 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking air traffic flow prediction through microscopic aircraft-state modeling
May 11, 2026Short-term air traffic flow prediction in terminal airspace is essential for proactive air traffic management. Existing approaches predominantly model traffic flow as aggregated time series, despite traffic dynamics being governed by aircraft states and interactions in continuous airspace. Such aggregation obscures fine-grained information including aircraft kinematics, boundary interactions, and control intent. Here we present AeroSense, a state-to-flow modeling framework that predicts future traffic flow directly from instantaneous airspace situations represented as dynamic sets of aircraft states derived from ADS-B trajectories. By establishing an end-to-end mapping from microscopic aircraft states to future regional traffic flow, AeroSense preserves aircraft-level dynamics while naturally accommodating varying traffic density without relying on historical look-back windows. Experiments on a large-scale real-world dataset show that AeroSense consistently improves predictive accuracy over aggregation-based forecasting approaches, particularly during high-density traffic periods. These findings suggest that instantaneous airspace situations provide an effective alternative to conventional time-series-based traffic forecasting paradigms.
Kernel Alignment-based Multi-view Unsupervised Feature Selection with Sample-level Adaptive Graph Learning
Jan 12, 2026Although multi-view unsupervised feature selection (MUFS) has demonstrated success in dimensionality reduction for unlabeled multi-view data, most existing methods reduce feature redundancy by focusing on linear correlations among features but often overlook complex nonlinear dependencies. This limits the effectiveness of feature selection. In addition, existing methods fuse similarity graphs from multiple views by employing sample-invariant weights to preserve local structure. However, this process fails to account for differences in local neighborhood clarity among samples within each view, thereby hindering accurate characterization of the intrinsic local structure of the data. In this paper, we propose a Kernel Alignment-based multi-view unsupervised FeatUre selection with Sample-level adaptive graph lEarning method (KAFUSE) to address these issues. Specifically, we first employ kernel alignment with an orthogonal constraint to reduce feature redundancy in both linear and nonlinear relationships. Then, a cross-view consistent similarity graph is learned by applying sample-level fusion to each slice of a tensor formed by stacking similarity graphs from different views, which automatically adjusts the view weights for each sample during fusion. These two steps are integrated into a unified model for feature selection, enabling mutual enhancement between them. Extensive experiments on real multi-view datasets demonstrate the superiority of KAFUSE over state-of-the-art methods.
