 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftCap: Soft-Budget Control for Diffusion Transformer Acceleration
May 26, 2026Diffusion Transformers (DiTs) achieve strong visual quality, but their iterative denoising process requires many costly Transformer evaluations. Training-free acceleration methods reduce this cost by caching, forecasting, or verifying intermediate features, yet the runtime decision of when to execute a Full step is often driven by fixed schedules or hand-tuned thresholds. We propose \textbf{SoftCap}, a training-free control layer for cache-based DiT inference. SoftCap couples a Trajectory Drift Observer, which estimates local cache risk from lightweight hidden-state statistics, with a Soft-Budget PI Controller, which adjusts the Full-triggering threshold from realized compute relative to a fixed reference profile. The budget is a soft ceiling: it shapes the threshold but does not require a run to spend a prescribed number of Full evaluations. On FLUX.1-dev, SoftCap improves over SpeCa at a comparable middle-compute operating point, raising ImageReward from 0.967 to 0.981 and reducing LPIPS-Full from 0.518 to 0.498 at nearly identical FLOPs, while target-sweep diagnostics show the intended soft-ceiling behavior as the budget is relaxed.
Accelerating Controllable Generation via Hybrid-grained Cache
Nov 14, 2025Controllable generative models have been widely used to improve the realism of synthetic visual content. However, such models must handle control conditions and content generation computational requirements, resulting in generally low generation efficiency. To address this issue, we propose a Hybrid-Grained Cache (HGC) approach that reduces computational overhead by adopting cache strategies with different granularities at different computational stages. Specifically, (1) we use a coarse-grained cache (block-level) based on feature reuse to dynamically bypass redundant computations in encoder-decoder blocks between each step of model reasoning. (2) We design a fine-grained cache (prompt-level) that acts within a module, where the fine-grained cache reuses cross-attention maps within consecutive reasoning steps and extends them to the corresponding module computations of adjacent steps. These caches of different granularities can be seamlessly integrated into each computational link of the controllable generation process. We verify the effectiveness of HGC on four benchmark datasets, especially its advantages in balancing generation efficiency and visual quality. For example, on the COCO-Stuff segmentation benchmark, our HGC significantly reduces the computational cost (MACs) by 63% (from 18.22T to 6.70T), while keeping the loss of semantic fidelity (quantized performance degradation) within 1.5%.
SeViCES: Unifying Semantic-Visual Evidence Consensus for Long Video Understanding
Oct 23, 2025Long video understanding remains challenging due to its complex, diverse, and temporally scattered content. Although video large language models (Video-LLMs) can process videos lasting tens of minutes, applying them to truly long sequences is computationally prohibitive and often leads to unfocused or inconsistent reasoning. A promising solution is to select only the most informative frames, yet existing approaches typically ignore temporal dependencies or rely on unimodal evidence, limiting their ability to provide complete and query-relevant context. We propose a Semantic-Visual Consensus Evidence Selection (SeViCES) framework for effective and reliable long video understanding. SeViCES is training-free and model-agnostic, and introduces two key components. The Semantic-Visual Consensus Frame Selection (SVCFS) module selects frames through (1) a temporal-aware semantic branch that leverages LLM reasoning over captions, and (2) a cluster-guided visual branch that aligns embeddings with semantic scores via mutual information. The Answer Consensus Refinement (ACR) module further resolves inconsistencies between semantic- and visual-based predictions by fusing evidence and constraining the answer space. Extensive experiments on long video understanding benchmarks show that SeViCES consistently outperforms state-of-the-art methods in both accuracy and robustness, demonstrating the importance of consensus-driven evidence selection for Video-LLMs.
UniSVG: A Unified Dataset for Vector Graphic Understanding and Generation with Multimodal Large Language Models
Aug 11, 2025Unlike bitmap images, scalable vector graphics (SVG) maintain quality when scaled, frequently employed in computer vision and artistic design in the representation of SVG code. In this era of proliferating AI-powered systems, enabling AI to understand and generate SVG has become increasingly urgent. However, AI-driven SVG understanding and generation (U&G) remain significant challenges. SVG code, equivalent to a set of curves and lines controlled by floating-point parameters, demands high precision in SVG U&G. Besides, SVG generation operates under diverse conditional constraints, including textual prompts and visual references, which requires powerful multi-modal processing for condition-to-SVG transformation. Recently, the rapid growth of Multi-modal Large Language Models (MLLMs) have demonstrated capabilities to process multi-modal inputs and generate complex vector controlling parameters, suggesting the potential to address SVG U&G tasks within a unified model. To unlock MLLM's capabilities in the SVG area, we propose an SVG-centric dataset called UniSVG, comprising 525k data items, tailored for MLLM training and evaluation. To our best knowledge, it is the first comprehensive dataset designed for unified SVG generation (from textual prompts and images) and SVG understanding (color, category, usage, etc.). As expected, learning on the proposed dataset boosts open-source MLLMs' performance on various SVG U&G tasks, surpassing SOTA close-source MLLMs like GPT-4V. We release dataset, benchmark, weights, codes and experiment details on https://ryanlijinke.github.io/.
SPEED: Scalable, Precise, and Efficient Concept Erasure for Diffusion Models
Mar 10, 2025Erasing concepts from large-scale text-to-image (T2I) diffusion models has become increasingly crucial due to the growing concerns over copyright infringement, offensive content, and privacy violations. However, existing methods either require costly fine-tuning or degrade image quality for non-target concepts (i.e., prior) due to inherent optimization limitations. In this paper, we introduce SPEED, a model editing-based concept erasure approach that leverages null-space constraints for scalable, precise, and efficient erasure. Specifically, SPEED incorporates Influence-based Prior Filtering (IPF) to retain the most affected non-target concepts during erasing, Directed Prior Augmentation (DPA) to expand prior coverage while maintaining semantic consistency, and Invariant Equality Constraints (IEC) to regularize model editing by explicitly preserving key invariants during the T2I generation process. Extensive evaluations across multiple concept erasure tasks demonstrate that SPEED consistently outperforms existing methods in prior preservation while achieving efficient and high-fidelity concept erasure, successfully removing 100 concepts within just 5 seconds. Our code and models are available at: https://github.com/Ouxiang-Li/SPEED.
Accelerating Diffusion Transformer via Gradient-Optimized Cache
Mar 07, 2025



