 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAPO: Information-Aware Policy Optimization for Token-Efficient Reasoning
Feb 22, 2026Large language models increasingly rely on long chains of thought to improve accuracy, yet such gains come with substantial inference-time costs. We revisit token-efficient post-training and argue that existing sequence-level reward-shaping methods offer limited control over how reasoning effort is allocated across tokens. To bridge the gap, we propose IAPO, an information-theoretic post-training framework that assigns token-wise advantages based on each token's conditional mutual information (MI) with the final answer. This yields an explicit, principled mechanism for identifying informative reasoning steps and suppressing low-utility exploration. We provide a theoretical analysis showing that our IAPO can induce monotonic reductions in reasoning verbosity without harming correctness. Empirically, IAPO consistently improves reasoning accuracy while reducing reasoning length by up to 36%, outperforming existing token-efficient RL methods across various reasoning datasets. Extensive empirical evaluations demonstrate that information-aware advantage shaping is a powerful and general direction for token-efficient post-training. The code is available at https://github.com/YinhanHe123/IAPO.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Non-destructive Degradation Pattern Decoupling for Ultra-early Battery Prototype Verification Using Physics-informed Machine Learning
Jun 01, 2024



Manufacturing complexities and uncertainties have impeded the transition from material prototypes to commercial batteries, making prototype verification critical to quality assessment. A fundamental challenge involves deciphering intertwined chemical processes to characterize degradation patterns and their quantitative relationship with battery performance. Here we show that a physics-informed machine learning approach can quantify and visualize temporally resolved losses concerning thermodynamics and kinetics only using electric signals. Our method enables non-destructive degradation pattern characterization, expediting temperature-adaptable predictions of entire lifetime trajectories, rather than end-of-life points. The verification speed is 25 times faster yet maintaining 95.1% accuracy across temperatures. Such advances facilitate more sustainable management of defective prototypes before massive production, establishing a 19.76 billion USD scrap material recycling market by 2060 in China. By incorporating stepwise charge acceptance as a measure of the initial manufacturing variability of normally identical batteries, we can immediately identify long-term degradation variations. We attribute the predictive power to interpreting machine learning insights using material-agnostic featurization taxonomy for degradation pattern decoupling. Our findings offer new possibilities for dynamic system analysis, such as battery prototype degradation, demonstrating that complex pattern evolutions can be accurately predicted in a non-destructive and data-driven fashion by integrating physics-informed machine learning.
GEM: A General Evaluation Benchmark for Multimodal Tasks
Jun 18, 2021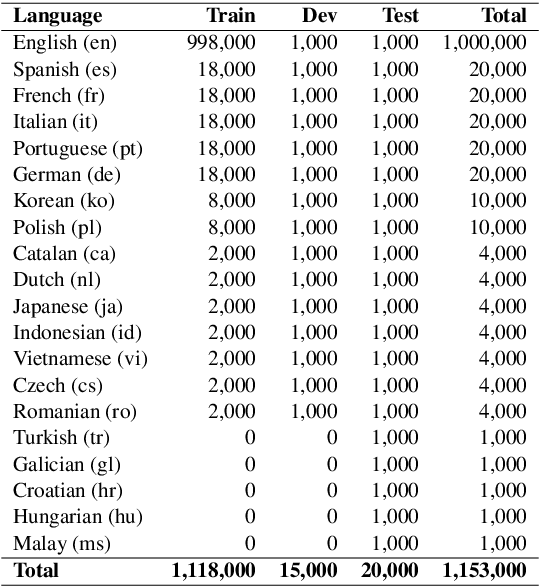


In this paper, we present GEM as a General Evaluation benchmark for Multimodal tasks. Different from existing datasets such as GLUE, SuperGLUE, XGLUE and XTREME that mainly focus on natural language tasks, GEM is a large-scale vision-language benchmark, which consists of GEM-I for image-language tasks and GEM-V for video-language tasks. Comparing with existing multimodal datasets such as MSCOCO and Flicker30K for image-language tasks, YouCook2 and MSR-VTT for video-language tasks, GEM is not only the largest vision-language dataset covering image-language tasks and video-language tasks at the same time, but also labeled in multiple languages. We also provide two baseline models for this benchmark. We will release the dataset, code and baseline models, aiming to advance the development of multilingual multimodal research.
