 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentNav: Learning Spatial-Visual Object Navigation from Human Demonstrations
Jun 06, 2026Object navigation requires a robot to search for an unobserved target in an unknown environment by deciding where to explore next under partial observability. Effective search resembles human-like exploration: selectively probing visually promising frontiers while relying on spatial memory to avoid redundant revisits. We propose IntentNav, a spatial-visual imitation framework that learns human-like ObjectNav policies from human demonstrations. To infer high-level search intent from low-level human actions, we introduce Frontier-based Human-Intent Labeling, which looks ahead in human demonstrations and labels the frontier that best explains the demonstrator's future search direction. We construct a spatial-visual candidate space, where BEV memory tracks explored regions, unexplored frontiers, and trajectory history, while egocentric visual memory provides semantic cues for each candidate. A VLM policy is trained to select among these grounded candidates, using Intent-Aligned Objective to encourage consistent and human-like exploration. IntentNav achieves state-of-the-art performance on the MP3D, HM3D-v1 and HM3D-v2 ObjectNav benchmarks. The proposed candidate-level navigation interface transfers zero-shot to wheeled, quadruped, and humanoid robots without further VLM fine-tuning. \href{https://anonymous.4open.science/w/IntentNav/}{Project page}.
Goal2Pixel: Grounding Goals to Pixels for Vision-Language Navigation
Jun 01, 2026Vision-language models (VLMs) have become a common foundation for vision-and-language navigation in continuous environments (VLN-CE). Yet most VLM-based methods cast navigation as low-level action prediction, an interface that is ambiguous, tied to short-horizon motion primitives, and inefficient due to repeated VLM querying. We propose Goal2Pixel, a pure pixel-based paradigm that reformulates VLN-CE as navigable pixel grounding. Rather than predicting actions, Goal2Pixel uses the image plane as a unified spatial interface between VLM reasoning and robot motion: the model predicts a visible navigable pixel to the agent, which is back-projected into a 3D waypoint for forward navigation. For non-forward actions, we append auxiliary directive regions to the image plane, where the left/right/bottom regions are interpreted as turning left, turning right, and stopping, respectively. To enable long-horizon navigation, we propose a visibility-aware keyframe memory for compact and informative history representation. To adapt pretrained VLMs to navigable pixel grounding, we introduce semantic embeddings and coordinate-aware auxiliary losses. Goal2Pixel achieves competitive state-of-the-art performance while requiring fewer VLM inference calls than prior methods. On R2R-CE Val-Unseen it achieves 54.1% SR and 52.5% SPL with just 7.75 VLM calls per episode, 6x fewer than the 46.62 required by direct action prediction at 32.9% SR. The same trend holds on RxR-CE.Project Page: https://baobao0926.github.io/Goal2Pixel/.
ImagiNav: Scalable Embodied Navigation via Generative Visual Prediction and Inverse Dynamics
Mar 14, 2026Enabling robots to navigate open-world environments via natural language is critical for general-purpose autonomy. Yet, Vision-Language Navigation has relied on end-to-end policies trained on expensive, embodiment-specific robot data. While recent foundation models trained on vast simulation data show promise, the challenge of scaling and generalizing due to the limited scene diversity and visual fidelity in simulation persists. To address this gap, we propose ImagiNav, a novel modular paradigm that decouples visual planning from robot actuation, enabling the direct utilization of diverse in-the-wild navigation videos. Our framework operates as a hierarchy: a Vision-Language Model first decomposes instructions into textual subgoals; a finetuned generative video model then imagines the future video trajectory towards that subgoal; finally, an inverse dynamics model extracts the trajectory from the imagined video, which can then be tracked via a low-level controller. We additionally develop a scalable data pipeline of in-the-wild navigation videos auto-labeled via inverse dynamics and a pretrained Vision-Language Model. ImagiNav demonstrates strong zero-shot transfer to robot navigation without requiring robot demonstrations, paving the way for generalist robots that learn navigation directly from unlabeled, open-world data.
