 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUV-M3TL: A Unified and Versatile Multimodal Multi-Task Learning Framework for Assistive Driving Perception
Feb 02, 2026Advanced Driver Assistance Systems (ADAS) need to understand human driver behavior while perceiving their navigation context, but jointly learning these heterogeneous tasks would cause inter-task negative transfer and impair system performance. Here, we propose a Unified and Versatile Multimodal Multi-Task Learning (UV-M3TL) framework to simultaneously recognize driver behavior, driver emotion, vehicle behavior, and traffic context, while mitigating inter-task negative transfer. Our framework incorporates two core components: dual-branch spatial channel multimodal embedding (DB-SCME) and adaptive feature-decoupled multi-task loss (AFD-Loss). DB-SCME enhances cross-task knowledge transfer while mitigating task conflicts by employing a dual-branch structure to explicitly model salient task-shared and task-specific features. AFD-Loss improves the stability of joint optimization while guiding the model to learn diverse multi-task representations by introducing an adaptive weighting mechanism based on learning dynamics and feature decoupling constraints. We evaluate our method on the AIDE dataset, and the experimental results demonstrate that UV-M3TL achieves state-of-the-art performance across all four tasks. To further prove the versatility, we evaluate UV-M3TL on additional public multi-task perception benchmarks (BDD100K, CityScapes, NYUD-v2, and PASCAL-Context), where it consistently delivers strong performance across diverse task combinations, attaining state-of-the-art results on most tasks.
A Human-Oriented Cooperative Driving Approach: Integrating Driving Intention, State, and Conflict
Dec 29, 2025Human-vehicle cooperative driving serves as a vital bridge to fully autonomous driving by improving driving flexibility and gradually building driver trust and acceptance of autonomous technology. To establish more natural and effective human-vehicle interaction, we propose a Human-Oriented Cooperative Driving (HOCD) approach that primarily minimizes human-machine conflict by prioritizing driver intention and state. In implementation, we take both tactical and operational levels into account to ensure seamless human-vehicle cooperation. At the tactical level, we design an intention-aware trajectory planning method, using intention consistency cost as the core metric to evaluate the trajectory and align it with driver intention. At the operational level, we develop a control authority allocation strategy based on reinforcement learning, optimizing the policy through a designed reward function to achieve consistency between driver state and authority allocation. The results of simulation and human-in-the-loop experiments demonstrate that our proposed approach not only aligns with driver intention in trajectory planning but also ensures a reasonable authority allocation. Compared to other cooperative driving approaches, the proposed HOCD approach significantly enhances driving performance and mitigates human-machine conflict.The code is available at https://github.com/i-Qin/HOCD.
SparScene: Efficient Traffic Scene Representation via Sparse Graph Learning for Large-Scale Trajectory Generation
Dec 24, 2025Multi-agent trajectory generation is a core problem for autonomous driving and intelligent transportation systems. However, efficiently modeling the dynamic interactions between numerous road users and infrastructures in complex scenes remains an open problem. Existing methods typically employ distance-based or fully connected dense graph structures to capture interaction information, which not only introduces a large number of redundant edges but also requires complex and heavily parameterized networks for encoding, thereby resulting in low training and inference efficiency, limiting scalability to large and complex traffic scenes. To overcome the limitations of existing methods, we propose SparScene, a sparse graph learning framework designed for efficient and scalable traffic scene representation. Instead of relying on distance thresholds, SparScene leverages the lane graph topology to construct structure-aware sparse connections between agents and lanes, enabling efficient yet informative scene graph representation. SparScene adopts a lightweight graph encoder that efficiently aggregates agent-map and agent-agent interactions, yielding compact scene representations with substantially improved efficiency and scalability. On the motion prediction benchmark of the Waymo Open Motion Dataset (WOMD), SparScene achieves competitive performance with remarkable efficiency. It generates trajectories for more than 200 agents in a scene within 5 ms and scales to more than 5,000 agents and 17,000 lanes with merely 54 ms of inference time with a GPU memory of 2.9 GB, highlighting its superior scalability for large-scale traffic scenes.
Optimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025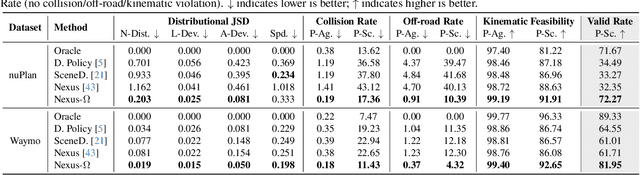
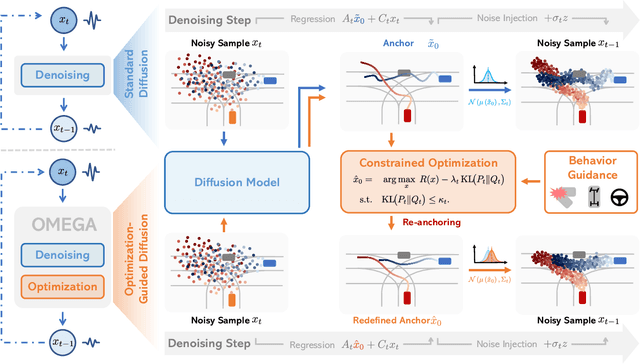
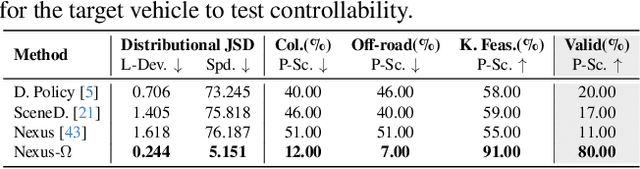
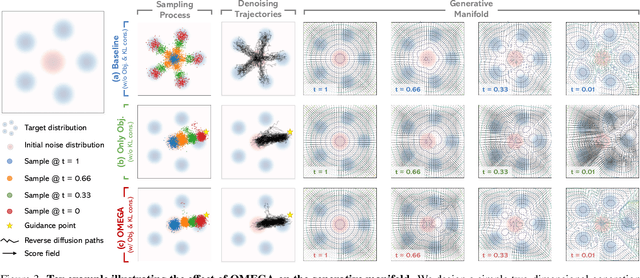
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
COVLM-RL: Critical Object-Oriented Reasoning for Autonomous Driving Using VLM-Guided Reinforcement Learning
Dec 10, 2025End-to-end autonomous driving frameworks face persistent challenges in generalization, training efficiency, and interpretability. While recent methods leverage Vision-Language Models (VLMs) through supervised learning on large-scale datasets to improve reasoning, they often lack robustness in novel scenarios. Conversely, reinforcement learning (RL)-based approaches enhance adaptability but remain data-inefficient and lack transparent decision-making. % contribution To address these limitations, we propose COVLM-RL, a novel end-to-end driving framework that integrates Critical Object-oriented (CO) reasoning with VLM-guided RL. Specifically, we design a Chain-of-Thought (CoT) prompting strategy that enables the VLM to reason over critical traffic elements and generate high-level semantic decisions, effectively transforming multi-view visual inputs into structured semantic decision priors. These priors reduce the input dimensionality and inject task-relevant knowledge into the RL loop, accelerating training and improving policy interpretability. However, bridging high-level semantic guidance with continuous low-level control remains non-trivial. To this end, we introduce a consistency loss that encourages alignment between the VLM's semantic plans and the RL agent's control outputs, enhancing interpretability and training stability. Experiments conducted in the CARLA simulator demonstrate that COVLM-RL significantly improves the success rate by 30\% in trained driving environments and by 50\% in previously unseen environments, highlighting its strong generalization capability.
DecompGAIL: Learning Realistic Traffic Behaviors with Decomposed Multi-Agent Generative Adversarial Imitation Learning
Oct 08, 2025



Realistic traffic simulation is critical for the development of autonomous driving systems and urban mobility planning, yet existing imitation learning approaches often fail to model realistic traffic behaviors. Behavior cloning suffers from covariate shift, while Generative Adversarial Imitation Learning (GAIL) is notoriously unstable in multi-agent settings. We identify a key source of this instability: irrelevant interaction misguidance, where a discriminator penalizes an ego vehicle's realistic behavior due to unrealistic interactions among its neighbors. To address this, we propose Decomposed Multi-agent GAIL (DecompGAIL), which explicitly decomposes realism into ego-map and ego-neighbor components, filtering out misleading neighbor: neighbor and neighbor: map interactions. We further introduce a social PPO objective that augments ego rewards with distance-weighted neighborhood rewards, encouraging overall realism across agents. Integrated into a lightweight SMART-based backbone, DecompGAIL achieves state-of-the-art performance on the WOMD Sim Agents 2025 benchmark.
