 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAvatar: Unlocking Highly Expressive Avatars via Harmonized Text-Audio Conditioning
Jan 31, 2026Existing video avatar models have demonstrated impressive capabilities in scenarios such as talking, public speaking, and singing. However, the majority of these methods exhibit limited alignment with respect to text instructions, particularly when the prompts involve complex elements including large full-body movement, dynamic camera trajectory, background transitions, or human-object interactions. To break out this limitation, we present JoyAvatar, a framework capable of generating long duration avatar videos, featuring two key technical innovations. Firstly, we introduce a twin-teacher enhanced training algorithm that enables the model to transfer inherent text-controllability from the foundation model while simultaneously learning audio-visual synchronization. Secondly, during training, we dynamically modulate the strength of multi-modal conditions (e.g., audio and text) based on the distinct denoising timestep, aiming to mitigate conflicts between the heterogeneous conditioning signals. These two key designs serve to substantially expand the avatar model's capacity to generate natural, temporally coherent full-body motions and dynamic camera movements as well as preserve the basic avatar capabilities, such as accurate lip-sync and identity consistency. GSB evaluation results demonstrate that our JoyAvatar model outperforms the state-of-the-art models such as Omnihuman-1.5 and KlingAvatar 2.0. Moreover, our approach enables complex applications including multi-person dialogues and non-human subjects role-playing. Some video samples are provided on https://joyavatar.github.io/.
JoyAvatar: Real-time and Infinite Audio-Driven Avatar Generation with Autoregressive Diffusion
Dec 12, 2025Existing DiT-based audio-driven avatar generation methods have achieved considerable progress, yet their broader application is constrained by limitations such as high computational overhead and the inability to synthesize long-duration videos. Autoregressive methods address this problem by applying block-wise autoregressive diffusion methods. However, these methods suffer from the problem of error accumulation and quality degradation. To address this, we propose JoyAvatar, an audio-driven autoregressive model capable of real-time inference and infinite-length video generation with the following contributions: (1) Progressive Step Bootstrapping (PSB), which allocates more denoising steps to initial frames to stabilize generation and reduce error accumulation; (2) Motion Condition Injection (MCI), enhancing temporal coherence by injecting noise-corrupted previous frames as motion condition; and (3) Unbounded RoPE via Cache-Resetting (URCR), enabling infinite-length generation through dynamic positional encoding. Our 1.3B-parameter causal model achieves 16 FPS on a single GPU and achieves competitive results in visual quality, temporal consistency, and lip synchronization.
SegCLIP: Patch Aggregation with Learnable Centers for Open-Vocabulary Semantic Segmentation
Nov 27, 2022



Recently, the contrastive language-image pre-training, e.g., CLIP, has demonstrated promising results on various downstream tasks. The pre-trained model can capture enriched visual concepts for images by learning from a large scale of text-image data. However, transferring the learned visual knowledge to open-vocabulary semantic segmentation is still under-explored. In this paper, we propose a CLIP-based model named SegCLIP for the topic of open-vocabulary segmentation in an annotation-free manner. The SegCLIP achieves segmentation based on ViT and the main idea is to gather patches with learnable centers to semantic regions through training on text-image pairs. The gathering operation can dynamically capture the semantic groups, which can be used to generate the final segmentation results. We further propose a reconstruction loss on masked patches and a superpixel-based KL loss with pseudo-labels to enhance the visual representation. Experimental results show that our model achieves comparable or superior segmentation accuracy on the PASCAL VOC 2012 (+1.4% mIoU), PASCAL Context (+2.4% mIoU), and COCO (+5.6% mIoU) compared with baselines. We release the code at https://github.com/ArrowLuo/SegCLIP.
