 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Dec 17, 2025Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
Resolving Ambiguity in Gaze-Facilitated Visual Assistant Interaction Paradigm
Sep 26, 2025With the rise in popularity of smart glasses, users' attention has been integrated into Vision-Language Models (VLMs) to streamline multi-modal querying in daily scenarios. However, leveraging gaze data to model users' attention may introduce ambiguity challenges: (1) users' verbal questions become ambiguous by using pronouns or skipping context, (2) humans' gaze patterns can be noisy and exhibit complex spatiotemporal relationships with their spoken questions. Previous works only consider single image as visual modality input, failing to capture the dynamic nature of the user's attention. In this work, we introduce GLARIFY, a novel method to leverage spatiotemporal gaze information to enhance the model's effectiveness in real-world applications. Initially, we analyzed hundreds of querying samples with the gaze modality to demonstrate the noisy nature of users' gaze patterns. We then utilized GPT-4o to design an automatic data synthesis pipeline to generate the GLARIFY-Ambi dataset, which includes a dedicated chain-of-thought (CoT) process to handle noisy gaze patterns. Finally, we designed a heatmap module to incorporate gaze information into cutting-edge VLMs while preserving their pretrained knowledge. We evaluated GLARIFY using a hold-out test set. Experiments demonstrate that GLARIFY significantly outperforms baselines. By robustly aligning VLMs with human attention, GLARIFY paves the way for a usable and intuitive interaction paradigm with a visual assistant.
Galaxy Walker: Geometry-aware VLMs For Galaxy-scale Understanding
Mar 24, 2025Modern vision-language models (VLMs) develop patch embedding and convolution backbone within vector space, especially Euclidean ones, at the very founding. When expanding VLMs to a galaxy scale for understanding astronomical phenomena, the integration of spherical space for planetary orbits and hyperbolic spaces for black holes raises two formidable challenges. a) The current pre-training model is confined to Euclidean space rather than a comprehensive geometric embedding. b) The predominant architecture lacks suitable backbones for anisotropic physical geometries. In this paper, we introduced Galaxy-Walker, a geometry-aware VLM, for the universe-level vision understanding tasks. We proposed the geometry prompt that generates geometry tokens by random walks across diverse spaces on a multi-scale physical graph, along with a geometry adapter that compresses and reshapes the space anisotropy in a mixture-of-experts manner. Extensive experiments demonstrate the effectiveness of our approach, with Galaxy-Walker achieving state-of-the-art performance in both galaxy property estimation ($R^2$ scores up to $0.91$) and morphology classification tasks (up to $+0.17$ F1 improvement in challenging features), significantly outperforming both domain-specific models and general-purpose VLMs.
DSV: Exploiting Dynamic Sparsity to Accelerate Large-Scale Video DiT Training
Feb 11, 2025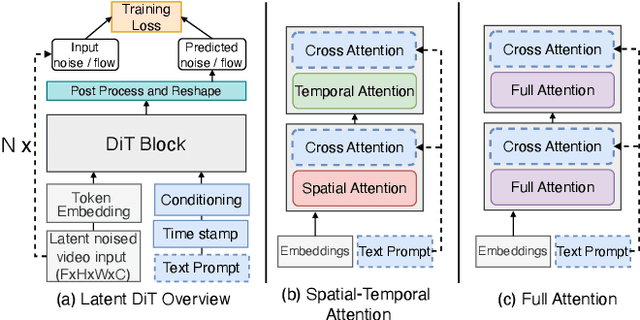

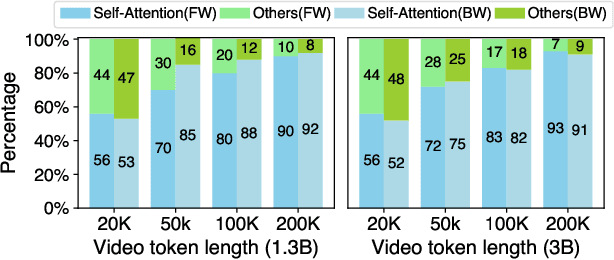
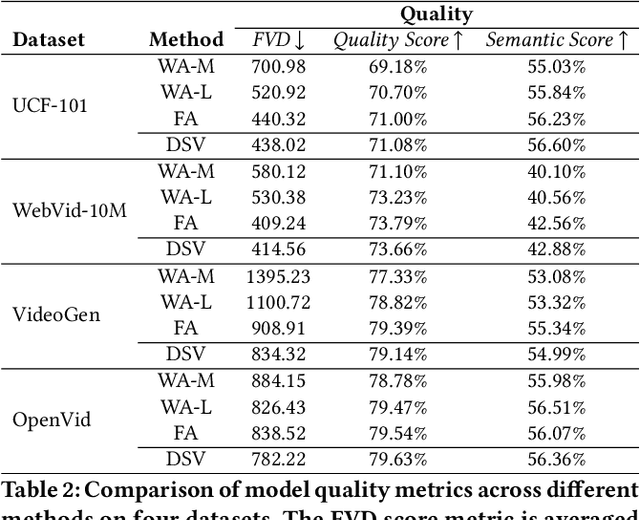
Diffusion Transformers (DiTs) have shown remarkable performance in modeling and generating high-quality videos. However, the quadratic computational complexity of 3D full attention mechanism presents significant challenges in scaling video DiT training, especially for high-definition and lengthy videos, where attention can dominate up to 95% of the end-to-end time and necessitate specialized communication paradigms to handle large input sizes. This paper introduces DSV, a novel framework designed to accelerate and scale the training of video DiTs by leveraging the inherent dynamic attention sparsity throughout the training process. DSV employs a two-stage training algorithm that exploits sparsity patterns, focusing on critical elements supported by efficient, tailored kernels. To accommodate the new sparsity dimension, we develop a hybrid sparsity-aware context parallelism that effectively scales to large inputs by addressing the heterogeneity of sparsity across attention heads and blocks, resulting in optimized sparse computation and communication. Extensive evaluations demonstrate that DSV achieves up to 3.02x gain in training throughput with nearly no quality degradation.
Taming Teacher Forcing for Masked Autoregressive Video Generation
Jan 21, 2025



