 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeRL: Permutation-Enhanced Reinforcement Learning for Interleaved Vision-Language Reasoning
Jun 17, 2025Inspired by the impressive reasoning capabilities demonstrated by reinforcement learning approaches like DeepSeek-R1, recent emerging research has begun exploring the use of reinforcement learning (RL) to enhance vision-language models (VLMs) for multimodal reasoning tasks. However, most existing multimodal reinforcement learning approaches remain limited to spatial reasoning within single-image contexts, yet still struggle to generalize to more complex and real-world scenarios involving multi-image positional reasoning, where understanding the relationships across images is crucial. To address this challenge, we propose a general reinforcement learning approach PeRL tailored for interleaved multimodal tasks, and a multi-stage strategy designed to enhance the exploration-exploitation trade-off, thereby improving learning efficiency and task performance. Specifically, we introduce permutation of image sequences to simulate varied positional relationships to explore more spatial and positional diversity. Furthermore, we design a rollout filtering mechanism for resampling to focus on trajectories that contribute most to learning optimal behaviors to exploit learned policies effectively. We evaluate our model on 5 widely-used multi-image benchmarks and 3 single-image benchmarks. Our experiments confirm that PeRL trained model consistently surpasses R1-related and interleaved VLM baselines by a large margin, achieving state-of-the-art performance on multi-image benchmarks, while preserving comparable performance on single-image tasks.
Overcoming Vocabulary Mismatch: Vocabulary-agnostic Teacher Guided Language Modeling
Mar 24, 2025Using large teacher models to guide the training of smaller student models has become the prevailing paradigm for efficient and effective learning. However, vocabulary mismatches between teacher and student language models pose significant challenges in language modeling, resulting in divergent token sequences and output distributions. To overcome these limitations, we propose Vocabulary-agnostic Teacher Guided Language Modeling (VocAgnoLM), a novel approach that bridges the gap caused by vocabulary mismatch through two key methods: (1) Token-level Lexical Alignment, which aligns token sequences across mismatched vocabularies, and (2) Teacher Guided Loss, which leverages the loss of teacher model to guide effective student training. We demonstrate its effectiveness in language modeling with 1B student model using various 7B teacher models with different vocabularies. Notably, with Qwen2.5-Math-Instruct, a teacher model sharing only about 6% of its vocabulary with TinyLlama, VocAgnoLM achieves a 46% performance improvement compared to naive continual pretraining. Furthermore, we demonstrate that VocAgnoLM consistently benefits from stronger teacher models, providing a robust solution to vocabulary mismatches in language modeling.
Generative Context Distillation
Nov 24, 2024Prompts used in recent large language model based applications are often fixed and lengthy, leading to significant computational overhead. To address this challenge, we propose Generative Context Distillation (GCD), a lightweight prompt internalization method that employs a joint training approach. This method not only replicates the behavior of models with prompt inputs but also generates the content of the prompt along with reasons for why the model's behavior should change accordingly. We demonstrate that our approach effectively internalizes complex prompts across various agent-based application scenarios. For effective training without interactions with the dedicated environments, we introduce a data synthesis technique that autonomously collects conversational datasets by swapping the roles of the agent and environment. This method is especially useful in scenarios where only a predefined prompt is available without a corresponding training dataset. By internalizing complex prompts, Generative Context Distillation enables high-performance and efficient inference without the need for explicit prompts.
Explore the Reasoning Capability of LLMs in the Chess Testbed
Nov 11, 2024



Reasoning is a central capability of human intelligence. In recent years, with the advent of large-scale datasets, pretrained large language models have emerged with new capabilities, including reasoning. However, these models still struggle with long-term, complex reasoning tasks, such as playing chess. Based on the observation that expert chess players employ a dual approach combining long-term strategic play with short-term tactical play along with language explanation, we propose improving the reasoning capability of large language models in chess by integrating annotated strategy and tactic. Specifically, we collect a dataset named MATE, which consists of 1 million chess positions with candidate moves annotated by chess experts for strategy and tactics. We finetune the LLaMA-3-8B model and compare it against state-of-the-art commercial language models in the task of selecting better chess moves. Our experiments show that our models perform better than GPT, Claude, and Gemini models. We find that language explanations can enhance the reasoning capability of large language models.