CSS: Combining Self-training and Self-supervised Learning for Few-shot Dialogue State Tracking
Oct 11, 2022
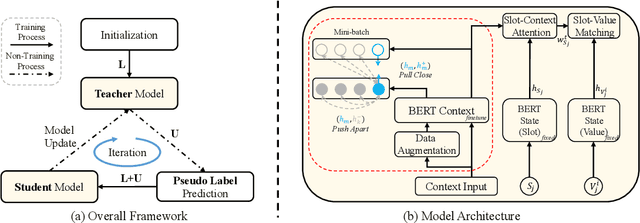
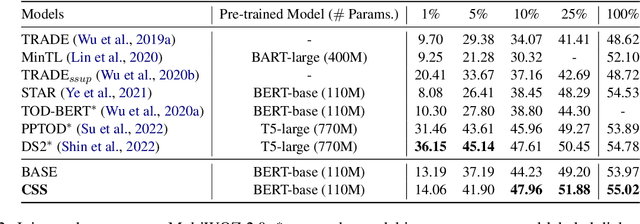
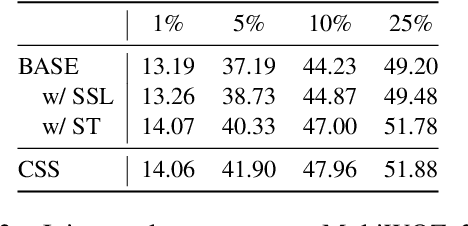
Few-shot dialogue state tracking (DST) is a realistic problem that trains the DST model with limited labeled data. Existing few-shot methods mainly transfer knowledge learned from external labeled dialogue data (e.g., from question answering, dialogue summarization, machine reading comprehension tasks, etc.) into DST, whereas collecting a large amount of external labeled data is laborious, and the external data may not effectively contribute to the DST-specific task. In this paper, we propose a few-shot DST framework called CSS, which Combines Self-training and Self-supervised learning methods. The unlabeled data of the DST task is incorporated into the self-training iterations, where the pseudo labels are predicted by a DST model trained on limited labeled data in advance. Besides, a contrastive self-supervised method is used to learn better representations, where the data is augmented by the dropout operation to train the model. Experimental results on the MultiWOZ dataset show that our proposed CSS achieves competitive performance in several few-shot scenarios.
ScaleVLAD: Improving Multimodal Sentiment Analysis via Multi-Scale Fusion of Locally Descriptors
Dec 02, 2021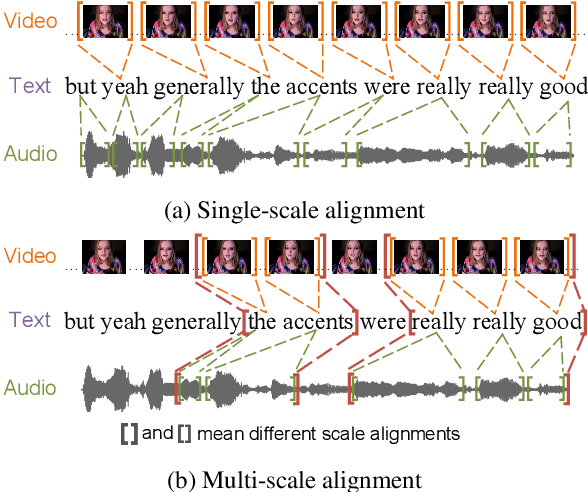

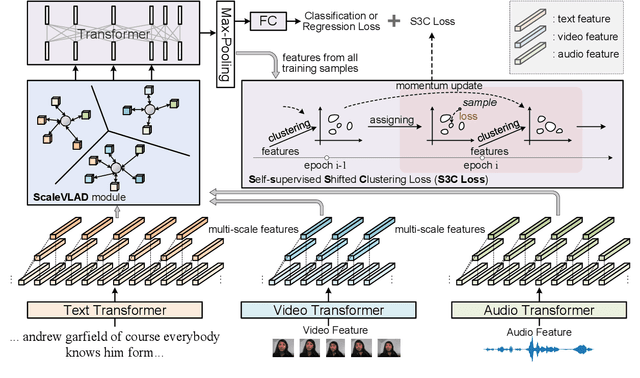
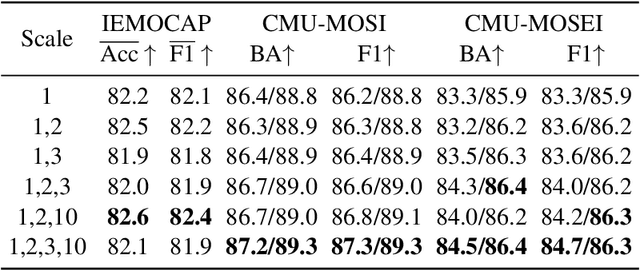
Fusion technique is a key research topic in multimodal sentiment analysis. The recent attention-based fusion demonstrates advances over simple operation-based fusion. However, these fusion works adopt single-scale, i.e., token-level or utterance-level, unimodal representation. Such single-scale fusion is suboptimal because that different modality should be aligned with different granularities. This paper proposes a fusion model named ScaleVLAD to gather multi-Scale representation from text, video, and audio with shared Vectors of Locally Aggregated Descriptors to improve unaligned multimodal sentiment analysis. These shared vectors can be regarded as shared topics to align different modalities. In addition, we propose a self-supervised shifted clustering loss to keep the fused feature differentiation among samples. The backbones are three Transformer encoders corresponding to three modalities, and the aggregated features generated from the fusion module are feed to a Transformer plus a full connection to finish task predictions. Experiments on three popular sentiment analysis benchmarks, IEMOCAP, MOSI, and MOSEI, demonstrate significant gains over baselines.
