 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
Paper and Code
Jan 23, 2020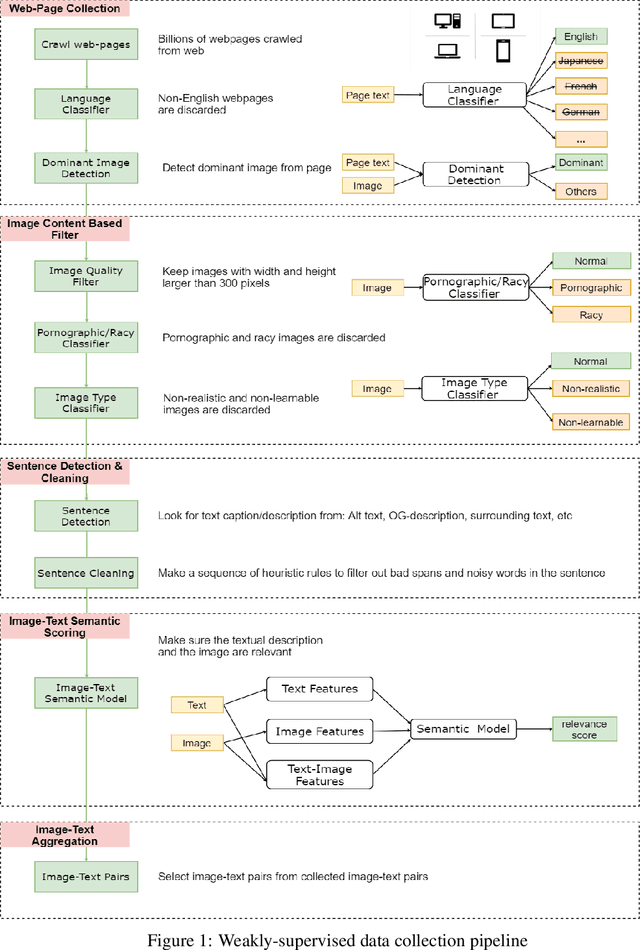
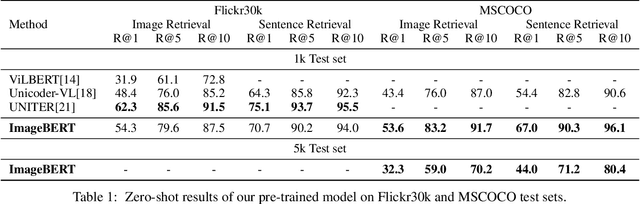

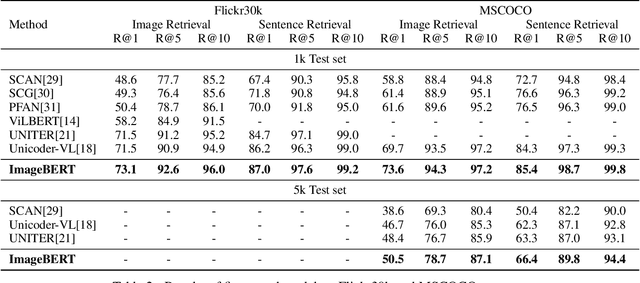
In this paper, we introduce a new vision-language pre-trained model -- ImageBERT -- for image-text joint embedding. Our model is a Transformer-based model, which takes different modalities as input and models the relationship between them. The model is pre-trained on four tasks simultaneously: Masked Language Modeling (MLM), Masked Object Classification (MOC), Masked Region Feature Regression (MRFR), and Image Text Matching (ITM). To further enhance the pre-training quality, we have collected a Large-scale weAk-supervised Image-Text (LAIT) dataset from Web. We first pre-train the model on this dataset, then conduct a second stage pre-training on Conceptual Captions and SBU Captions. Our experiments show that multi-stage pre-training strategy outperforms single-stage pre-training. We also fine-tune and evaluate our pre-trained ImageBERT model on image retrieval and text retrieval tasks, and achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.