interactions, as these scenarios more closely mirror real-world problem-solving. However, analyzing the intricate reasoning processes within these interactions presents a significant challenge due to complex contextual dependencies and a lack of specialized visualization tools, leading to a high cognitive load for researchers. To address this gap, we present VISTA, an web-based Visual Interactive System for Textual Analytics in multi-turn reasoning tasks. VISTA allows users to visualize the influence of context on model decisions and interactively modify conversation histories to conduct "what-if" analyses across different models. Furthermore, the platform can automatically parse a session and generate a reasoning dependency tree, offering a transparent view of the model's step-by-step logical path. By providing a unified and interactive framework, VISTA significantly reduces the complexity of analyzing reasoning chains, thereby facilitating a deeper understanding of the capabilities and limitations of current LLMs. The platform is open-source and supports easy integration of custom benchmarks and local models.
Reinforcing Multimodal Understanding and Generation with Dual Self-rewards
Jun 09, 2025Building upon large language models (LLMs), recent large multimodal models (LMMs) unify cross-model understanding and generation into a single framework. However, LMMs still struggle to achieve accurate image-text alignment, prone to generating text responses contradicting the visual input or failing to follow the text-to-image prompts. Current solutions require external supervision (e.g., human feedback or reward models) and only address unidirectional tasks-either understanding or generation. In this work, based on the observation that understanding and generation are inverse dual tasks, we introduce a self-supervised dual reward mechanism to reinforce the understanding and generation capabilities of LMMs. Specifically, we sample multiple outputs for a given input in one task domain, then reverse the input-output pairs to compute the dual likelihood of the model as self-rewards for optimization. Extensive experimental results on visual understanding and generation benchmarks demonstrate that our method can effectively enhance the performance of the model without any external supervision, especially achieving remarkable improvements in text-to-image tasks.
Origin Tracer: A Method for Detecting LoRA Fine-Tuning Origins in LLMs
May 26, 2025As large language models (LLMs) continue to advance, their deployment often involves fine-tuning to enhance performance on specific downstream tasks. However, this customization is sometimes accompanied by misleading claims about the origins, raising significant concerns about transparency and trust within the open-source community. Existing model verification techniques typically assess functional, representational, and weight similarities. However, these approaches often struggle against obfuscation techniques, such as permutations and scaling transformations. To address this limitation, we propose a novel detection method Origin-Tracer that rigorously determines whether a model has been fine-tuned from a specified base model. This method includes the ability to extract the LoRA rank utilized during the fine-tuning process, providing a more robust verification framework. This framework is the first to provide a formalized approach specifically aimed at pinpointing the sources of model fine-tuning. We empirically validated our method on thirty-one diverse open-source models under conditions that simulate real-world obfuscation scenarios. We empirically analyze the effectiveness of our framework and finally, discuss its limitations. The results demonstrate the effectiveness of our approach and indicate its potential to establish new benchmarks for model verification.
From Generation to Detection: A Multimodal Multi-Task Dataset for Benchmarking Health Misinformation
May 24, 2025Infodemics and health misinformation have significant negative impact on individuals and society, exacerbating confusion and increasing hesitancy in adopting recommended health measures. Recent advancements in generative AI, capable of producing realistic, human like text and images, have significantly accelerated the spread and expanded the reach of health misinformation, resulting in an alarming surge in its dissemination. To combat the infodemics, most existing work has focused on developing misinformation datasets from social media and fact checking platforms, but has faced limitations in topical coverage, inclusion of AI generation, and accessibility of raw content. To address these issues, we present MM Health, a large scale multimodal misinformation dataset in the health domain consisting of 34,746 news article encompassing both textual and visual information. MM Health includes human-generated multimodal information (5,776 articles) and AI generated multimodal information (28,880 articles) from various SOTA generative AI models. Additionally, We benchmarked our dataset against three tasks (reliability checks, originality checks, and fine-grained AI detection) demonstrating that existing SOTA models struggle to accurately distinguish the reliability and origin of information. Our dataset aims to support the development of misinformation detection across various health scenarios, facilitating the detection of human and machine generated content at multimodal levels.
Commenting Higher-level Code Unit: Full Code, Reduced Code, or Hierarchical Code Summarization
Mar 13, 2025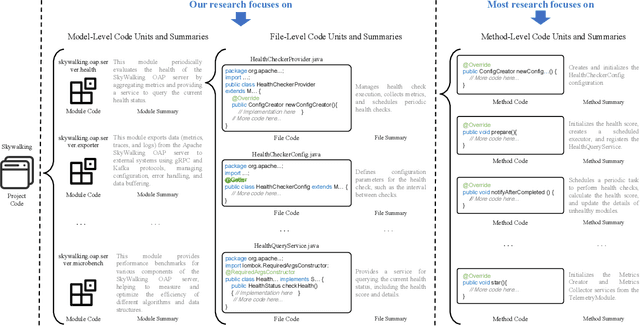