GEM: A General Evaluation Benchmark for Multimodal Tasks
Jun 18, 2021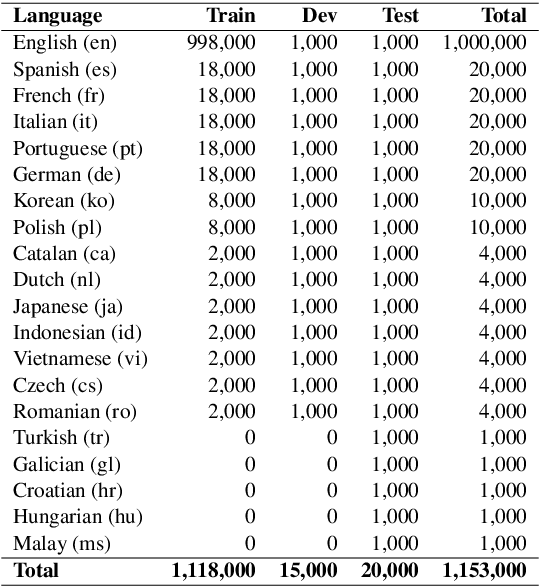

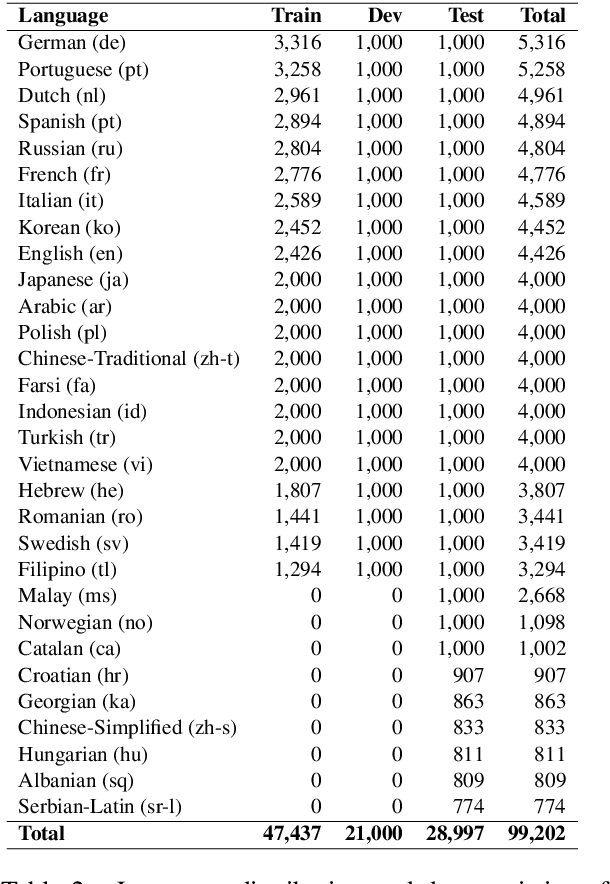

In this paper, we present GEM as a General Evaluation benchmark for Multimodal tasks. Different from existing datasets such as GLUE, SuperGLUE, XGLUE and XTREME that mainly focus on natural language tasks, GEM is a large-scale vision-language benchmark, which consists of GEM-I for image-language tasks and GEM-V for video-language tasks. Comparing with existing multimodal datasets such as MSCOCO and Flicker30K for image-language tasks, YouCook2 and MSR-VTT for video-language tasks, GEM is not only the largest vision-language dataset covering image-language tasks and video-language tasks at the same time, but also labeled in multiple languages. We also provide two baseline models for this benchmark. We will release the dataset, code and baseline models, aiming to advance the development of multilingual multimodal research.
CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
May 08, 2021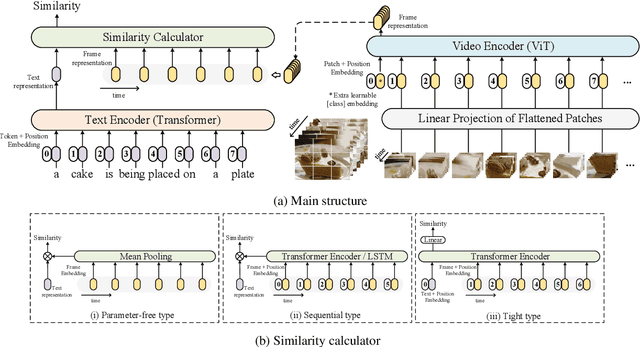
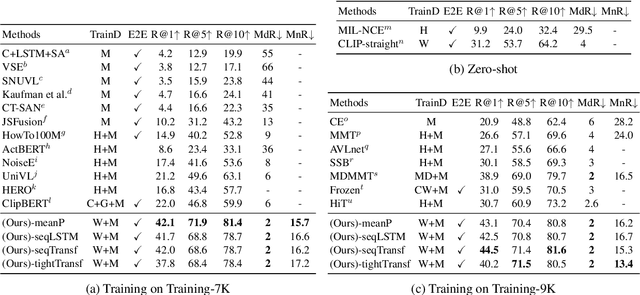


Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. The CLIP (Contrastive Language-Image Pre-training), an image-language pre-training model, has demonstrated the power of visual concepts learning from web collected image-text datasets. In this paper, we propose a CLIP4Clip model to transfer the knowledge of the CLIP model to video-language retrieval in an end-to-end manner. Several questions are investigated via empirical studies: 1) Whether image feature is enough for video-text retrieval? 2) How a post-pretraining on a large-scale video-text dataset based on the CLIP affect the performance? 3) What is the practical mechanism to model temporal dependency between video frames? And 4) The Hyper-parameters sensitivity of the model on video-text retrieval task. Extensive experimental results present that the CLIP4Clip model transferred from the CLIP can achieve SOTA results on various video-text retrieval datasets, including MSR-VTT, MSVC, LSMDC, ActivityNet, and DiDeMo. We release our code at https://github.com/ArrowLuo/CLIP4Clip.
MaP: A Matrix-based Prediction Approach to Improve Span Extraction in Machine Reading Comprehension
Sep 29, 2020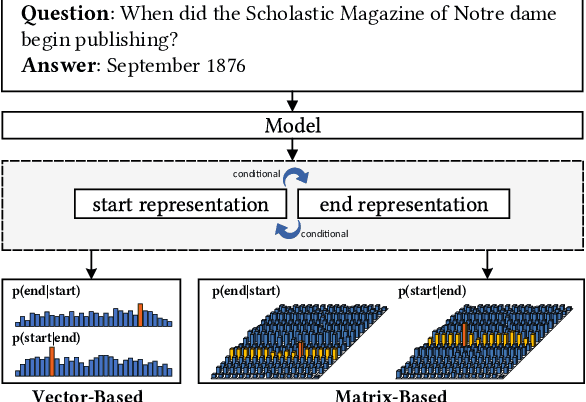
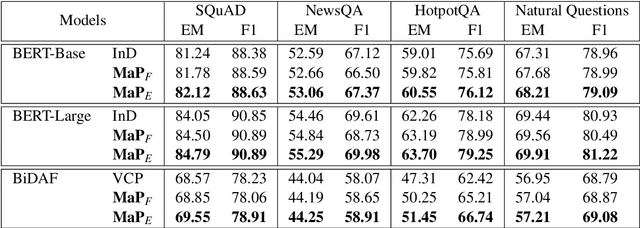
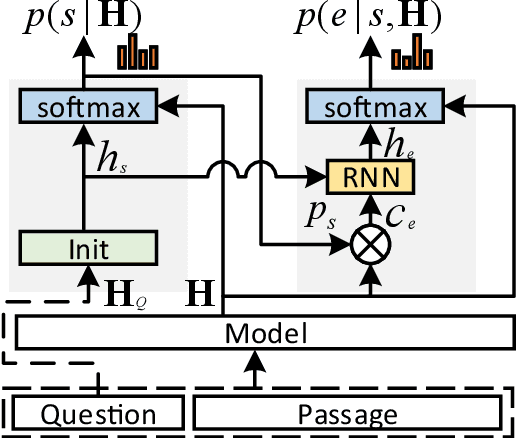
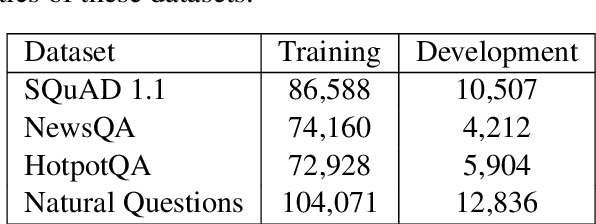
Span extraction is an essential problem in machine reading comprehension. Most of the existing algorithms predict the start and end positions of an answer span in the given corresponding context by generating two probability vectors. In this paper, we propose a novel approach that extends the probability vector to a probability matrix. Such a matrix can