 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unbiased Cross-Modal Representation Learning for Food Image-to-Recipe Retrieval
Nov 19, 2025This paper addresses the challenges of learning representations for recipes and food images in the cross-modal retrieval problem. As the relationship between a recipe and its cooked dish is cause-and-effect, treating a recipe as a text source describing the visual appearance of a dish for learning representation, as the existing approaches, will create bias misleading image-and-recipe similarity judgment. Specifically, a food image may not equally capture every detail in a recipe, due to factors such as the cooking process, dish presentation, and image-capturing conditions. The current representation learning tends to capture dominant visual-text alignment while overlooking subtle variations that determine retrieval relevance. In this paper, we model such bias in cross-modal representation learning using causal theory. The causal view of this problem suggests ingredients as one of the confounder sources and a simple backdoor adjustment can alleviate the bias. By causal intervention, we reformulate the conventional model for food-to-recipe retrieval with an additional term to remove the potential bias in similarity judgment. Based on this theory-informed formulation, we empirically prove the oracle performance of retrieval on the Recipe1M dataset to be MedR=1 across the testing data sizes of 1K, 10K, and even 50K. We also propose a plug-and-play neural module, which is essentially a multi-label ingredient classifier for debiasing. New state-of-the-art search performances are reported on the Recipe1M dataset.
Mitigating Cross-modal Representation Bias for Multicultural Image-to-Recipe Retrieval
Oct 23, 2025Existing approaches for image-to-recipe retrieval have the implicit assumption that a food image can fully capture the details textually documented in its recipe. However, a food image only reflects the visual outcome of a cooked dish and not the underlying cooking process. Consequently, learning cross-modal representations to bridge the modality gap between images and recipes tends to ignore subtle, recipe-specific details that are not visually apparent but are crucial for recipe retrieval. Specifically, the representations are biased to capture the dominant visual elements, resulting in difficulty in ranking similar recipes with subtle differences in use of ingredients and cooking methods. The bias in representation learning is expected to be more severe when the training data is mixed of images and recipes sourced from different cuisines. This paper proposes a novel causal approach that predicts the culinary elements potentially overlooked in images, while explicitly injecting these elements into cross-modal representation learning to mitigate biases. Experiments are conducted on the standard monolingual Recipe1M dataset and a newly curated multilingual multicultural cuisine dataset. The results indicate that the proposed causal representation learning is capable of uncovering subtle ingredients and cooking actions and achieves impressive retrieval performance on both monolingual and multilingual multicultural datasets.
Robust Relevance Feedback for Interactive Known-Item Video Search
May 21, 2025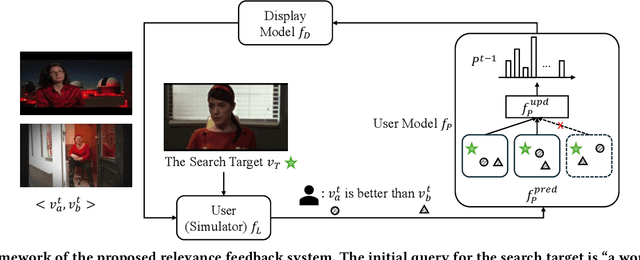