ToolGen: Unified Tool Retrieval and Calling via Generation
Oct 04, 2024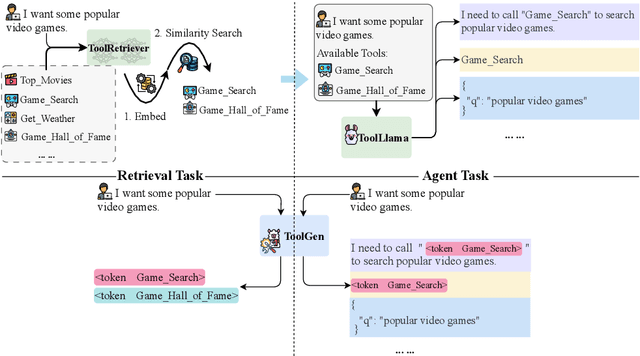
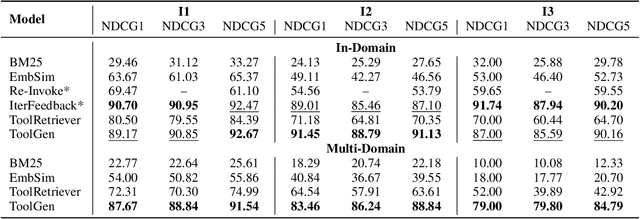
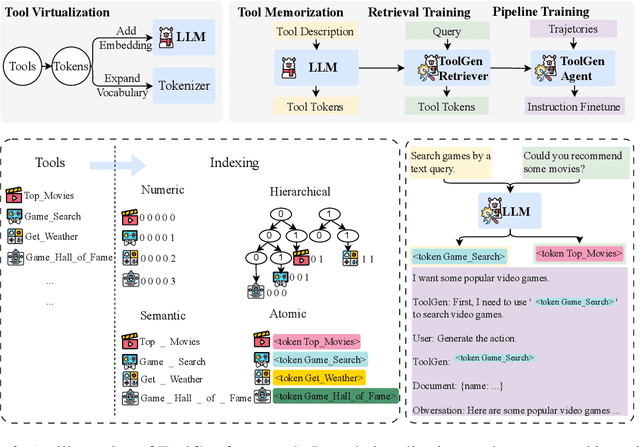

As large language models (LLMs) advance, their inability to autonomously execute tasks by directly interacting with external tools remains a critical limitation. Traditional methods rely on inputting tool descriptions as context, which is constrained by context length and requires separate, often inefficient, retrieval mechanisms. We introduce ToolGen, a paradigm shift that integrates tool knowledge directly into the LLM's parameters by representing each tool as a unique token. This enables the LLM to generate tool calls and arguments as part of its next token prediction capabilities, seamlessly blending tool invocation with language generation. Our framework allows the LLM to access and utilize a vast amount of tools with no additional retrieval step, significantly enhancing both performance and scalability. Experimental results with over 47,000 tools show that ToolGen not only achieves superior results in both tool retrieval and autonomous task completion but also sets the stage for a new era of AI agents that can adapt to tools across diverse domains. By fundamentally transforming tool retrieval into a generative process, ToolGen paves the way for more versatile, efficient, and autonomous AI systems. ToolGen enables end-to-end tool learning and opens opportunities for integration with other advanced techniques such as chain-of-thought and reinforcement learning, thereby expanding the practical capabilities of LLMs.
G-VOILA: Gaze-Facilitated Information Querying in Daily Scenarios
May 13, 2024Modern information querying systems are progressively incorporating multimodal inputs like vision and audio. However, the integration of gaze -- a modality deeply linked to user intent and increasingly accessible via gaze-tracking wearables -- remains underexplored. This paper introduces a novel gaze-facilitated information querying paradigm, named G-VOILA, which synergizes users' gaze, visual field, and voice-based natural language queries to facilitate a more intuitive querying process. In a user-enactment study involving 21 participants in 3 daily scenarios (p = 21, scene = 3), we revealed the ambiguity in users' query language and a gaze-voice coordination pattern in users' natural query behaviors with G-VOILA. Based on the quantitative and qualitative findings, we developed a design framework for the G-VOILA paradigm, which effectively integrates the gaze data with the in-situ querying context. Then we implemented a G-VOILA proof-of-concept using cutting-edge deep learning techniques. A follow-up user study (p = 16, scene = 2) demonstrates its effectiveness by achieving both higher objective score and subjective score, compared to a baseline without gaze data. We further conducted interviews and provided insights for future gaze-facilitated information querying systems.