cover more start-end position pairs. Precisely, to each possible start index, the method always generates an end probability vector. Besides, we propose a sampling-based training strategy to address the computational cost and memory issue in the matrix training phase. We evaluate our method on SQuAD 1.1 and three other question answering benchmarks. Leveraging the most competitive models BERT and BiDAF as the backbone, our proposed approach can get consistent improvements in all datasets, demonstrating the effectiveness of the proposed method.
GRACE: Gradient Harmonized and Cascaded Labeling for Aspect-based Sentiment Analysis
Sep 25, 2020
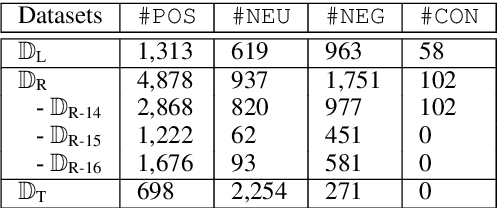
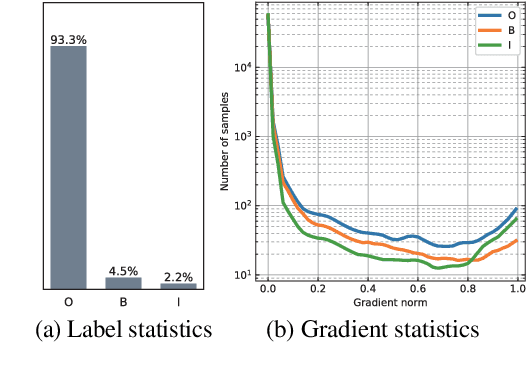
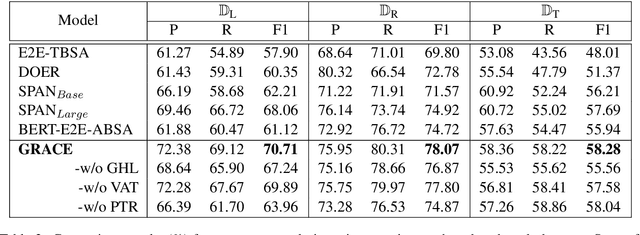
In this paper, we focus on the imbalance issue, which is rarely studied in aspect term extraction and aspect sentiment classification when regarding them as sequence labeling tasks. Besides, previous works usually ignore the interaction between aspect terms when labeling polarities. We propose a GRadient hArmonized and CascadEd labeling model (GRACE) to solve these problems. Specifically, a cascaded labeling module is developed to enhance the interchange between aspect terms and improve the attention of sentiment tokens when labeling sentiment polarities. The polarities sequence is designed to depend on the generated aspect terms labels. To alleviate the imbalance issue, we extend the gradient harmonized mechanism used in object detection to the aspect-based sentiment analysis by adjusting the weight of each label dynamically. The proposed GRACE adopts a post-pretraining BERT as its backbone. Experimental results demonstrate that the proposed model achieves consistency improvement on multiple benchmark datasets and generates state-of-the-art results.