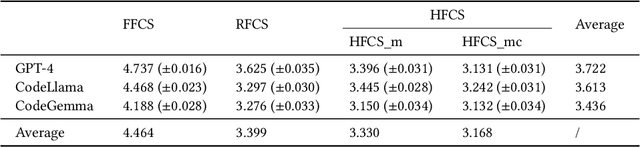

Commenting code is a crucial activity in software development, as it aids in facilitating future maintenance and updates. To enhance the efficiency of writing comments and reduce developers' workload, researchers has proposed various automated code summarization (ACS) techniques to automatically generate comments/summaries for given code units. However, these ACS techniques primarily focus on generating summaries for code units at the method level. There is a significant lack of research on summarizing higher-level code units, such as file-level and module-level code units, despite the fact that summaries of these higher-level code units are highly useful for quickly gaining a macro-level understanding of software components and architecture. To fill this gap, in this paper, we conduct a systematic study on how to use LLMs for commenting higher-level code units, including file level and module level. These higher-level units are significantly larger than method-level ones, which poses challenges in handling long code inputs within LLM constraints and maintaining efficiency. To address these issues, we explore various summarization strategies for ACS of higher-level code units, which can be divided into three types: full code summarization, reduced code summarization, and hierarchical code summarization. The experimental results suggest that for summarizing file-level code units, using the full code is the most effective approach, with reduced code serving as a cost-efficient alternative. However, for summarizing module-level code units, hierarchical code summarization becomes the most promising strategy. In addition, inspired by the research on method-level ACS, we also investigate using the LLM as an evaluator to evaluate the quality of summaries of higher-level code units. The experimental results demonstrate that the LLM's evaluation results strongly correlate with human evaluations.
TrustNavGPT: Modeling Uncertainty to Improve Trustworthiness of Audio-Guided LLM-Based Robot Navigation
Aug 03, 2024



While LLMs are proficient at processing text in human conversations, they often encounter difficulties with the nuances of verbal instructions and, thus, remain prone to hallucinate trust in human command. In this work, we present TrustNavGPT, an LLM based audio guided navigation agent that uses affective cues in spoken communication elements such as tone and inflection that convey meaning beyond words, allowing it to assess the trustworthiness of human commands and make effective, safe decisions. Our approach provides a lightweight yet effective approach that extends existing LLMs to model audio vocal features embedded in the voice command and model uncertainty for safe robotic navigation.
RU-AI: A Large Multimodal Dataset for Machine Generated Content Detection
Jun 07, 2024



The recent advancements in generative AI models, which can create realistic and human-like content, are significantly transforming how people communicate, create, and work. While the appropriate use of generative AI models can benefit the society, their misuse poses significant threats to data reliability and authentication. However, due to a lack of aligned multimodal datasets, effective and robust methods for detecting machine-generated content are still in the early stages of development. In this paper, we introduce RU-AI, a new large-scale multimodal dataset designed for the robust and efficient detection of machine-generated content in text, image, and voice. Our dataset is constructed from three large publicly available datasets: Flickr8K, COCO, and Places205, by combining the original datasets and their corresponding machine-generated pairs. Additionally, experimental results show that our proposed unified model, which incorporates a multimodal embedding module with a multilayer perceptron network, can effectively determine the origin of the data (i.e., original data samples or machine-generated ones) from RU-AI. However, future work is still required to address the remaining challenges posed by RU-AI. The source code and dataset are available at https://github.com/ZhihaoZhang97/RU-AI.