 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATTNSOM: Learning Cross-Isoform Attention for Cytochrome P450 Site-of-Metabolism
Jan 28, 2026Identifying metabolic sites where cytochrome P450 enzymes metabolize small-molecule drugs is essential for drug discovery. Although existing computational approaches have been proposed for site-of-metabolism prediction, they typically ignore cytochrome P450 isoform identity or model isoforms independently, thereby failing to fully capture inherent cross-isoform metabolic patterns. In addition, prior evaluations often rely on top-k metrics, where false positive atoms may be included among the top predictions, underscoring the need for complementary metrics that more directly assess binary atom-level discrimination under severe class imbalance. We propose ATTNSOM, an atom-level site-of-metabolism prediction framework that integrates intrinsic molecular reactivity with cross-isoform relationships. The model combines a shared graph encoder, molecule-conditioned atom representations, and a cross-attention mechanism to capture correlated metabolic patterns across cytochrome P450 isoforms. The model is evaluated on two benchmark datasets annotated with site-of-metabolism labels at atom resolution. Across these benchmarks, the model achieves consistently strong top-k performance across multiple cytochrome P450 isoforms. Relative to ablated variants, the model yields higher Matthews correlation coefficient, indicating improved discrimination of true metabolic sites. These results support the importance of explicitly modeling cross-isoform relationships for site-of-metabolism prediction. The code and datasets are available at https://github.com/dmis-lab/ATTNSOM.
HiRef: Leveraging Hierarchical Ontology and Network Refinement for Robust Medication Recommendation
Aug 14, 2025Medication recommendation is a crucial task for assisting physicians in making timely decisions from longitudinal patient medical records. However, real-world EHR data present significant challenges due to the presence of rarely observed medical entities and incomplete records that may not fully capture the clinical ground truth. While data-driven models trained on longitudinal Electronic Health Records often achieve strong empirical performance, they struggle to generalize under missing or novel conditions, largely due to their reliance on observed co-occurrence patterns. To address these issues, we propose Hierarchical Ontology and Network Refinement for Robust Medication Recommendation (HiRef), a unified framework that combines two complementary structures: (i) the hierarchical semantics encoded in curated medical ontologies, and (ii) refined co-occurrence patterns derived from real-world EHRs. We embed ontology entities in hyperbolic space, which naturally captures tree-like relationships and enables knowledge transfer through shared ancestors, thereby improving generalizability to unseen codes. To further improve robustness, we introduce a prior-guided sparse regularization scheme that refines the EHR co-occurrence graph by suppressing spurious edges while preserving clinically meaningful associations. Our model achieves strong performance on EHR benchmarks (MIMIC-III and MIMIC-IV) and maintains high accuracy under simulated unseen-code settings. Extensive experiments with comprehensive ablation studies demonstrate HiRef's resilience to unseen medical codes, supported by in-depth analyses of the learned sparsified graph structure and medical code embeddings.
KU AIGEN ICL EDI@BC8 Track 3: Advancing Phenotype Named Entity Recognition and Normalization for Dysmorphology Physical Examination Reports
Jan 16, 2025

The objective of BioCreative8 Track 3 is to extract phenotypic key medical findings embedded within EHR texts and subsequently normalize these findings to their Human Phenotype Ontology (HPO) terms. However, the presence of diverse surface forms in phenotypic findings makes it challenging to accurately normalize them to the correct HPO terms. To address this challenge, we explored various models for named entity recognition and implemented data augmentation techniques such as synonym marginalization to enhance the normalization step. Our pipeline resulted in an exact extraction and normalization F1 score 2.6\% higher than the mean score of all submissions received in response to the challenge. Furthermore, in terms of the normalization F1 score, our approach surpassed the average performance by 1.9\%. These findings contribute to the advancement of automated medical data extraction and normalization techniques, showcasing potential pathways for future research and application in the biomedical domain.
KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization
Jul 10, 2023In this paper, we introduce CheXOFA, a new pre-trained vision-language model (VLM) for the chest X-ray domain. Our model is initially pre-trained on various multimodal datasets within the general domain before being transferred to the chest X-ray domain. Following a prominent VLM, we unify various domain-specific tasks into a simple sequence-to-sequence schema. It enables the model to effectively learn the required knowledge and skills from limited resources in the domain. Demonstrating superior performance on the benchmark datasets provided by the BioNLP shared task, our model benefits from its training across multiple tasks and domains. With subtle techniques including ensemble and factual calibration, our system achieves first place on the RadSum23 leaderboard for the hidden test set.