Joint Learning of Unsupervised Multi-view Feature and Instance Co-selection with Cross-view Imputation
Dec 17, 2025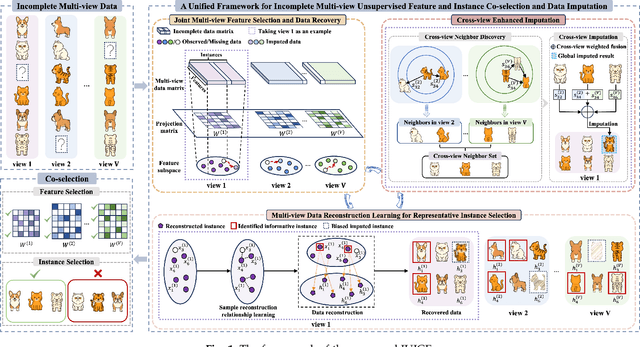
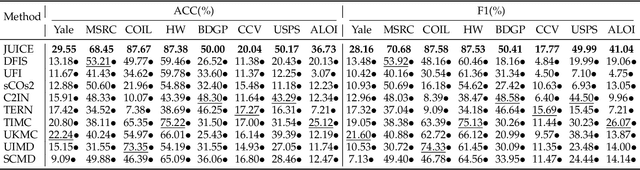
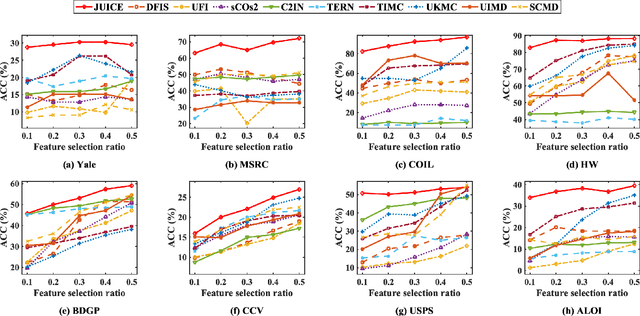
Feature and instance co-selection, which aims to reduce both feature dimensionality and sample size by identifying the most informative features and instances, has attracted considerable attention in recent years. However, when dealing with unlabeled incomplete multi-view data, where some samples are missing in certain views, existing methods typically first impute the missing data and then concatenate all views into a single dataset for subsequent co-selection. Such a strategy treats co-selection and missing data imputation as two independent processes, overlooking potential interactions between them. The inter-sample relationships gleaned from co-selection can aid imputation, which in turn enhances co-selection performance. Additionally, simply merging multi-view data fails to capture the complementary information among views, ultimately limiting co-selection effectiveness. To address these issues, we propose a novel co-selection method, termed Joint learning of Unsupervised multI-view feature and instance Co-selection with cross-viEw imputation (JUICE). JUICE first reconstructs incomplete multi-view data using available observations, bringing missing data recovery and feature and instance co-selection together in a unified framework. Then, JUICE leverages cross-view neighborhood information to learn inter-sample relationships and further refine the imputation of missing values during reconstruction. This enables the selection of more representative features and instances. Extensive experiments demonstrate that JUICE outperforms state-of-the-art methods.
Cross-view Joint Learning for Mixed-Missing Multi-view Unsupervised Feature Selection
Nov 15, 2025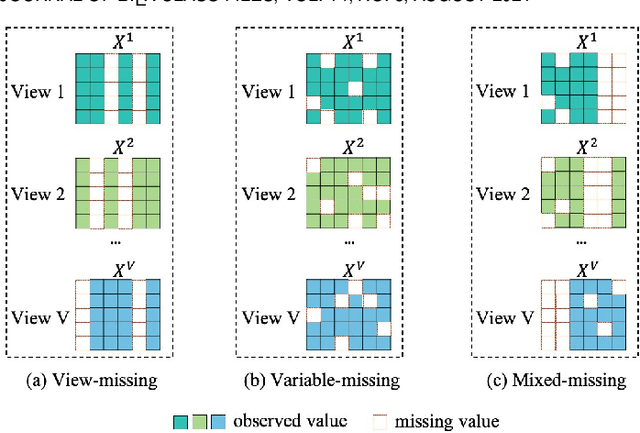
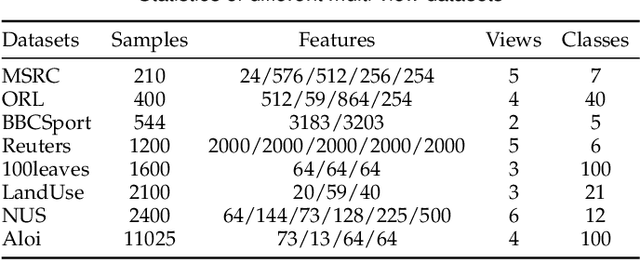
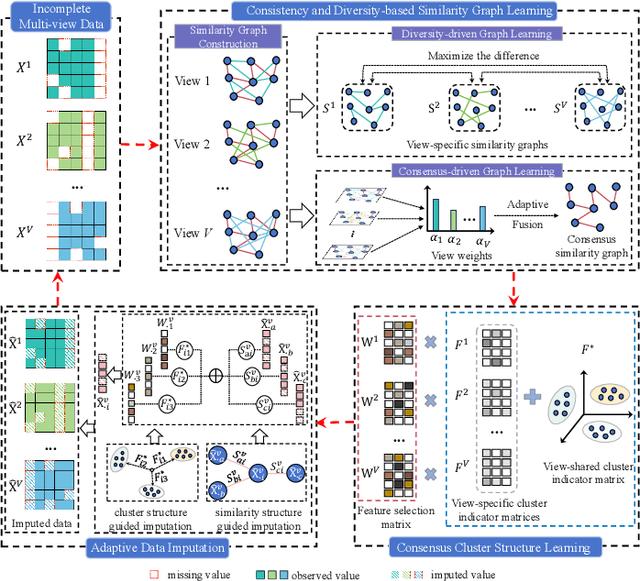
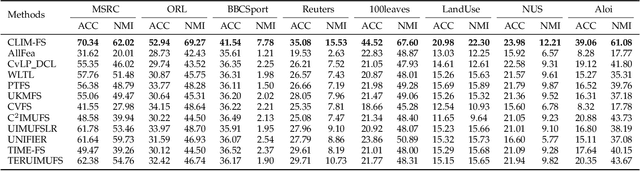
