 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: A General Evaluation Benchmark for Multimodal Tasks
Jun 18, 2021


In this paper, we present GEM as a General Evaluation benchmark for Multimodal tasks. Different from existing datasets such as GLUE, SuperGLUE, XGLUE and XTREME that mainly focus on natural language tasks, GEM is a large-scale vision-language benchmark, which consists of GEM-I for image-language tasks and GEM-V for video-language tasks. Comparing with existing multimodal datasets such as MSCOCO and Flicker30K for image-language tasks, YouCook2 and MSR-VTT for video-language tasks, GEM is not only the largest vision-language dataset covering image-language tasks and video-language tasks at the same time, but also labeled in multiple languages. We also provide two baseline models for this benchmark. We will release the dataset, code and baseline models, aiming to advance the development of multilingual multimodal research.
ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
Jan 23, 2020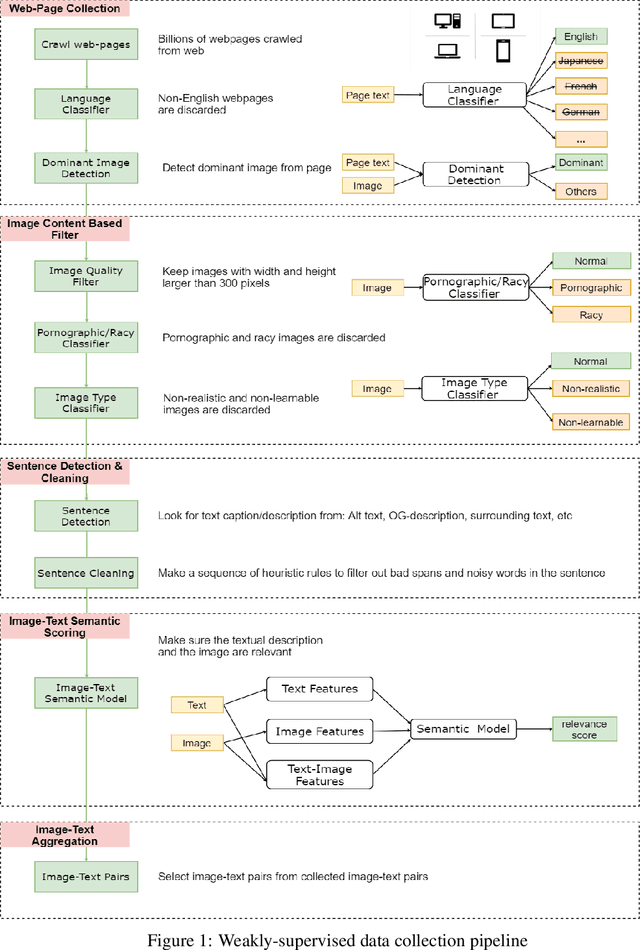
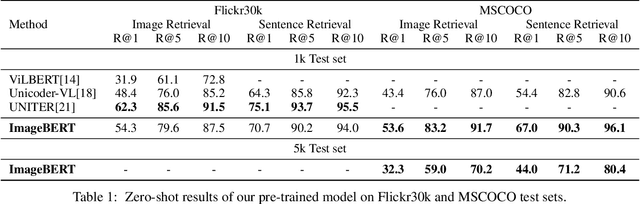

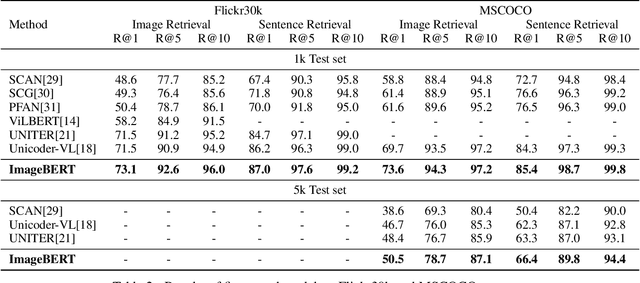
In this paper, we introduce a new vision-language pre-trained model -- ImageBERT -- for image-text joint embedding. Our model is a Transformer-based model, which takes different modalities as input and models the relationship between them. The model is pre-trained on four tasks simultaneously: Masked Language Modeling (MLM), Masked Object Classification (MOC), Masked Region Feature Regression (MRFR), and Image Text Matching (ITM). To further enhance the pre-training quality, we have collected a Large-scale weAk-supervised Image-Text (LAIT) dataset from Web. We first pre-train the model on this dataset, then conduct a second stage pre-training on Conceptual Captions and SBU Captions. Our experiments show that multi-stage pre-training strategy outperforms single-stage pre-training. We also fine-tune and evaluate our pre-trained ImageBERT model on image retrieval and text retrieval tasks, and achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.
Web-Scale Responsive Visual Search at Bing
Feb 20, 2018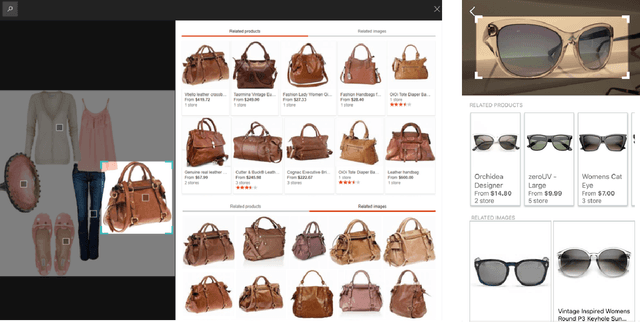
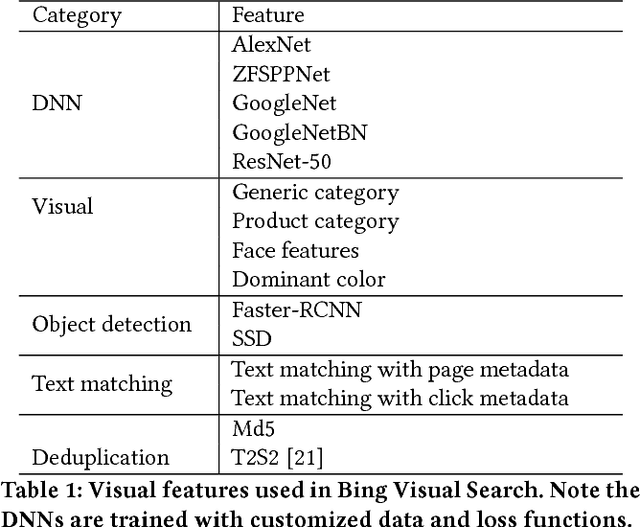
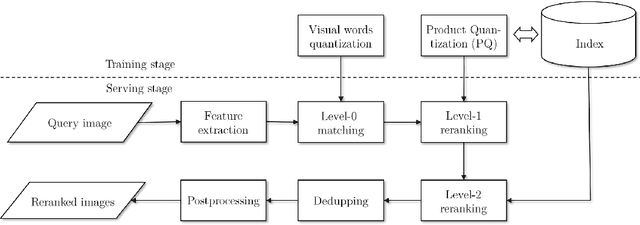

In this paper, we introduce a web-scale general visual search system deployed in Microsoft Bing. The system accommodates tens of billions of images in the index, with thousands of features for each image, and can respond in less than 200 ms. In order to overcome the challenges in relevance, latency, and scalability in such large scale of data, we employ a cascaded learning-to-rank framework based on various latest deep learning visual features, and deploy in a distributed heterogeneous computing platform. Quantitative and qualitative experiments show that our system is able to support various applications on Bing website and apps.