Known-item search (KIS) involves only a single search target, making relevance feedback-typically a powerful technique for efficiently identifying multiple positive examples to infer user intent-inapplicable. PicHunter addresses this issue by asking users to select the top-k most similar examples to the unique search target from a displayed set. Under ideal conditions, when the user's perception aligns closely with the machine's perception of similarity, consistent and precise judgments can elevate the target to the top position within a few iterations. However, in practical scenarios, expecting users to provide consistent judgments is often unrealistic, especially when the underlying embedding features used for similarity measurements lack interpretability. To enhance robustness, we first introduce a pairwise relative judgment feedback that improves the stability of top-k selections by mitigating the impact of misaligned feedback. Then, we decompose user perception into multiple sub-perceptions, each represented as an independent embedding space. This approach assumes that users may not consistently align with a single representation but are more likely to align with one or several among multiple representations. We develop a predictive user model that estimates the combination of sub-perceptions based on each user feedback instance. The predictive user model is then trained to filter out the misaligned sub-perceptions. Experimental evaluations on the large-scale open-domain dataset V3C indicate that the proposed model can optimize over 60% search targets to the top rank when their initial ranks at the search depth between 10 and 50. Even for targets initially ranked between 1,000 and 5,000, the model achieves a success rate exceeding 40% in optimizing ranks to the top, demonstrating the enhanced robustness of relevance feedback in KIS despite inconsistent feedback.
Advancing Food Nutrition Estimation via Visual-Ingredient Feature Fusion
May 13, 2025Nutrition estimation is an important component of promoting healthy eating and mitigating diet-related health risks. Despite advances in tasks such as food classification and ingredient recognition, progress in nutrition estimation is limited due to the lack of datasets with nutritional annotations. To address this issue, we introduce FastFood, a dataset with 84,446 images across 908 fast food categories, featuring ingredient and nutritional annotations. In addition, we propose a new model-agnostic Visual-Ingredient Feature Fusion (VIF$^2$) method to enhance nutrition estimation by integrating visual and ingredient features. Ingredient robustness is improved through synonym replacement and resampling strategies during training. The ingredient-aware visual feature fusion module combines ingredient features and visual representation to achieve accurate nutritional prediction. During testing, ingredient predictions are refined using large multimodal models by data augmentation and majority voting. Our experiments on both FastFood and Nutrition5k datasets validate the effectiveness of our proposed method built in different backbones (e.g., Resnet, InceptionV3 and ViT), which demonstrates the importance of ingredient information in nutrition estimation. https://huiyanqi.github.io/fastfood-nutrition-estimation/.
Don't Deceive Me: Mitigating Gaslighting through Attention Reallocation in LMMs
Apr 13, 2025



Large Multimodal Models (LMMs) have demonstrated remarkable capabilities across a wide range of tasks. However, their vulnerability to user gaslighting-the deliberate use of misleading or contradictory inputs-raises critical concerns about their reliability in real-world applications. In this paper, we address the novel and challenging issue of mitigating the negative impact of negation-based gaslighting on LMMs, where deceptive user statements lead to significant drops in model accuracy. Specifically, we introduce GasEraser, a training-free approach that reallocates attention weights from misleading textual tokens to semantically salient visual regions. By suppressing the influence of "attention sink" tokens and enhancing focus on visually grounded cues, GasEraser significantly improves LMM robustness without requiring retraining or additional supervision. Extensive experimental results demonstrate that GasEraser is effective across several leading open-source LMMs on the GaslightingBench. Notably, for LLaVA-v1.5-7B, GasEraser reduces the misguidance rate by 48.2%, demonstrating its potential for more trustworthy LMMs.
Calling a Spade a Heart: Gaslighting Multimodal Large Language Models via Negation
Jan 31, 2025



Multimodal Large Language Models (MLLMs) have exhibited remarkable advancements in integrating different modalities, excelling in complex understanding and generation tasks. Despite their success, MLLMs remain vulnerable to conversational adversarial inputs, particularly negation arguments. This paper systematically evaluates state-of-the-art MLLMs across diverse benchmarks, revealing significant performance drops when negation arguments are introduced to initially correct responses. We show critical vulnerabilities in the reasoning and alignment mechanisms of these models. Proprietary models such as GPT-4o and Claude-3.5-Sonnet demonstrate better resilience compared to open-source counterparts like Qwen2-VL and LLaVA. However, all evaluated MLLMs struggle to maintain logical consistency under negation arguments during conversation. This paper aims to offer valuable insights for improving the robustness of MLLMs against adversarial inputs, contributing to the development of more reliable and trustworthy multimodal AI systems.
CookingDiffusion: Cooking Procedural Image Generation with Stable Diffusion
Jan 15, 2025