Incomplete multi-view unsupervised feature selection (IMUFS), which aims to identify representative features from unlabeled multi-view data containing missing values, has received growing attention in recent years. Despite their promising performance, existing methods face three key challenges: 1) by focusing solely on the view-missing problem, they are not well-suited to the more prevalent mixed-missing scenario in practice, where some samples lack entire views or only partial features within views; 2) insufficient utilization of consistency and diversity across views limits the effectiveness of feature selection; and 3) the lack of theoretical analysis makes it unclear how feature selection and data imputation interact during the joint learning process. Being aware of these, we propose CLIM-FS, a novel IMUFS method designed to address the mixed-missing problem. Specifically, we integrate the imputation of both missing views and variables into a feature selection model based on nonnegative orthogonal matrix factorization, enabling the joint learning of feature selection and adaptive data imputation. Furthermore, we fully leverage consensus cluster structure and cross-view local geometrical structure to enhance the synergistic learning process. We also provide a theoretical analysis to clarify the underlying collaborative mechanism of CLIM-FS. Experimental results on eight real-world multi-view datasets demonstrate that CLIM-FS outperforms state-of-the-art methods.
TRUST-FS: Tensorized Reliable Unsupervised Multi-View Feature Selection for Incomplete Data
Sep 16, 2025Multi-view unsupervised feature selection (MUFS), which selects informative features from multi-view unlabeled data, has attracted increasing research interest in recent years. Although great efforts have been devoted to MUFS, several challenges remain: 1) existing methods for incomplete multi-view data are limited to handling missing views and are unable to address the more general scenario of missing variables, where some features have missing values in certain views; 2) most methods address incomplete data by first imputing missing values and then performing feature selection, treating these two processes independently and overlooking their interactions; 3) missing data can result in an inaccurate similarity graph, which reduces the performance of feature selection. To solve this dilemma, we propose a novel MUFS method for incomplete multi-view data with missing variables, termed Tensorized Reliable UnSupervised mulTi-view Feature Selection (TRUST-FS). TRUST-FS introduces a new adaptive-weighted CP decomposition that simultaneously performs feature selection, missing-variable imputation, and view weight learning within a unified tensor factorization framework. By utilizing Subjective Logic to acquire trustworthy cross-view similarity information, TRUST-FS facilitates learning a reliable similarity graph, which subsequently guides feature selection and imputation. Comprehensive experimental results demonstrate the effectiveness and superiority of our method over state-of-the-art methods.