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
Jun 04, 2020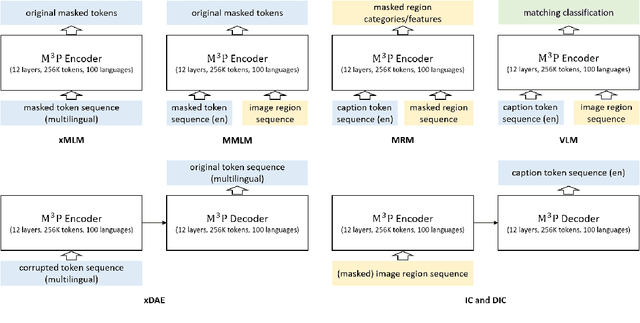


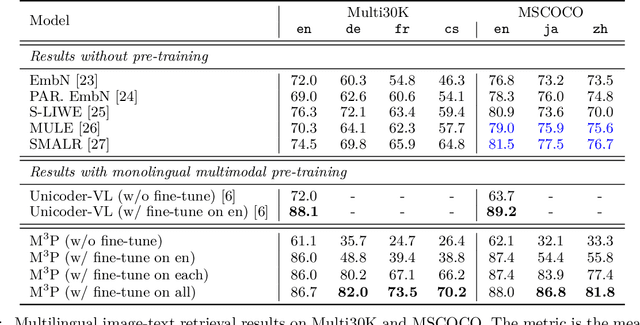
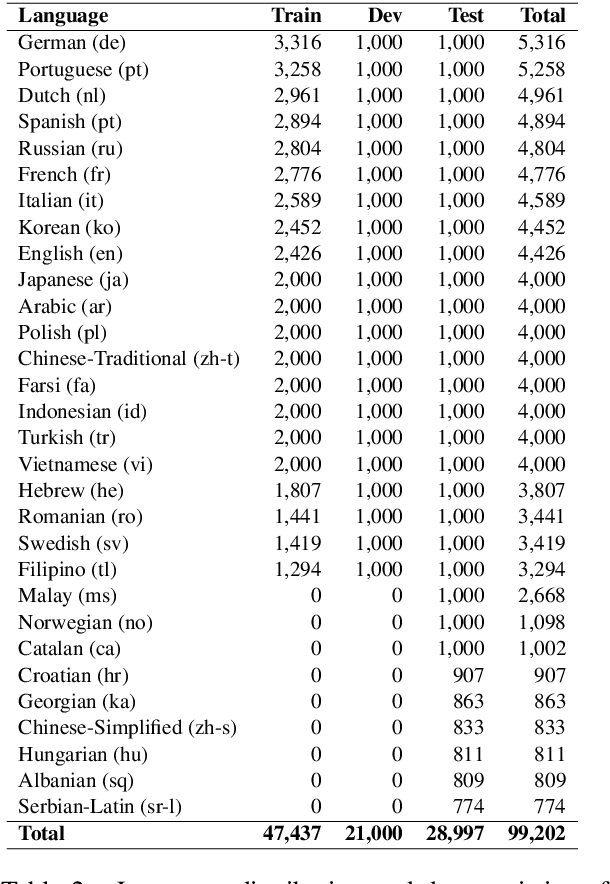
This paper presents a Multitask Multilingual Multimodal Pre-trained model (M3P) that combines multilingual-monomodal pre-training and monolingual-multimodal pre-training into a unified framework via multitask learning and weight sharing. The model learns universal representations that can map objects that occurred in different modalities or expressed in different languages to vectors in a common semantic space. To verify the generalization capability of M3P, we fine-tune the pre-trained model for different types of downstream tasks: multilingual image-text retrieval, multilingual image captioning, multimodal machine translation, multilingual natural language inference and multilingual text generation. Evaluation shows that M3P can (i) achieve comparable results on multilingual tasks and English multimodal tasks, compared to the state-of-the-art models pre-trained for these two types of tasks separately, and (ii) obtain new state-of-the-art results on non-English multimodal tasks in the zero-shot or few-shot setting. We also build a new Multilingual Image-Language Dataset (MILD) by collecting large amounts of (text-query, image, context) triplets in 8 languages from the logs of a commercial search engine
ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
Jan 23, 2020
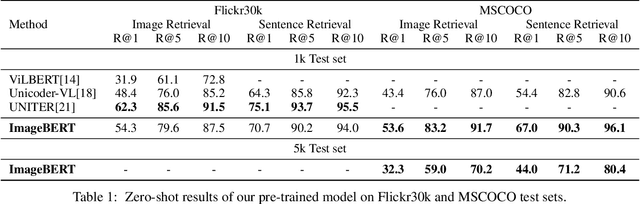

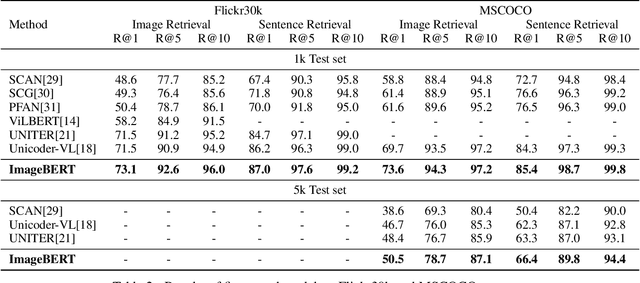
In this paper, we introduce a new vision-language pre-trained model -- ImageBERT -- for image-text joint embedding. Our model is a Transformer-based model, which takes different modalities as input and models the relationship between them. The model is pre-trained on four tasks simultaneously: Masked Language Modeling (MLM), Masked Object Classification (MOC), Masked Region Feature Regression (MRFR), and Image Text Matching (ITM). To further enhance the pre-training quality, we have collected a Large-scale weAk-supervised Image-Text (LAIT) dataset from Web. We first pre-train the model on this dataset, then conduct a second stage pre-training on Conceptual Captions and SBU Captions. Our experiments show that multi-stage pre-training strategy outperforms single-stage pre-training. We also fine-tune and evaluate our pre-trained ImageBERT model on image retrieval and text retrieval tasks, and achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.
Gini-regularized Optimal Transport with an Application to Spatio-Temporal Forecasting
Dec 07, 2017
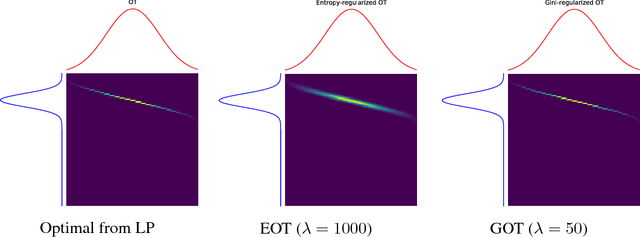
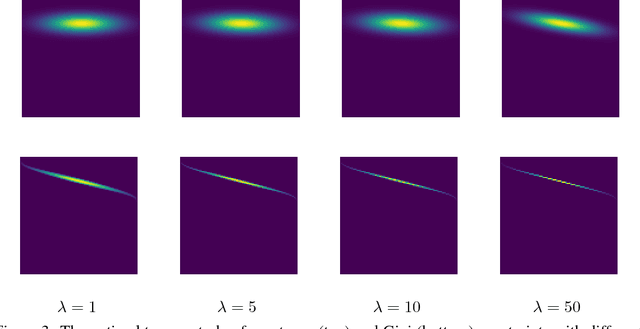
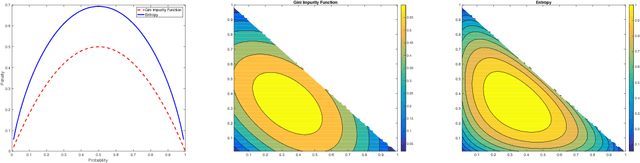
Rapidly growing product lines and services require a finer-granularity forecast that considers geographic locales. However the open question remains, how to assess the quality of a spatio-temporal forecast? In this manuscript we introduce a metric to evaluate spatio-temporal forecasts. This metric is based on an Opti- mal Transport (OT) problem. The metric we propose is a constrained OT objec- tive function using the Gini impurity function as a regularizer. We demonstrate through computer experiments both the qualitative and the quantitative charac- teristics of the Gini regularized OT problem. Moreover, we show that the Gini regularized OT problem converges to the classical OT problem, when the Gini regularized problem is considered as a function of {\lambda}, the regularization parame-ter. The convergence to the classical OT solution is faster than the state-of-the-art Entropic-regularized OT[Cuturi, 2013] and results in a numerically more stable algorithm.