We introduce MAGI, a hybrid video generation framework that combines masked modeling for intra-frame generation with causal modeling for next-frame generation. Our key innovation, Complete Teacher Forcing (CTF), conditions masked frames on complete observation frames rather than masked ones (namely Masked Teacher Forcing, MTF), enabling a smooth transition from token-level (patch-level) to frame-level autoregressive generation. CTF significantly outperforms MTF, achieving a +23% improvement in FVD scores on first-frame conditioned video prediction. To address issues like exposure bias, we employ targeted training strategies, setting a new benchmark in autoregressive video generation. Experiments show that MAGI can generate long, coherent video sequences exceeding 100 frames, even when trained on as few as 16 frames, highlighting its potential for scalable, high-quality video generation.
Modelling Multi-modal Cross-interaction for ML-FSIC Based on Local Feature Selection
Dec 18, 2024
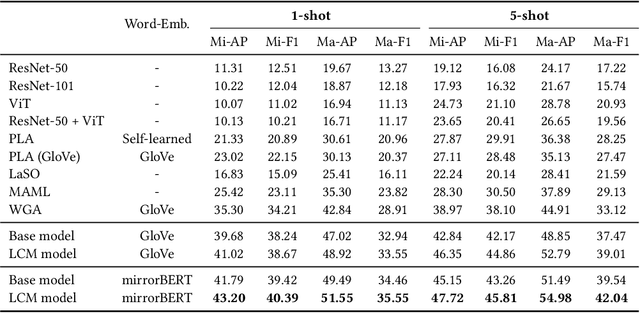

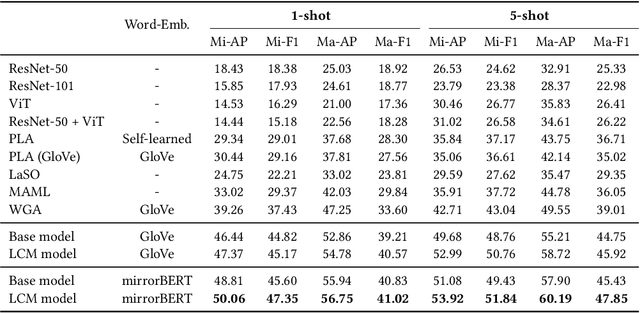
The aim of multi-label few-shot image classification (ML-FSIC) is to assign semantic labels to images, in settings where only a small number of training examples are available for each label. A key feature of the multi-label setting is that images often have several labels, which typically refer to objects appearing in different regions of the image. When estimating label prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data and the noisy nature of local features make this highly challenging. As a solution, we propose a strategy in which label prototypes are gradually refined. First, we initialize the prototypes using word embeddings, which allows us to leverage prior knowledge about the meaning of the labels. Second, taking advantage of these initial prototypes, we then use a Loss Change Measurement~(LCM) strategy to select the local features from the training images (i.e.\ the support set) that are most likely to be representative of a given label. Third, we construct the final prototype of the label by aggregating these representative local features using a multi-modal cross-interaction mechanism, which again relies on the initial word embedding-based prototypes. Experiments on COCO, PASCAL VOC, NUS-WIDE, and iMaterialist show that our model substantially improves the current state-of-the-art.
Hypergraph Multi-modal Large Language Model: Exploiting EEG and Eye-tracking Modalities to Evaluate Heterogeneous Responses for Video Understanding
Jul 11, 2024



