 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025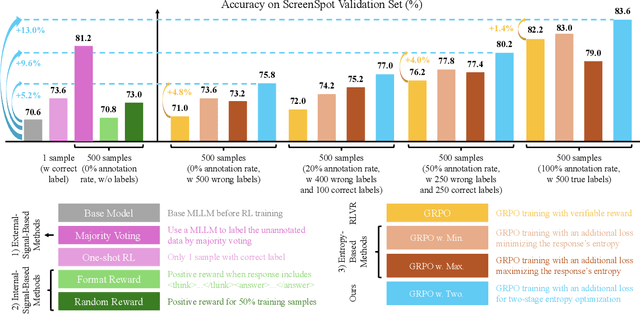



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
GroundNLQ @ Ego4D Natural Language Queries Challenge 2023
Jun 27, 2023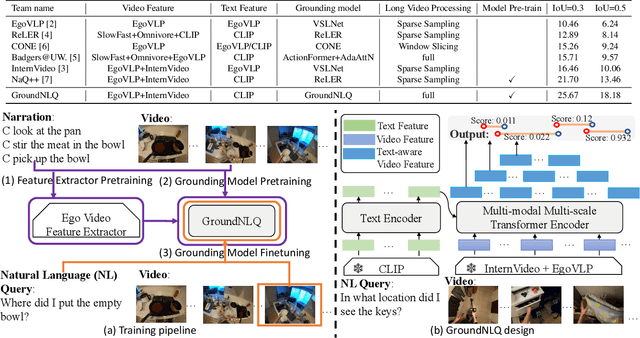
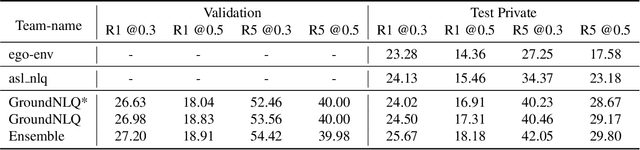

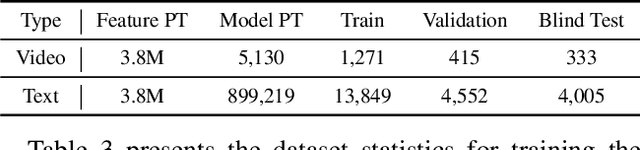
In this report, we present our champion solution for Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2023. Essentially, to accurately ground in a video, an effective egocentric feature extractor and a powerful grounding model are required. Motivated by this, we leverage a two-stage pre-training strategy to train egocentric feature extractors and the grounding model on video narrations, and further fine-tune the model on annotated data. In addition, we introduce a novel grounding model GroundNLQ, which employs a multi-modal multi-scale grounding module for effective video and text fusion and various temporal intervals, especially for long videos. On the blind test set, GroundNLQ achieves 25.67 and 18.18 for R1@IoU=0.3 and R1@IoU=0.5, respectively, and surpasses all other teams by a noticeable margin. Our code will be released at\url{https://github.com/houzhijian/GroundNLQ}.
An Efficient COarse-to-fiNE Alignment Framework @ Ego4D Natural Language Queries Challenge 2022
Nov 16, 2022



This technical report describes the CONE approach for Ego4D Natural Language Queries (NLQ) Challenge in ECCV 2022. We leverage our model CONE, an efficient window-centric COarse-to-fiNE alignment framework. Specifically, CONE dynamically slices the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of the contrastive vision-text pre-trained model EgoVLP. On the blind test set, CONE achieves 15.26 and 9.24 for R1@IoU=0.3 and R1@IoU=0.5, respectively.