Iterative Feature Space Optimization through Incremental Adaptive Evaluation
Jan 24, 2025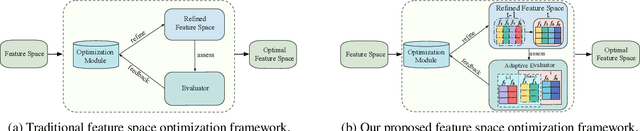
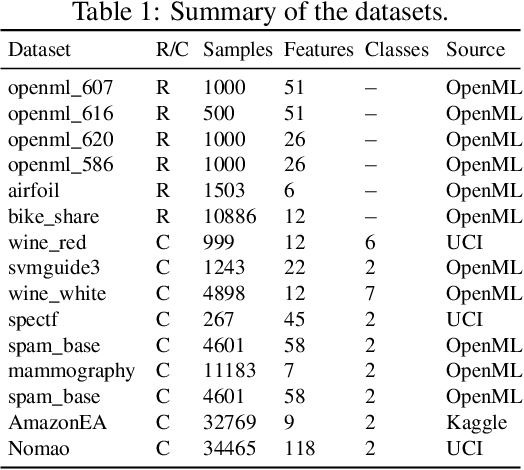
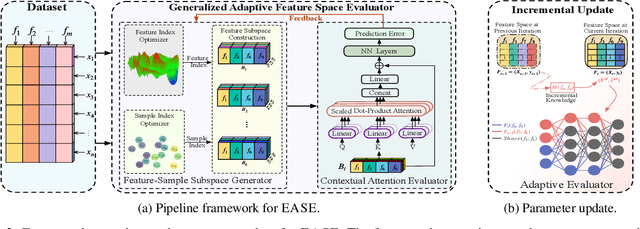
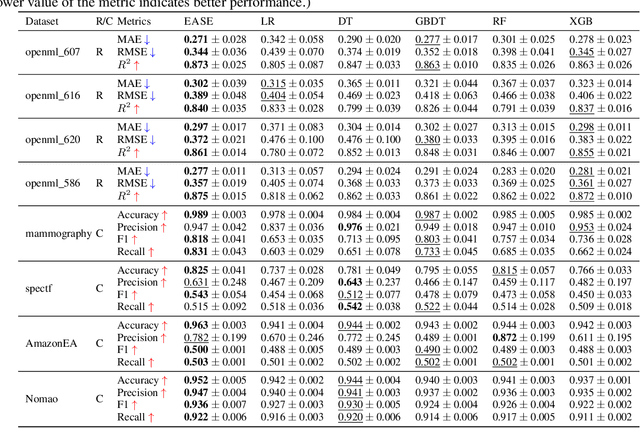
Iterative feature space optimization involves systematically evaluating and adjusting the feature space to improve downstream task performance. However, existing works suffer from three key limitations:1) overlooking differences among data samples leads to evaluation bias; 2) tailoring feature spaces to specific machine learning models results in overfitting and poor generalization; 3) requiring the evaluator to be retrained from scratch during each optimization iteration significantly reduces the overall efficiency of the optimization process. To bridge these gaps, we propose a gEneralized Adaptive feature Space Evaluator (EASE) to efficiently produce optimal and generalized feature spaces. This framework consists of two key components: Feature-Sample Subspace Generator and Contextual Attention Evaluator. The first component aims to decouple the information distribution within the feature space to mitigate evaluation bias. To achieve this, we first identify features most relevant to prediction tasks and samples most challenging for evaluation based on feedback from the subsequent evaluator. This decoupling strategy makes the evaluator consistently target the most challenging aspects of the feature space. The second component intends to incrementally capture evolving patterns of the feature space for efficient evaluation. We propose a weighted-sharing multi-head attention mechanism to encode key characteristics of the feature space into an embedding vector for evaluation. Moreover, the evaluator is updated incrementally, retaining prior evaluation knowledge while incorporating new insights, as consecutive feature spaces during the optimization process share partial information. Extensive experiments on fourteen real-world datasets demonstrate the effectiveness of the proposed framework. Our code and data are publicly available.
Towards Data-Centric AI: A Comprehensive Survey of Traditional, Reinforcement, and Generative Approaches for Tabular Data Transformation
Jan 17, 2025



Tabular data is one of the most widely used formats across industries, driving critical applications in areas such as finance, healthcare, and marketing. In the era of data-centric AI, improving data quality and representation has become essential for enhancing model performance, particularly in applications centered around tabular data. This survey examines the key aspects of tabular data-centric AI, emphasizing feature selection and feature generation as essential techniques for data space refinement. We provide a systematic review of feature selection methods, which identify and retain the most relevant data attributes, and feature generation approaches, which create new features to simplify the capture of complex data patterns. This survey offers a comprehensive overview of current methodologies through an analysis of recent advancements, practical applications, and the strengths and limitations of these techniques. Finally, we outline open challenges and suggest future perspectives to inspire continued innovation in this field.