Understanding of video creativity and content often varies among individuals, with differences in focal points and cognitive levels across different ages, experiences, and genders. There is currently a lack of research in this area, and most existing benchmarks suffer from several drawbacks: 1) a limited number of modalities and answers with restrictive length; 2) the content and scenarios within the videos are excessively monotonous, transmitting allegories and emotions that are overly simplistic. To bridge the gap to real-world applications, we introduce a large-scale \textbf{S}ubjective \textbf{R}esponse \textbf{I}ndicators for \textbf{A}dvertisement \textbf{V}ideos dataset, namely SRI-ADV. Specifically, we collected real changes in Electroencephalographic (EEG) and eye-tracking regions from different demographics while they viewed identical video content. Utilizing this multi-modal dataset, we developed tasks and protocols to analyze and evaluate the extent of cognitive understanding of video content among different users. Along with the dataset, we designed a \textbf{H}ypergraph \textbf{M}ulti-modal \textbf{L}arge \textbf{L}anguage \textbf{M}odel (HMLLM) to explore the associations among different demographics, video elements, EEG and eye-tracking indicators. HMLLM could bridge semantic gaps across rich modalities and integrate information beyond different modalities to perform logical reasoning. Extensive experimental evaluations on SRI-ADV and other additional video-based generative performance benchmarks demonstrate the effectiveness of our method. The codes and dataset will be released at \url{https://github.com/suay1113/HMLLM}.
G-VOILA: Gaze-Facilitated Information Querying in Daily Scenarios
May 13, 2024Modern information querying systems are progressively incorporating multimodal inputs like vision and audio. However, the integration of gaze -- a modality deeply linked to user intent and increasingly accessible via gaze-tracking wearables -- remains underexplored. This paper introduces a novel gaze-facilitated information querying paradigm, named G-VOILA, which synergizes users' gaze, visual field, and voice-based natural language queries to facilitate a more intuitive querying process. In a user-enactment study involving 21 participants in 3 daily scenarios (p = 21, scene = 3), we revealed the ambiguity in users' query language and a gaze-voice coordination pattern in users' natural query behaviors with G-VOILA. Based on the quantitative and qualitative findings, we developed a design framework for the G-VOILA paradigm, which effectively integrates the gaze data with the in-situ querying context. Then we implemented a G-VOILA proof-of-concept using cutting-edge deep learning techniques. A follow-up user study (p = 16, scene = 2) demonstrates its effectiveness by achieving both higher objective score and subjective score, compared to a baseline without gaze data. We further conducted interviews and provided insights for future gaze-facilitated information querying systems.
KU-DMIS-MSRA at RadSum23: Pre-trained Vision-Language Model for Radiology Report Summarization
Jul 10, 2023In this paper, we introduce CheXOFA, a new pre-trained vision-language model (VLM) for the chest X-ray domain. Our model is initially pre-trained on various multimodal datasets within the general domain before being transferred to the chest X-ray domain. Following a prominent VLM, we unify various domain-specific tasks into a simple sequence-to-sequence schema. It enables the model to effectively learn the required knowledge and skills from limited resources in the domain. Demonstrating superior performance on the benchmark datasets provided by the BioNLP shared task, our model benefits from its training across multiple tasks and domains. With subtle techniques including ensemble and factual calibration, our system achieves first place on the RadSum23 leaderboard for the hidden test set.
GroundNLQ @ Ego4D Natural Language Queries Challenge 2023
Jun 27, 2023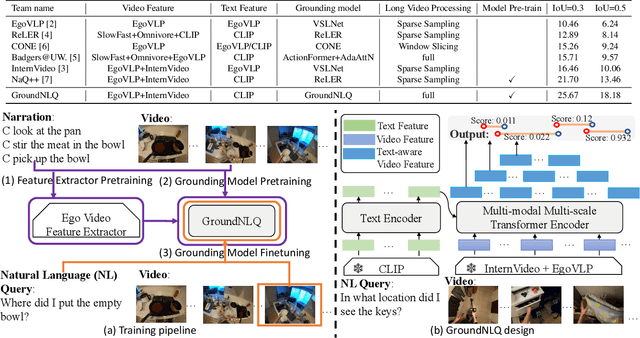
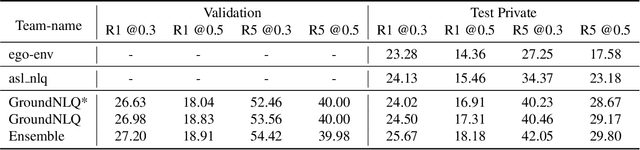

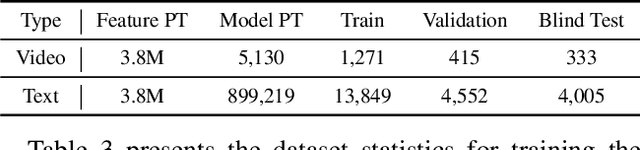
In this report, we present our champion solution for Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2023. Essentially, to accurately ground in a video, an effective egocentric feature extractor and a powerful grounding model are required. Motivated by this, we leverage a two-stage pre-training strategy to train egocentric feature extractors and the grounding model on video narrations, and further fine-tune the model on annotated data. In addition, we introduce a novel grounding model GroundNLQ, which employs a multi-modal multi-scale grounding module for effective video and text fusion and various temporal intervals, especially for long videos. On the blind test set, GroundNLQ achieves 25.67 and 18.18 for R1@IoU=0.3 and R1@IoU=0.5, respectively, and surpasses all other teams by a noticeable margin. Our code will be released at\url{https://github.com/houzhijian/GroundNLQ}.