CONE: An Efficient COarse-to-fiNE Alignment Framework for Long Video Temporal Grounding
Sep 22, 2022

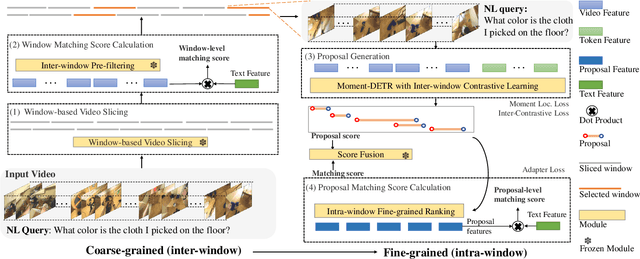
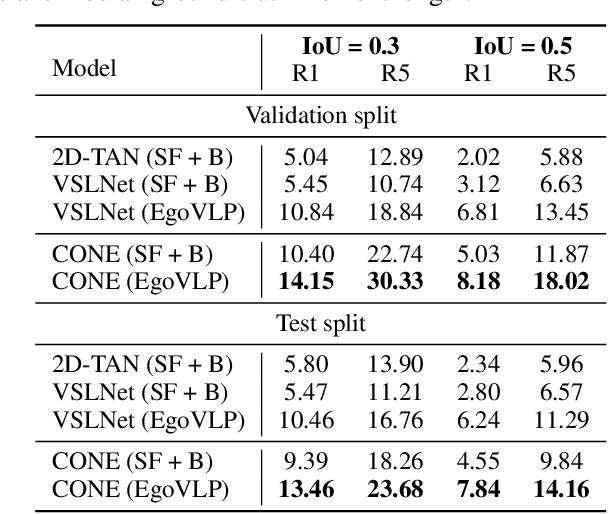
Video temporal grounding (VTG) targets to localize temporal moments in an untrimmed video according to a natural language (NL) description. Since real-world applications provide a never-ending video stream, it raises demands for temporal grounding for long-form videos, which leads to two major challenges: (1) the long video length makes it difficult to process the entire video without decreasing sample rate and leads to high computational burden; (2) the accurate multi-modal alignment is more challenging as the number of moment candidates increases. To address these challenges, we propose CONE, an efficient window-centric COarse-to-fiNE alignment framework, which flexibly handles long-form video inputs with higher inference speed, and enhances the temporal grounding via our novel coarse-to-fine multi-modal alignment framework. Specifically, we dynamically slice the long video into candidate windows via a sliding window approach. Centering at windows, CONE (1) learns the inter-window (coarse-grained) semantic variance through contrastive learning and speeds up inference by pre-filtering the candidate windows relevant to the NL query, and (2) conducts intra-window (fine-grained) candidate moments ranking utilizing the powerful multi-modal alignment ability of a contrastive vision-text pre-trained model. Extensive experiments on two large-scale VTG benchmarks for long videos consistently show a substantial performance gain (from 3.13% to 6.87% on MAD and from 10.46% to 13.46% on Ego4d-NLQ) and CONE achieves the SOTA results on both datasets. Analysis reveals the effectiveness of components and higher efficiency in long video grounding as our system improves the inference speed by 2x on Ego4d-NLQ and 15x on MAD while keeping the SOTA performance of CONE.
(Un)likelihood Training for Interpretable Embedding
Jul 01, 2022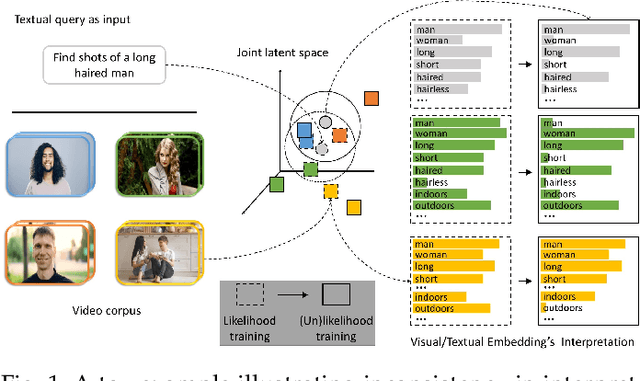
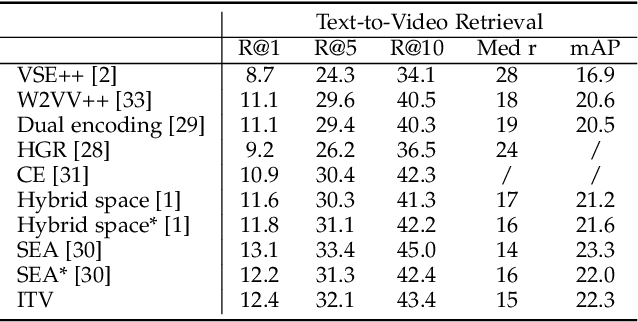
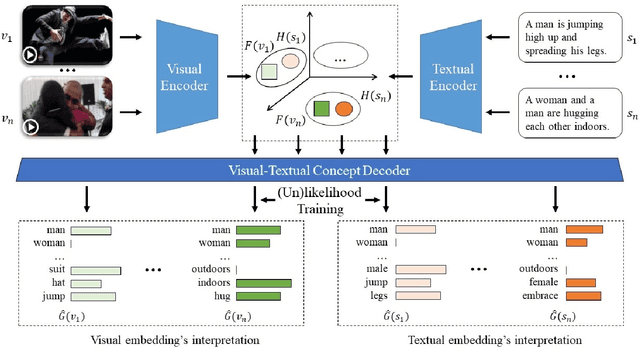
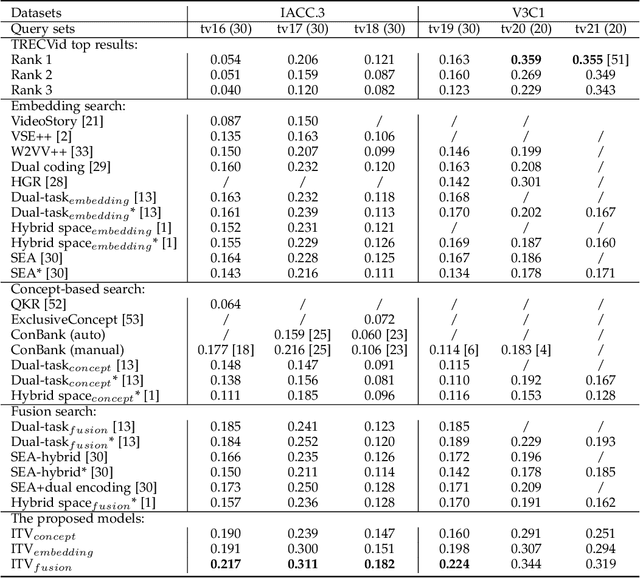