CONDEN-FI: Consistency and Diversity Learning-based Multi-View Unsupervised Feature and In-stance Co-Selection
Dec 09, 2024



The objective of multi-view unsupervised feature and instance co-selection is to simultaneously iden-tify the most representative features and samples from multi-view unlabeled data, which aids in mit-igating the curse of dimensionality and reducing instance size to improve the performance of down-stream tasks. However, existing methods treat feature selection and instance selection as two separate processes, failing to leverage the potential interactions between the feature and instance spaces. Addi-tionally, previous co-selection methods for multi-view data require concatenating different views, which overlooks the consistent information among them. In this paper, we propose a CONsistency and DivErsity learNing-based multi-view unsupervised Feature and Instance co-selection (CONDEN-FI) to address the above-mentioned issues. Specifically, CONDEN-FI reconstructs mul-ti-view data from both the sample and feature spaces to learn representations that are consistent across views and specific to each view, enabling the simultaneous selection of the most important features and instances. Moreover, CONDEN-FI adaptively learns a view-consensus similarity graph to help select both dissimilar and similar samples in the reconstructed data space, leading to a more diverse selection of instances. An efficient algorithm is developed to solve the resultant optimization problem, and the comprehensive experimental results on real-world datasets demonstrate that CONDEN-FI is effective compared to state-of-the-art methods.
Causally-Aware Unsupervised Feature Selection Learning
Oct 16, 2024



Unsupervised feature selection (UFS) has recently gained attention for its effectiveness in processing unlabeled high-dimensional data. However, existing methods overlook the intrinsic causal mechanisms within the data, resulting in the selection of irrelevant features and poor interpretability. Additionally, previous graph-based methods fail to account for the differing impacts of non-causal and causal features in constructing the similarity graph, which leads to false links in the generated graph. To address these issues, a novel UFS method, called Causally-Aware UnSupErvised Feature Selection learning (CAUSE-FS), is proposed. CAUSE-FS introduces a novel causal regularizer that reweights samples to balance the confounding distribution of each treatment feature. This regularizer is subsequently integrated into a generalized unsupervised spectral regression model to mitigate spurious associations between features and clustering labels, thus achieving causal feature selection. Furthermore, CAUSE-FS employs causality-guided hierarchical clustering to partition features with varying causal contributions into multiple granularities. By integrating similarity graphs learned adaptively at different granularities, CAUSE-FS increases the importance of causal features when constructing the fused similarity graph to capture the reliable local structure of data. Extensive experimental results demonstrate the superiority of CAUSE-FS over state-of-the-art methods, with its interpretability further validated through feature visualization.
Adaptive Collaborative Correlation Learning-based Semi-Supervised Multi-Label Feature Selection
Jun 18, 2024Semi-supervised multi-label feature selection has recently been developed to solve the curse of dimensionality problem in high-dimensional multi-label data with certain samples missing labels. Although many efforts have been made, most existing methods use a predefined graph approach to capture the sample similarity or the label correlation. In this manner, the presence of noise and outliers within the original feature space can undermine the reliability of the resulting sample similarity graph. It also fails to precisely depict the label correlation due to the existence of unknown labels. Besides, these methods only consider the discriminative power of selected features, while neglecting their redundancy. In this paper, we propose an Adaptive Collaborative Correlation lEarning-based Semi-Supervised Multi-label Feature Selection (Access-MFS) method to address these issues. Specifically, a generalized regression model equipped with an extended uncorrelated constraint is introduced to select discriminative yet irrelevant features and maintain consistency between predicted and ground-truth labels in labeled data, simultaneously. Then, the instance correlation and label correlation are integrated into the proposed regression model to adaptively learn both the sample similarity graph and the label similarity graph, which mutually enhance feature selection performance. Extensive experimental results demonstrate the superiority of the proposed Access-MFS over other state-of-the-art methods.