Feature caching has emerged as an effective strategy to accelerate diffusion transformer (DiT) sampling through temporal feature reuse. It is a challenging problem since (1) Progressive error accumulation from cached blocks significantly degrades generation quality, particularly when over 50\% of blocks are cached; (2) Current error compensation approaches neglect dynamic perturbation patterns during the caching process, leading to suboptimal error correction. To solve these problems, we propose the Gradient-Optimized Cache (GOC) with two key innovations: (1) Cached Gradient Propagation: A gradient queue dynamically computes the gradient differences between cached and recomputed features. These gradients are weighted and propagated to subsequent steps, directly compensating for the approximation errors introduced by caching. (2) Inflection-Aware Optimization: Through statistical analysis of feature variation patterns, we identify critical inflection points where the denoising trajectory changes direction. By aligning gradient updates with these detected phases, we prevent conflicting gradient directions during error correction. Extensive evaluations on ImageNet demonstrate GOC's superior trade-off between efficiency and quality. With 50\% cached blocks, GOC achieves IS 216.28 (26.3\% higher) and FID 3.907 (43\% lower) compared to baseline DiT, while maintaining identical computational costs. These improvements persist across various cache ratios, demonstrating robust adaptability to different acceleration requirements.
Accelerating Diffusion Transformer via Error-Optimized Cache
Jan 31, 2025



Diffusion Transformer (DiT) is a crucial method for content generation. However, it needs a lot of time to sample. Many studies have attempted to use caching to reduce the time consumption of sampling. Existing caching methods accelerate generation by reusing DiT features from the previous time step and skipping calculations in the next, but they tend to locate and cache low-error modules without focusing on reducing caching-induced errors, resulting in a sharp decline in generated content quality when increasing caching intensity. To solve this problem, we propose the Error-Optimized Cache (EOC). This method introduces three key improvements: (1) Prior knowledge extraction: Extract and process the caching differences; (2) A judgment method for cache optimization: Determine whether certain caching steps need to be optimized; (3) Cache optimization: reduce caching errors. Experiments show that this algorithm significantly reduces the error accumulation caused by caching (especially over-caching). On the ImageNet dataset, without significantly increasing the computational burden, this method improves the quality of the generated images under the over-caching, rule-based, and training-based methods. Specifically, the Fr\'echet Inception Distance (FID) values are improved as follows: from 6.857 to 5.821, from 3.870 to 3.692 and form 3.539 to 3.451 respectively.
CookingDiffusion: Cooking Procedural Image Generation with Stable Diffusion
Jan 15, 2025



Recent advancements in text-to-image generation models have excelled in creating diverse and realistic images. This success extends to food imagery, where various conditional inputs like cooking styles, ingredients, and recipes are utilized. However, a yet-unexplored challenge is generating a sequence of procedural images based on cooking steps from a recipe. This could enhance the cooking experience with visual guidance and possibly lead to an intelligent cooking simulation system. To fill this gap, we introduce a novel task called \textbf{cooking procedural image generation}. This task is inherently demanding, as it strives to create photo-realistic images that align with cooking steps while preserving sequential consistency. To collectively tackle these challenges, we present \textbf{CookingDiffusion}, a novel approach that leverages Stable Diffusion and three innovative Memory Nets to model procedural prompts. These prompts encompass text prompts (representing cooking steps), image prompts (corresponding to cooking images), and multi-modal prompts (mixing cooking steps and images), ensuring the consistent generation of cooking procedural images. To validate the effectiveness of our approach, we preprocess the YouCookII dataset, establishing a new benchmark. Our experimental results demonstrate that our model excels at generating high-quality cooking procedural images with remarkable consistency across sequential cooking steps, as measured by both the FID and the proposed Average Procedure Consistency metrics. Furthermore, CookingDiffusion demonstrates the ability to manipulate ingredients and cooking methods in a recipe. We will make our code, models, and dataset publicly accessible.
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
Dec 09, 2024