Cross-modal representation learning has become a new normal for bridging the semantic gap between text and visual data. Learning modality agnostic representations in a continuous latent space, however, is often treated as a black-box data-driven training process. It is well-known that the effectiveness of representation learning depends heavily on the quality and scale of training data. For video representation learning, having a complete set of labels that annotate the full spectrum of video content for training is highly difficult if not impossible. These issues, black-box training and dataset bias, make representation learning practically challenging to be deployed for video understanding due to unexplainable and unpredictable results. In this paper, we propose two novel training objectives, likelihood and unlikelihood functions, to unroll semantics behind embeddings while addressing the label sparsity problem in training. The likelihood training aims to interpret semantics of embeddings beyond training labels, while the unlikelihood training leverages prior knowledge for regularization to ensure semantically coherent interpretation. With both training objectives, a new encoder-decoder network, which learns interpretable cross-modal representation, is proposed for ad-hoc video search. Extensive experiments on TRECVid and MSR-VTT datasets show the proposed network outperforms several state-of-the-art retrieval models with a statistically significant performance margin.
CONQUER: Contextual Query-aware Ranking for Video Corpus Moment Retrieval
Sep 21, 2021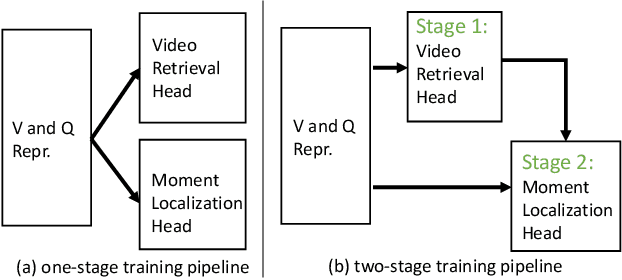

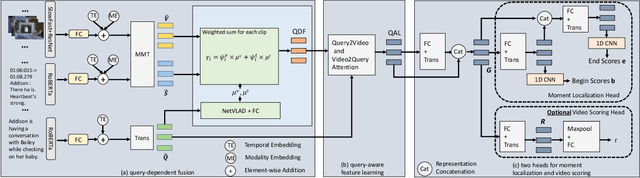

This paper tackles a recently proposed Video Corpus Moment Retrieval task. This task is essential because advanced video retrieval applications should enable users to retrieve a precise moment from a large video corpus. We propose a novel CONtextual QUery-awarE Ranking~(CONQUER) model for effective moment localization and ranking. CONQUER explores query context for multi-modal fusion and representation learning in two different steps. The first step derives fusion weights for the adaptive combination of multi-modal video content. The second step performs bi-directional attention to tightly couple video and query as a single joint representation for moment localization. As query context is fully engaged in video representation learning, from feature fusion to transformation, the resulting feature is user-centered and has a larger capacity in capturing multi-modal signals specific to query. We conduct studies on two datasets, TVR for closed-world TV episodes and DiDeMo for open-world user-generated videos, to investigate the potential advantages of fusing video and query online as a joint representation for moment retrieval.