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Feb 15, 2020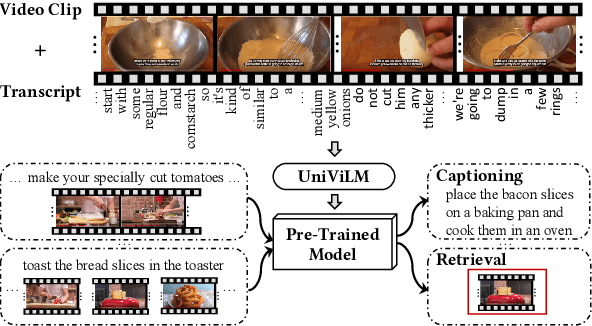
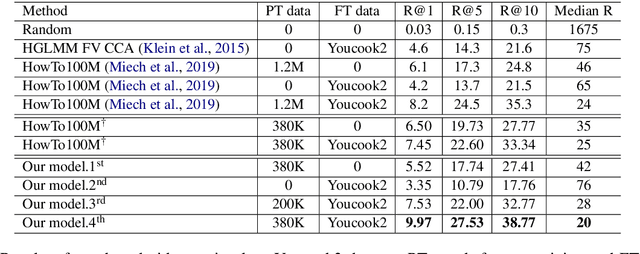
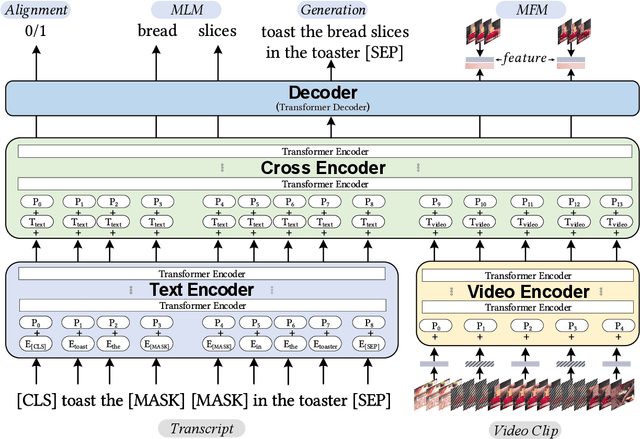
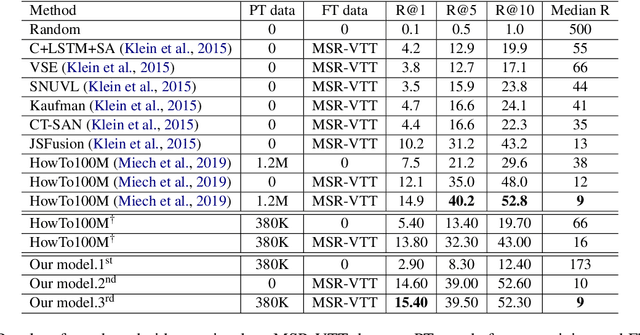
We propose UniViLM: a Unified Video and Language pre-training Model for multimodal understanding and generation. Motivated by the recent success of BERT based pre-training technique for NLP and image-language tasks, VideoBERT and CBT are proposed to exploit BERT model for video and language pre-training using narrated instructional videos. Different from their works which only pre-train understanding task, we propose a unified video-language pre-training model for both understanding and generation tasks. Our model comprises of 4 components including two single-modal encoders, a cross encoder and a decoder with the Transformer backbone. We first pre-train our model to learn the universal representation for both video and language on a large instructional video dataset. Then we fine-tune the model on two multimodal tasks including understanding task (text-based video retrieval) and generation task (multimodal video captioning). Our extensive experiments show that our method can improve the performance of both understanding and generation tasks and achieves the state-of-the art results.