Dual-Interaction-Aware Cooperative Control Strategy for Alleviating Mixed Traffic Congestion
Mar 04, 2026As Intelligent Transportation System (ITS) develops, Connected and Automated Vehicles (CAVs) are expected to significantly reduce traffic congestion through cooperative strategies, such as in bottleneck areas. However, the uncertainty and diversity in the behaviors of Human-Driven Vehicles (HDVs) in mixed traffic environments present major challenges for CAV cooperation. This paper proposes a Dual-Interaction-Aware Cooperative Control (DIACC) strategy that enhances both local and global interaction perception within the Multi-Agent Reinforcement Learning (MARL) framework for Connected and Automated Vehicles (CAVs) in mixed traffic bottleneck scenarios. The DIACC strategy consists of three key innovations: 1) A Decentralized Interaction-Adaptive Decision-Making (D-IADM) module that enhances actor's local interaction perception by distinguishing CAV-CAV cooperative interactions from CAV-HDV observational interactions. 2) A Centralized Interaction-Enhanced Critic (C-IEC) that improves critic's global traffic understanding through interaction-aware value estimation, providing more accurate guidance for policy updates. 3) A reward design that employs softmin aggregation with temperature annealing to prioritize interaction-intensive scenarios in mixed traffic. Additionally, a lightweight Proactive Safety-based Action Refinement (PSAR) module applies rule-based corrections to accelerate training convergence. Experimental results demonstrate that DIACC significantly improves traffic efficiency and adaptability compared to rule-based and benchmark MARL models.
Joint Learning of Unsupervised Multi-view Feature and Instance Co-selection with Cross-view Imputation
Dec 17, 2025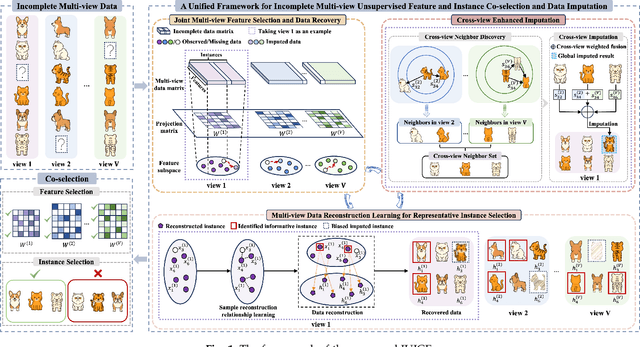
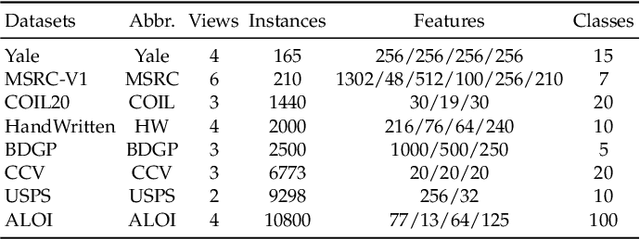
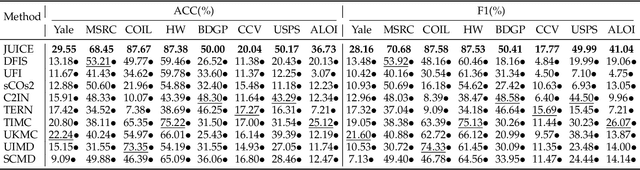
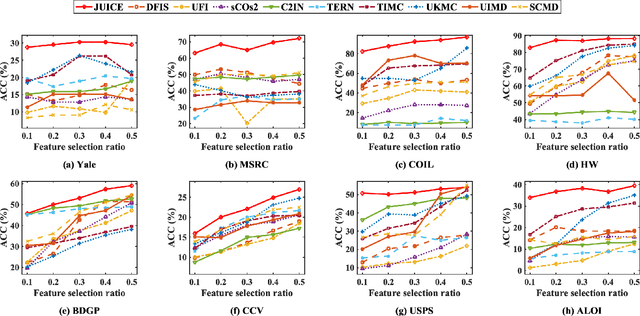
Feature and instance co-selection, which aims to reduce both feature dimensionality and sample size by identifying the most informative features and instances, has attracted considerable attention in recent years. However, when dealing with unlabeled incomplete multi-view data, where some samples are missing in certain views, existing methods typically first impute the missing data and then concatenate all views into a single dataset for subsequent co-selection. Such a strategy treats co-selection and missing data imputation as two independent processes, overlooking potential interactions between them. The inter-sample relationships gleaned from co-selection can aid imputation, which in turn enhances co-selection performance. Additionally, simply merging multi-view data fails to capture the complementary information among views, ultimately limiting co-selection effectiveness. To address these issues, we propose a novel co-selection method, termed Joint learning of Unsupervised multI-view feature and instance Co-selection with cross-viEw imputation (JUICE). JUICE first reconstructs incomplete multi-view data using available observations, bringing missing data recovery and feature and instance co-selection together in a unified framework. Then, JUICE leverages cross-view neighborhood information to learn inter-sample relationships and further refine the imputation of missing values during reconstruction. This enables the selection of more representative features and instances. Extensive experiments demonstrate that JUICE outperforms state-of-the-art methods.