KitchenScale: Learning to predict ingredient quantities from recipe contexts
Apr 21, 2023Determining proper quantities for ingredients is an essential part of cooking practice from the perspective of enriching tastiness and promoting healthiness. We introduce KitchenScale, a fine-tuned Pre-trained Language Model (PLM) that predicts a target ingredient's quantity and measurement unit given its recipe context. To effectively train our KitchenScale model, we formulate an ingredient quantity prediction task that consists of three sub-tasks which are ingredient measurement type classification, unit classification, and quantity regression task. Furthermore, we utilized transfer learning of cooking knowledge from recipe texts to PLMs. We adopted the Discrete Latent Exponent (DExp) method to cope with high variance of numerical scales in recipe corpora. Experiments with our newly constructed dataset and recommendation examples demonstrate KitchenScale's understanding of various recipe contexts and generalizability in predicting ingredient quantities. We implemented a web application for KitchenScale to demonstrate its functionality in recommending ingredient quantities expressed in numerals (e.g., 2) with units (e.g., ounce).
* Expert Systems with Applications 2023, Demo: http://kitchenscale.korea.ac.kr/
RecipeMind: Guiding Ingredient Choices from Food Pairing to Recipe Completion using Cascaded Set Transformer
Oct 14, 2022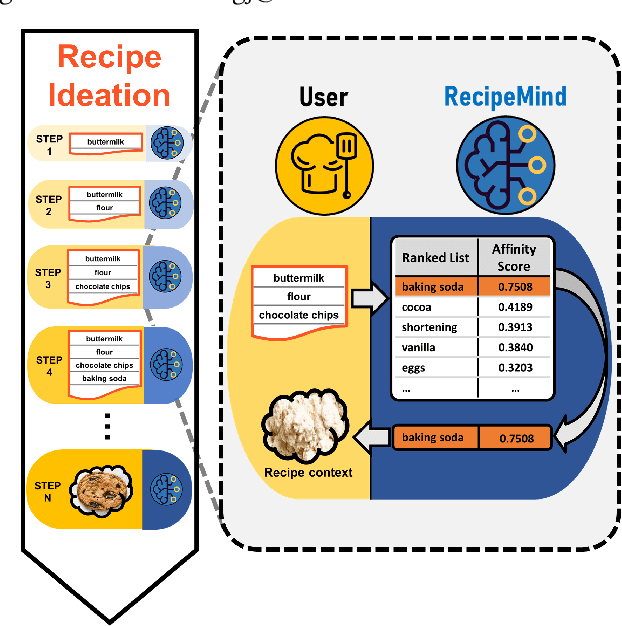
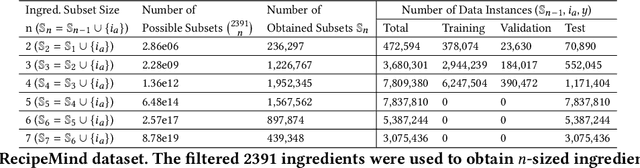
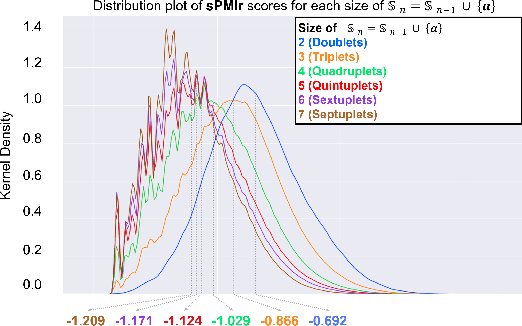
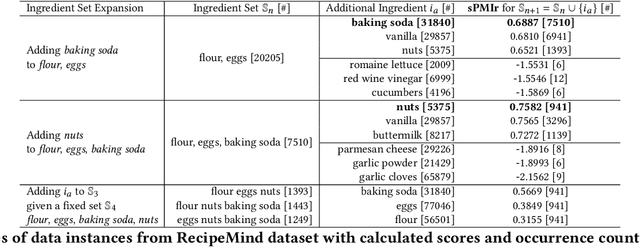
We propose a computational approach for recipe ideation, a downstream task that helps users select and gather ingredients for creating dishes. To perform this task, we developed RecipeMind, a food affinity score prediction model that quantifies the suitability of adding an ingredient to set of other ingredients. We constructed a large-scale dataset containing ingredient co-occurrence based scores to train and evaluate RecipeMind on food affinity score prediction. Deployed in recipe ideation, RecipeMind helps the user expand an initial set of ingredients by suggesting additional ingredients. Experiments and qualitative analysis show RecipeMind's potential in fulfilling its assistive role in cuisine domain.