Exploring Diffusion Time-steps for Unsupervised Representation Learning
Jan 21, 2024Representation learning is all about discovering the hidden modular attributes that generate the data faithfully. We explore the potential of Denoising Diffusion Probabilistic Model (DM) in unsupervised learning of the modular attributes. We build a theoretical framework that connects the diffusion time-steps and the hidden attributes, which serves as an effective inductive bias for unsupervised learning. Specifically, the forward diffusion process incrementally adds Gaussian noise to samples at each time-step, which essentially collapses different samples into similar ones by losing attributes, e.g., fine-grained attributes such as texture are lost with less noise added (i.e., early time-steps), while coarse-grained ones such as shape are lost by adding more noise (i.e., late time-steps). To disentangle the modular attributes, at each time-step t, we learn a t-specific feature to compensate for the newly lost attribute, and the set of all 1,...,t-specific features, corresponding to the cumulative set of lost attributes, are trained to make up for the reconstruction error of a pre-trained DM at time-step t. On CelebA, FFHQ, and Bedroom datasets, the learned feature significantly improves attribute classification and enables faithful counterfactual generation, e.g., interpolating only one specified attribute between two images, validating the disentanglement quality. Codes are in https://github.com/yue-zhongqi/diti.
ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation
Jan 01, 2024Graphical User Interface (GUI) automation holds significant promise for assisting users with complex tasks, thereby boosting human productivity. Existing works leveraging Large Language Model (LLM) or LLM-based AI agents have shown capabilities in automating tasks on Android and Web platforms. However, these tasks are primarily aimed at simple device usage and entertainment operations. This paper presents a novel benchmark, AssistGUI, to evaluate whether models are capable of manipulating the mouse and keyboard on the Windows platform in response to user-requested tasks. We carefully collected a set of 100 tasks from nine widely-used software applications, such as, After Effects and MS Word, each accompanied by the necessary project files for better evaluation. Moreover, we propose an advanced Actor-Critic Embodied Agent framework, which incorporates a sophisticated GUI parser driven by an LLM-agent and an enhanced reasoning mechanism adept at handling lengthy procedural tasks. Our experimental results reveal that our GUI Parser and Reasoning mechanism outshine existing methods in performance. Nevertheless, the potential remains substantial, with the best model attaining only a 46% success rate on our benchmark. We conclude with a thorough analysis of the current methods' limitations, setting the stage for future breakthroughs in this domain.
EHRXQA: A Multi-Modal Question Answering Dataset for Electronic Health Records with Chest X-ray Images
Oct 28, 2023



Electronic Health Records (EHRs), which contain patients' medical histories in various multi-modal formats, often overlook the potential for joint reasoning across imaging and table modalities underexplored in current EHR Question Answering (QA) systems. In this paper, we introduce EHRXQA, a novel multi-modal question answering dataset combining structured EHRs and chest X-ray images. To develop our dataset, we first construct two uni-modal resources: 1) The MIMIC- CXR-VQA dataset, our newly created medical visual question answering (VQA) benchmark, specifically designed to augment the imaging modality in EHR QA, and 2) EHRSQL (MIMIC-IV), a refashioned version of a previously established table-based EHR QA dataset. By integrating these two uni-modal resources, we successfully construct a multi-modal EHR QA dataset that necessitates both uni-modal and cross-modal reasoning. To address the unique challenges of multi-modal questions within EHRs, we propose a NeuralSQL-based strategy equipped with an external VQA API. This pioneering endeavor enhances engagement with multi-modal EHR sources and we believe that our dataset can catalyze advances in real-world medical scenarios such as clinical decision-making and research. EHRXQA is available at https://github.com/baeseongsu/ehrxqa.
KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization
Jul 10, 2023In this paper, we introduce CheXOFA, a new pre-trained vision-language model (VLM) for the chest X-ray domain. Our model is initially pre-trained on various multimodal datasets within the general domain before being transferred to the chest X-ray domain. Following a prominent VLM, we unify various domain-specific tasks into a simple sequence-to-sequence schema. It enables the model to effectively learn the required knowledge and skills from limited resources in the domain. Demonstrating superior performance on the benchmark datasets provided by the BioNLP shared task, our model benefits from its training across multiple tasks and domains. With subtle techniques including ensemble and factual calibration, our system achieves first place on the RadSum23 leaderboard for the hidden test set.