COVLM-RL: Critical Object-Oriented Reasoning for Autonomous Driving Using VLM-Guided Reinforcement Learning
Dec 10, 2025End-to-end autonomous driving frameworks face persistent challenges in generalization, training efficiency, and interpretability. While recent methods leverage Vision-Language Models (VLMs) through supervised learning on large-scale datasets to improve reasoning, they often lack robustness in novel scenarios. Conversely, reinforcement learning (RL)-based approaches enhance adaptability but remain data-inefficient and lack transparent decision-making. % contribution To address these limitations, we propose COVLM-RL, a novel end-to-end driving framework that integrates Critical Object-oriented (CO) reasoning with VLM-guided RL. Specifically, we design a Chain-of-Thought (CoT) prompting strategy that enables the VLM to reason over critical traffic elements and generate high-level semantic decisions, effectively transforming multi-view visual inputs into structured semantic decision priors. These priors reduce the input dimensionality and inject task-relevant knowledge into the RL loop, accelerating training and improving policy interpretability. However, bridging high-level semantic guidance with continuous low-level control remains non-trivial. To this end, we introduce a consistency loss that encourages alignment between the VLM's semantic plans and the RL agent's control outputs, enhancing interpretability and training stability. Experiments conducted in the CARLA simulator demonstrate that COVLM-RL significantly improves the success rate by 30\% in trained driving environments and by 50\% in previously unseen environments, highlighting its strong generalization capability.
VLMLight: Traffic Signal Control via Vision-Language Meta-Control and Dual-Branch Reasoning
May 26, 2025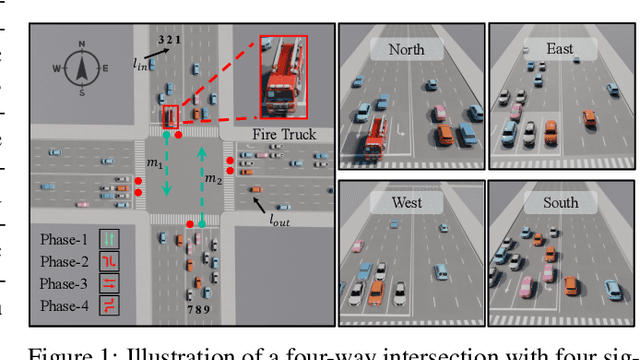
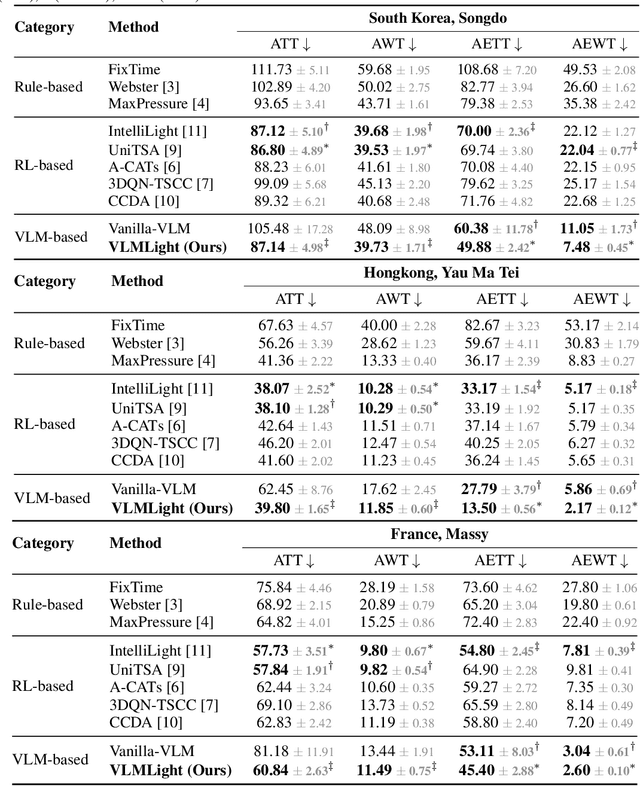
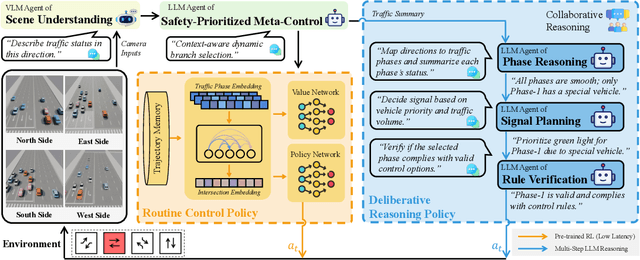

Traffic signal control (TSC) is a core challenge in urban mobility, where real-time decisions must balance efficiency and safety. Existing methods - ranging from rule-based heuristics to reinforcement learning (RL) - often struggle to generalize to complex, dynamic, and safety-critical scenarios. We introduce VLMLight, a novel TSC framework that integrates vision-language meta-control with dual-branch reasoning. At the core of VLMLight is the first image-based traffic simulator that enables multi-view visual perception at intersections, allowing policies to reason over rich cues such as vehicle type, motion, and spatial density. A large language model (LLM) serves as a safety-prioritized meta-controller, selecting between a fast RL policy for routine traffic and a structured reasoning branch for critical cases. In the latter, multiple LLM agents collaborate to assess traffic phases, prioritize emergency vehicles, and verify rule compliance. Experiments show that VLMLight reduces waiting times for emergency vehicles by up to 65% over RL-only systems, while preserving real-time performance in standard conditions with less than 1% degradation. VLMLight offers a scalable, interpretable, and safety-aware solution for next-generation traffic signal control.
CL-CoTNav: Closed-Loop Hierarchical Chain-of-Thought for Zero-Shot Object-Goal Navigation with Vision-Language Models