Recent advancements in text-to-image generation models have excelled in creating diverse and realistic images. This success extends to food imagery, where various conditional inputs like cooking styles, ingredients, and recipes are utilized. However, a yet-unexplored challenge is generating a sequence of procedural images based on cooking steps from a recipe. This could enhance the cooking experience with visual guidance and possibly lead to an intelligent cooking simulation system. To fill this gap, we introduce a novel task called \textbf{cooking procedural image generation}. This task is inherently demanding, as it strives to create photo-realistic images that align with cooking steps while preserving sequential consistency. To collectively tackle these challenges, we present \textbf{CookingDiffusion}, a novel approach that leverages Stable Diffusion and three innovative Memory Nets to model procedural prompts. These prompts encompass text prompts (representing cooking steps), image prompts (corresponding to cooking images), and multi-modal prompts (mixing cooking steps and images), ensuring the consistent generation of cooking procedural images. To validate the effectiveness of our approach, we preprocess the YouCookII dataset, establishing a new benchmark. Our experimental results demonstrate that our model excels at generating high-quality cooking procedural images with remarkable consistency across sequential cooking steps, as measured by both the FID and the proposed Average Procedure Consistency metrics. Furthermore, CookingDiffusion demonstrates the ability to manipulate ingredients and cooking methods in a recipe. We will make our code, models, and dataset publicly accessible.
PolySmart and VIREO @ TRECVid 2024 Ad-hoc Video Search
Dec 20, 2024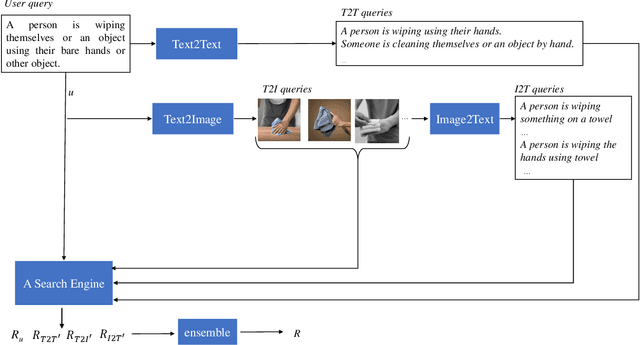


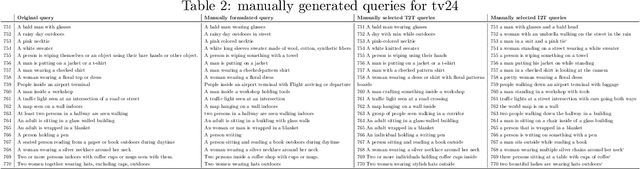
This year, we explore generation-augmented retrieval for the TRECVid AVS task. Specifically, the understanding of textual query is enhanced by three generations, including Text2Text, Text2Image, and Image2Text, to address the out-of-vocabulary problem. Using different combinations of them and the rank list retrieved by the original query, we submitted four automatic runs. For manual runs, we use a large language model (LLM) (i.e., GPT4) to rephrase test queries based on the concept bank of the search engine, and we manually check again to ensure all the concepts used in the rephrased queries are in the bank. The result shows that the fusion of the original and generated queries outperforms the original query on TV24 query sets. The generated queries retrieve different rank lists from the original query.
Visual Cue Enhancement and Dual Low-Rank Adaptation for Efficient Visual Instruction Fine-Tuning
Nov 19, 2024Fine-tuning multimodal large language models (MLLMs) presents significant challenges, including a reliance on high-level visual features that limits fine-grained detail comprehension, and data conflicts that arise from task complexity. To address these issues, we propose an efficient fine-tuning framework with two novel approaches: Vision Cue Enhancement (VCE) and Dual Low-Rank Adaptation (Dual-LoRA). VCE enhances the vision projector by integrating multi-level visual cues, improving the model's ability to capture fine-grained visual features. Dual-LoRA introduces a dual low-rank structure for instruction tuning, decoupling learning into skill and task spaces to enable precise control and efficient adaptation across diverse tasks. Our method simplifies implementation, enhances visual comprehension, and improves adaptability. Experiments on both downstream tasks and general benchmarks demonstrate the effectiveness of our proposed approach.
Retrieval Augmented Recipe Generation
Nov 13, 2024Given the potential applications of generating recipes from food images, this area has garnered significant attention from researchers in recent years. Existing works for recipe generation primarily utilize a two-stage training method, first generating ingredients and then obtaining instructions from both the image and ingredients. Large Multi-modal Models (LMMs), which have achieved notable success across a variety of vision and language tasks, shed light to generating both ingredients and instructions directly from images. Nevertheless, LMMs still face the common issue of hallucinations during recipe generation, leading to suboptimal performance. To tackle this, we propose a retrieval augmented large multimodal model for recipe generation. We first introduce Stochastic Diversified Retrieval Augmentation (SDRA) to retrieve recipes semantically related to the image from an existing datastore as a supplement, integrating them into the prompt to add diverse and rich context to the input image. Additionally, Self-Consistency Ensemble Voting mechanism is proposed to determine the most confident prediction recipes as the final output. It calculates the consistency among generated recipe candidates, which use different retrieval recipes as context for generation. Extensive experiments validate the effectiveness of our proposed method, which demonstrates state-of-the-art (SOTA) performance in recipe generation tasks on the Recipe1M dataset.