 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSteerNet: Human Reaction Generation from Videos via Observation-Reaction Mutual Steering
Mar 20, 2026Video-driven human reaction generation aims to synthesize 3D human motions that directly react to observed video sequences, which is crucial for building human-like interactive AI systems. However, existing methods often fail to effectively leverage video inputs to steer human reaction synthesis, resulting in reaction motions that are mismatched with the content of video sequences. We reveal that this limitation arises from a severe relational distortion between visual observations and reaction types. In light of this, we propose MuSteerNet, a simple yet effective framework that generates 3D human reactions from videos via observation-reaction mutual steering. Specifically, we first propose a Prototype Feedback Steering mechanism to mitigate relational distortion by refining visual observations with a gated delta-rectification modulator and a relational margin constraint, guided by prototypical vectors learned from human reactions. We then introduce Dual-Coupled Reaction Refinement that fully leverages rectified visual cues to further steer the refinement of generated reaction motions, thereby effectively improving reaction quality and enabling MuSteerNet to achieve competitive performance. Extensive experiments and ablation studies validate the effectiveness of our method. Code coming soon: https://github.com/zhouyuan888888/MuSteerNet.
CookingDiffusion: Cooking Procedural Image Generation with Stable Diffusion
Jan 15, 2025



Recent advancements in text-to-image generation models have excelled in creating diverse and realistic images. This success extends to food imagery, where various conditional inputs like cooking styles, ingredients, and recipes are utilized. However, a yet-unexplored challenge is generating a sequence of procedural images based on cooking steps from a recipe. This could enhance the cooking experience with visual guidance and possibly lead to an intelligent cooking simulation system. To fill this gap, we introduce a novel task called \textbf{cooking procedural image generation}. This task is inherently demanding, as it strives to create photo-realistic images that align with cooking steps while preserving sequential consistency. To collectively tackle these challenges, we present \textbf{CookingDiffusion}, a novel approach that leverages Stable Diffusion and three innovative Memory Nets to model procedural prompts. These prompts encompass text prompts (representing cooking steps), image prompts (corresponding to cooking images), and multi-modal prompts (mixing cooking steps and images), ensuring the consistent generation of cooking procedural images. To validate the effectiveness of our approach, we preprocess the YouCookII dataset, establishing a new benchmark. Our experimental results demonstrate that our model excels at generating high-quality cooking procedural images with remarkable consistency across sequential cooking steps, as measured by both the FID and the proposed Average Procedure Consistency metrics. Furthermore, CookingDiffusion demonstrates the ability to manipulate ingredients and cooking methods in a recipe. We will make our code, models, and dataset publicly accessible.
Enhancing Zero-Shot Vision Models by Label-Free Prompt Distribution Learning and Bias Correcting
Oct 25, 2024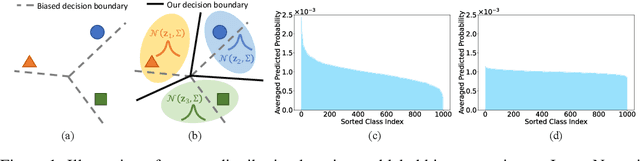

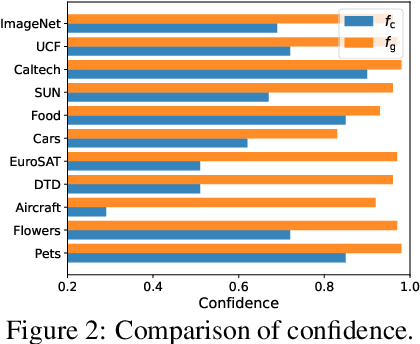

Vision-language models, such as CLIP, have shown impressive generalization capacities when using appropriate text descriptions. While optimizing prompts on downstream labeled data has proven effective in improving performance, these methods entail labor costs for annotations and are limited by their quality. Additionally, since CLIP is pre-trained on highly imbalanced Web-scale data, it suffers from inherent label bias that leads to suboptimal performance. To tackle the above challenges, we propose a label-Free prompt distribution learning and bias correction framework, dubbed as **Frolic**, which boosts zero-shot performance without the need for labeled data. Specifically, our Frolic learns distributions over prompt prototypes to capture diverse visual representations and adaptively fuses these with the original CLIP through confidence matching. This fused model is further enhanced by correcting label bias via a label-free logit adjustment. Notably, our method is not only training-free but also circumvents the necessity for hyper-parameter tuning. Extensive experimental results across 16 datasets demonstrate the efficacy of our approach, particularly outperforming the state-of-the-art by an average of $2.6\%$ on 10 datasets with CLIP ViT-B/16 and achieving an average margin of $1.5\%$ on ImageNet and its five distribution shifts with CLIP ViT-B/16. Codes are available in https://github.com/zhuhsingyuu/Frolic.