Apr 11, 2025Visual Object Goal Navigation (ObjectNav) requires a robot to locate a target object in an unseen environment using egocentric observations. However, decision-making policies often struggle to transfer to unseen environments and novel target objects, which is the core generalization problem. Traditional end-to-end learning methods exacerbate this issue, as they rely on memorizing spatial patterns rather than employing structured reasoning, limiting their ability to generalize effectively. In this letter, we introduce Closed-Loop Hierarchical Chain-of-Thought Navigation (CL-CoTNav), a vision-language model (VLM)-driven ObjectNav framework that integrates structured reasoning and closed-loop feedback into navigation decision-making. To enhance generalization, we fine-tune a VLM using multi-turn question-answering (QA) data derived from human demonstration trajectories. This structured dataset enables hierarchical Chain-of-Thought (H-CoT) prompting, systematically extracting compositional knowledge to refine perception and decision-making, inspired by the human cognitive process of locating a target object through iterative reasoning steps. Additionally, we propose a Closed-Loop H-CoT mechanism that incorporates detection and reasoning confidence scores into training. This adaptive weighting strategy guides the model to prioritize high-confidence data pairs, mitigating the impact of noisy inputs and enhancing robustness against hallucinated or incorrect reasoning. Extensive experiments in the AI Habitat environment demonstrate CL-CoTNav's superior generalization to unseen scenes and novel object categories. Our method consistently outperforms state-of-the-art approaches in navigation success rate (SR) and success weighted by path length (SPL) by 22.4\%. We release our datasets, models, and supplementary videos on our project page.
CONDEN-FI: Consistency and Diversity Learning-based Multi-View Unsupervised Feature and In-stance Co-Selection
Dec 09, 2024



The objective of multi-view unsupervised feature and instance co-selection is to simultaneously iden-tify the most representative features and samples from multi-view unlabeled data, which aids in mit-igating the curse of dimensionality and reducing instance size to improve the performance of down-stream tasks. However, existing methods treat feature selection and instance selection as two separate processes, failing to leverage the potential interactions between the feature and instance spaces. Addi-tionally, previous co-selection methods for multi-view data require concatenating different views, which overlooks the consistent information among them. In this paper, we propose a CONsistency and DivErsity learNing-based multi-view unsupervised Feature and Instance co-selection (CONDEN-FI) to address the above-mentioned issues. Specifically, CONDEN-FI reconstructs mul-ti-view data from both the sample and feature spaces to learn representations that are consistent across views and specific to each view, enabling the simultaneous selection of the most important features and instances. Moreover, CONDEN-FI adaptively learns a view-consensus similarity graph to help select both dissimilar and similar samples in the reconstructed data space, leading to a more diverse selection of instances. An efficient algorithm is developed to solve the resultant optimization problem, and the comprehensive experimental results on real-world datasets demonstrate that CONDEN-FI is effective compared to state-of-the-art methods.