CoReVLA: A Dual-Stage End-to-End Autonomous Driving Framework for Long-Tail Scenarios via Collect-and-Refine
Sep 19, 2025Autonomous Driving (AD) systems have made notable progress, but their performance in long-tail, safety-critical scenarios remains limited. These rare cases contribute a disproportionate number of accidents. Vision-Language Action (VLA) models have strong reasoning abilities and offer a potential solution, but their effectiveness is limited by the lack of high-quality data and inefficient learning in such conditions. To address these challenges, we propose CoReVLA, a continual learning end-to-end autonomous driving framework that improves the performance in long-tail scenarios through a dual-stage process of data Collection and behavior Refinement. First, the model is jointly fine-tuned on a mixture of open-source driving QA datasets, allowing it to acquire a foundational understanding of driving scenarios. Next, CoReVLA is deployed within the Cave Automatic Virtual Environment (CAVE) simulation platform, where driver takeover data is collected from real-time interactions. Each takeover indicates a long-tail scenario that CoReVLA fails to handle reliably. Finally, the model is refined via Direct Preference Optimization (DPO), allowing it to learn directly from human preferences and thereby avoid reward hacking caused by manually designed rewards. Extensive open-loop and closed-loop experiments demonstrate that the proposed CoReVLA model can accurately perceive driving scenarios and make appropriate decisions. On the Bench2Drive benchmark, CoReVLA achieves a Driving Score (DS) of 72.18 and a Success Rate (SR) of 50%, outperforming state-of-the-art methods by 7.96 DS and 15% SR under long-tail, safety-critical scenarios. Furthermore, case studies demonstrate the model's ability to continually improve its performance in similar failure-prone scenarios by leveraging past takeover experiences. All codea and preprocessed datasets are available at: https://github.com/FanGShiYuu/CoReVLA
Complementary Learning System Empowers Online Continual Learning of Vehicle Motion Forecasting in Smart Cities
Aug 27, 2025



Artificial intelligence underpins most smart city services, yet deep neural network (DNN) that forecasts vehicle motion still struggle with catastrophic forgetting, the loss of earlier knowledge when models are updated. Conventional fixes enlarge the training set or replay past data, but these strategies incur high data collection costs, sample inefficiently and fail to balance long- and short-term experience, leaving them short of human-like continual learning. Here we introduce Dual-LS, a task-free, online continual learning paradigm for DNN-based motion forecasting that is inspired by the complementary learning system of the human brain. Dual-LS pairs two synergistic memory rehearsal replay mechanisms to accelerate experience retrieval while dynamically coordinating long-term and short-term knowledge representations. Tests on naturalistic data spanning three countries, over 772,000 vehicles and cumulative testing mileage of 11,187 km show that Dual-LS mitigates catastrophic forgetting by up to 74.31\% and reduces computational resource demand by up to 94.02\%, markedly boosting predictive stability in vehicle motion forecasting without inflating data requirements. Meanwhile, it endows DNN-based vehicle motion forecasting with computation efficient and human-like continual learning adaptability fit for smart cities.
C2TE: Coordinated Constrained Task Execution Design for Ordering-Flexible Multi-Vehicle Platoon Merging
Jun 16, 2025In this paper, we propose a distributed coordinated constrained task execution (C2TE) algorithm that enables a team of vehicles from different lanes to cooperatively merge into an {\it ordering-flexible platoon} maneuvering on the desired lane. Therein, the platoon is flexible in the sense that no specific spatial ordering sequences of vehicles are predetermined. To attain such a flexible platoon, we first separate the multi-vehicle platoon (MVP) merging mission into two stages, namely, pre-merging regulation and {\it ordering-flexible platoon} merging, and then formulate them into distributed constraint-based optimization problems. Particularly, by encoding longitudinal-distance regulation and same-lane collision avoidance subtasks into the corresponding control barrier function (CBF) constraints, the proposed algorithm in Stage 1 can safely enlarge sufficient longitudinal distances among adjacent vehicles. Then, by encoding lateral convergence, longitudinal-target attraction, and neighboring collision avoidance subtasks into CBF constraints, the proposed algorithm in Stage~2 can efficiently achieve the {\it ordering-flexible platoon}. Note that the {\it ordering-flexible platoon} is realized through the interaction of the longitudinal-target attraction and time-varying neighboring collision avoidance constraints simultaneously. Feasibility guarantee and rigorous convergence analysis are both provided under strong nonlinear couplings induced by flexible orderings. Finally, experiments using three autonomous mobile vehicles (AMVs) are conducted to verify the effectiveness and flexibility of the proposed algorithm, and extensive simulations are performed to demonstrate its robustness, adaptability, and scalability when tackling vehicles' sudden breakdown, new appearing, different number of lanes, mixed autonomy, and large-scale scenarios, respectively.
Reinforced Refinement with Self-Aware Expansion for End-to-End Autonomous Driving
Jun 11, 2025



End-to-end autonomous driving has emerged as a promising paradigm for directly mapping sensor inputs to planning maneuvers using learning-based modular integrations. However, existing imitation learning (IL)-based models suffer from generalization to hard cases, and a lack of corrective feedback loop under post-deployment. While reinforcement learning (RL) offers a potential solution to tackle hard cases with optimality, it is often hindered by overfitting to specific driving cases, resulting in catastrophic forgetting of generalizable knowledge and sample inefficiency. To overcome these challenges, we propose Reinforced Refinement with Self-aware Expansion (R2SE), a novel learning pipeline that constantly refines hard domain while keeping generalizable driving policy for model-agnostic end-to-end driving systems. Through reinforcement fine-tuning and policy expansion that facilitates continuous improvement, R2SE features three key components: 1) Generalist Pretraining with hard-case allocation trains a generalist imitation learning (IL) driving system while dynamically identifying failure-prone cases for targeted refinement; 2) Residual Reinforced Specialist Fine-tuning optimizes residual corrections using reinforcement learning (RL) to improve performance in hard case domain while preserving global driving knowledge; 3) Self-aware Adapter Expansion dynamically integrates specialist policies back into the generalist model, enhancing continuous performance improvement. Experimental results in closed-loop simulation and real-world datasets demonstrate improvements in generalization, safety, and long-horizon policy robustness over state-of-the-art E2E systems, highlighting the effectiveness of reinforce refinement for scalable autonomous driving.