Selective Vision-Language Subspace Projection for Few-shot CLIP
Jul 26, 2024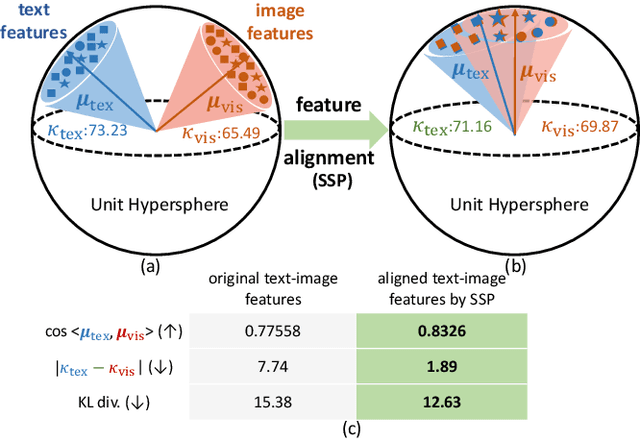
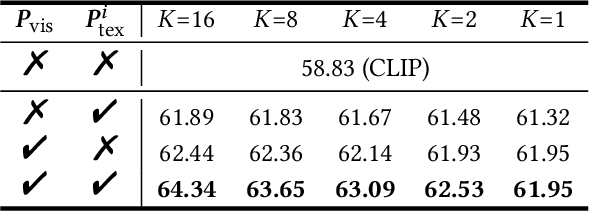

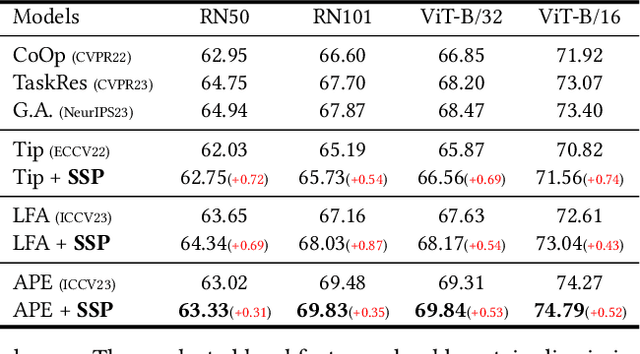
Vision-language models such as CLIP are capable of mapping the different modality data into a unified feature space, enabling zero/few-shot inference by measuring the similarity of given images and texts. However, most existing methods overlook modality gaps in CLIP's encoded features, which is shown as the text and image features lie far apart from each other, resulting in limited classification performance. To tackle this issue, we introduce a method called Selective Vision-Language Subspace Projection (SSP), which incorporates local image features and utilizes them as a bridge to enhance the alignment between image-text pairs. Specifically, our SSP framework comprises two parallel modules: a vision projector and a language projector. Both projectors utilize local image features to span the respective subspaces for image and texts, thereby projecting the image and text features into their respective subspaces to achieve alignment. Moreover, our approach entails only training-free matrix calculations and can be seamlessly integrated into advanced CLIP-based few-shot learning frameworks. Extensive experiments on 11 datasets have demonstrated SSP's superior text-image alignment capabilities, outperforming the state-of-the-art alignment methods. The code is available at https://github.com/zhuhsingyuu/SSP
Selective Volume Mixup for Video Action Recognition
Sep 18, 2023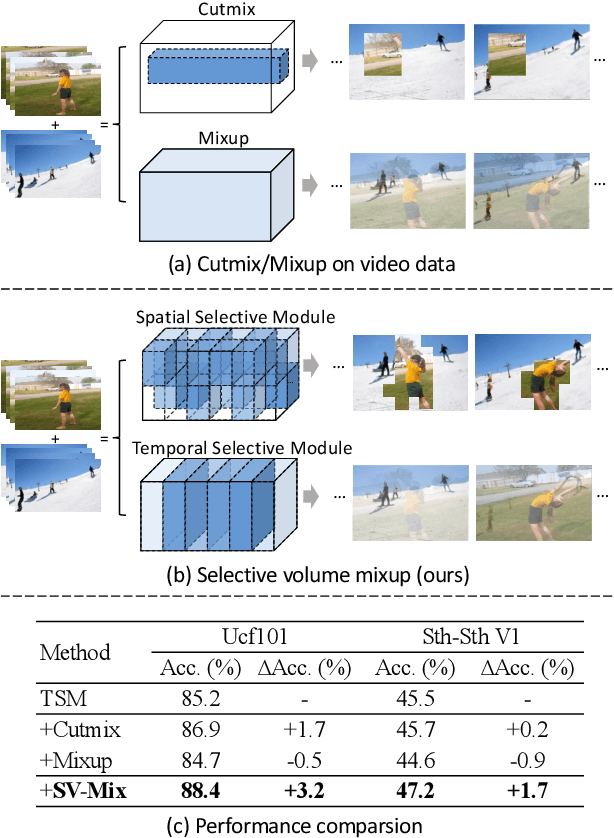