C$^{2}$IMUFS: Complementary and Consensus Learning-based Incomplete Multi-view Unsupervised Feature Selection
Aug 20, 2022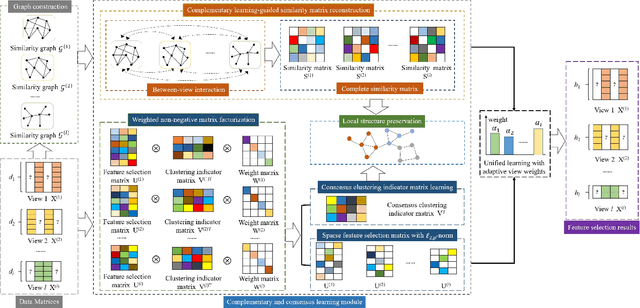
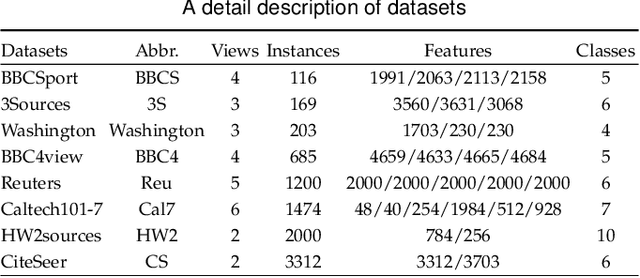
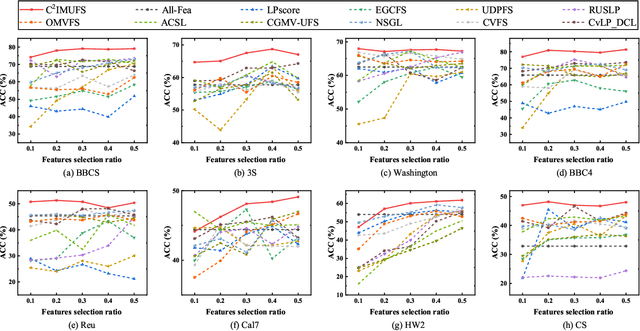
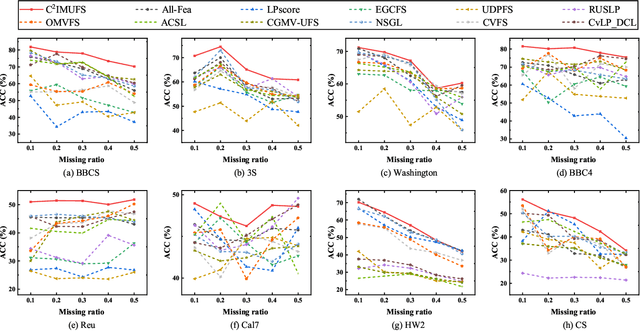
Multi-view unsupervised feature selection (MUFS) has been demonstrated as an effective technique to reduce the dimensionality of multi-view unlabeled data. The existing methods assume that all of views are complete. However, multi-view data are usually incomplete, i.e., a part of instances are presented on some views but not all views. Besides, learning the complete similarity graph, as an important promising technology in existing MUFS methods, cannot achieve due to the missing views. In this paper, we propose a complementary and consensus learning-based incomplete multi-view unsupervised feature selection method (C$^{2}$IMUFS) to address the aforementioned issues. Concretely, C$^{2}$IMUFS integrates feature selection into an extended weighted non-negative matrix factorization model equipped with adaptive learning of view-weights and a sparse $\ell_{2,p}$-norm, which can offer better adaptability and flexibility. By the sparse linear combinations of multiple similarity matrices derived from different views, a complementary learning-guided similarity matrix reconstruction model is presented to obtain the complete similarity graph in each view. Furthermore, C$^{2}$IMUFS learns a consensus clustering indicator matrix across different views and embeds it into a spectral graph term to preserve the local geometric structure. Comprehensive experimental results on real-world datasets demonstrate the effectiveness of C$^{2}$IMUFS compared with state-of-the-art methods.