vireoJD-MM at Activity Detection in Extended Videos
Jun 20, 2019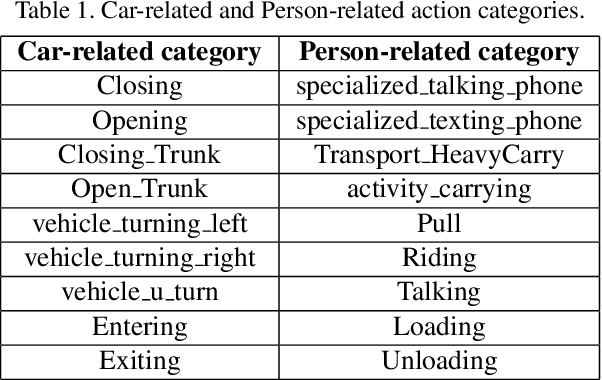
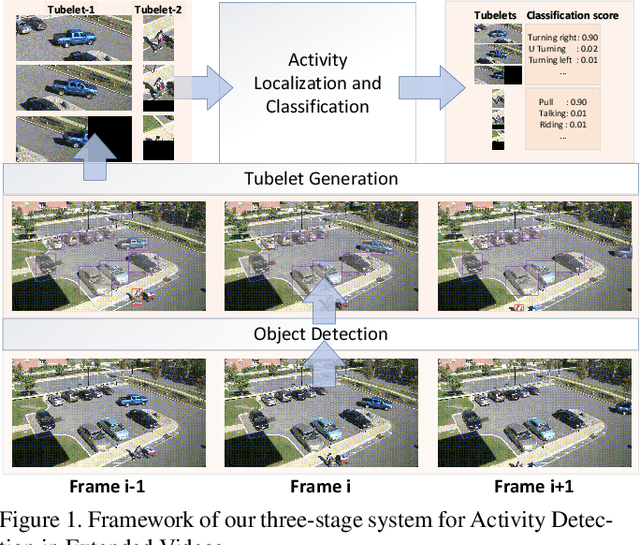
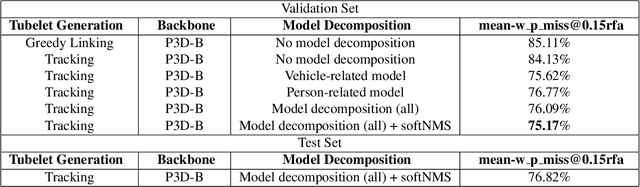
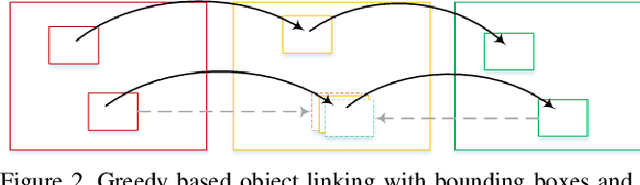
This notebook paper presents an overview and comparative analysis of our system designed for activity detection in extended videos (ActEV-PC) in ActivityNet Challenge 2019. Specifically, we exploit person/vehicle detections in spatial level and action localization in temporal level for action detection in surveillance videos. The mechanism of different tubelet generation and model decomposition methods are studied as well. The detection results are finally predicted by late fusing the results from each component.