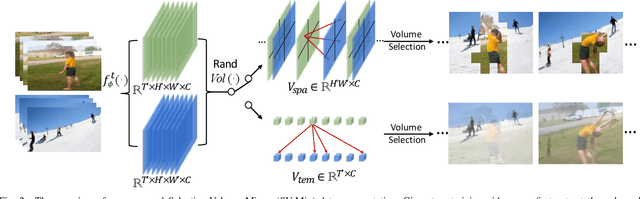
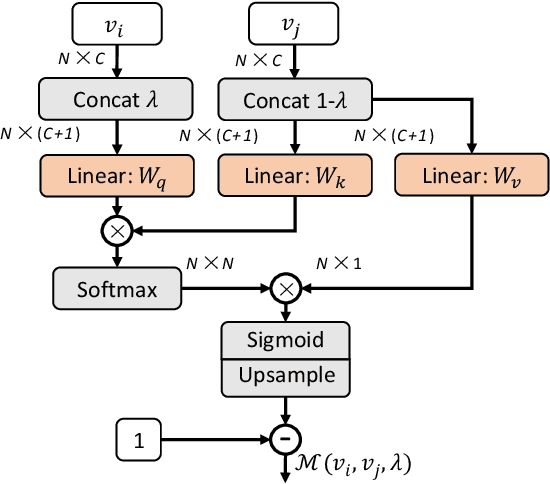
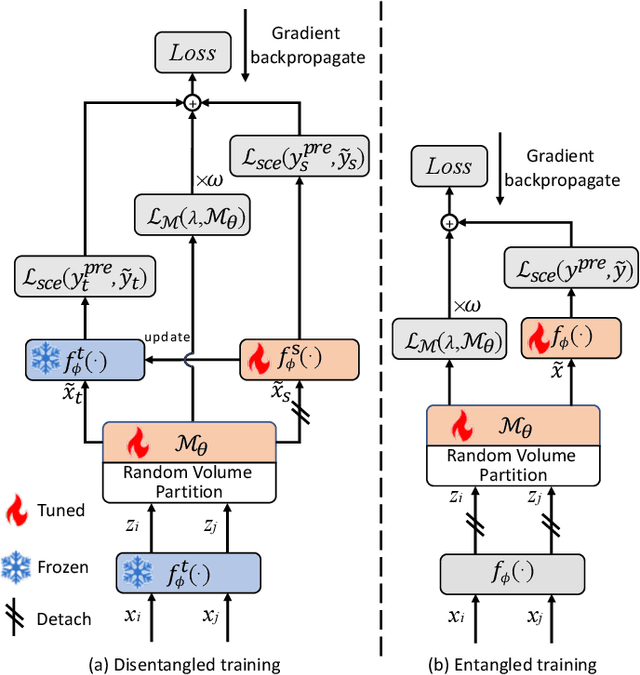
The recent advances in Convolutional Neural Networks (CNNs) and Vision Transformers have convincingly demonstrated high learning capability for video action recognition on large datasets. Nevertheless, deep models often suffer from the overfitting effect on small-scale datasets with a limited number of training videos. A common solution is to exploit the existing image augmentation strategies for each frame individually including Mixup, Cutmix, and RandAugment, which are not particularly optimized for video data. In this paper, we propose a novel video augmentation strategy named Selective Volume Mixup (SV-Mix) to improve the generalization ability of deep models with limited training videos. SV-Mix devises a learnable selective module to choose the most informative volumes from two videos and mixes the volumes up to achieve a new training video. Technically, we propose two new modules, i.e., a spatial selective module to select the local patches for each spatial position, and a temporal selective module to mix the entire frames for each timestamp and maintain the spatial pattern. At each time, we randomly choose one of the two modules to expand the diversity of training samples. The selective modules are jointly optimized with the video action recognition framework to find the optimal augmentation strategy. We empirically demonstrate the merits of the SV-Mix augmentation on a wide range of video action recognition benchmarks and consistently boot the performances of both CNN-based and transformer-based models.