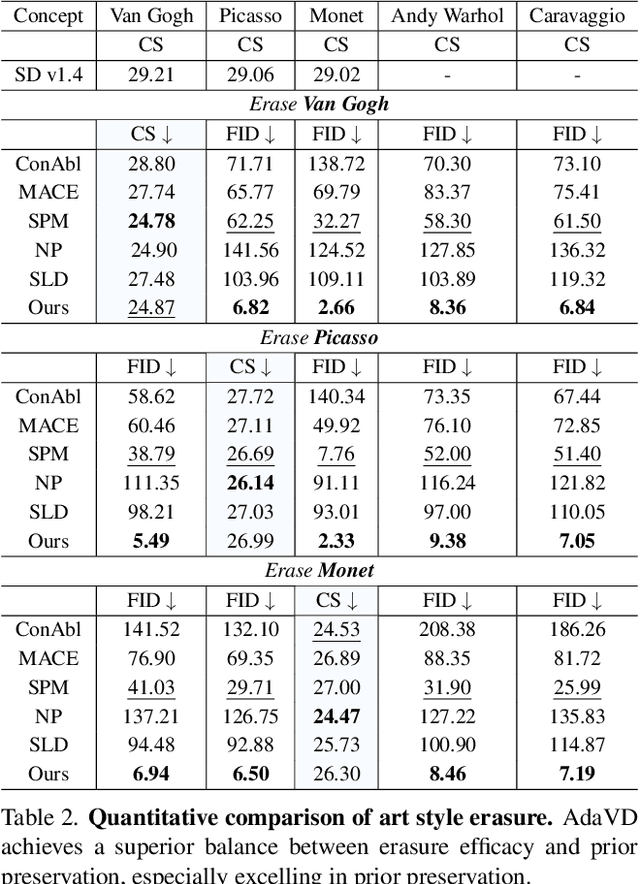

The success of text-to-image generation enabled by diffuion models has imposed an urgent need to erase unwanted concepts, e.g., copyrighted, offensive, and unsafe ones, from the pre-trained models in a precise, timely, and low-cost manner. The twofold demand of concept erasure requires a precise removal of the target concept during generation (i.e., erasure efficacy), while a minimal impact on non-target content generation (i.e., prior preservation). Existing methods are either computationally costly or face challenges in maintaining an effective balance between erasure efficacy and prior preservation. To improve, we propose a precise, fast, and low-cost concept erasure method, called Adaptive Vaule Decomposer (AdaVD), which is training-free. This method is grounded in a classical linear algebraic orthogonal complement operation, implemented in the value space of each cross-attention layer within the UNet of diffusion models. An effective shift factor is designed to adaptively navigate the erasure strength, enhancing prior preservation without sacrificing erasure efficacy. Extensive experimental results show that the proposed AdaVD is effective at both single and multiple concept erasure, showing a 2- to 10-fold improvement in prior preservation as compared to the second best, meanwhile achieving the best or near best erasure efficacy, when comparing with both training-based and training-free state of the arts. AdaVD supports a series of diffusion models and downstream image generation tasks, the code is available on the project page: https://github.com/WYuan1001/AdaVD
Enhancing Zero-Shot Vision Models by Label-Free Prompt Distribution Learning and Bias Correcting
Oct 25, 2024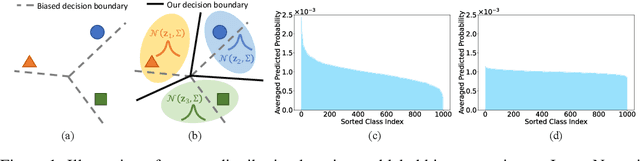

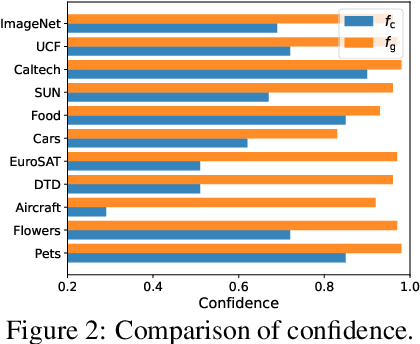

Vision-language models, such as CLIP, have shown impressive generalization capacities when using appropriate text descriptions. While optimizing prompts on downstream labeled data has proven effective in improving performance, these methods entail labor costs for annotations and are limited by their quality. Additionally, since CLIP is pre-trained on highly imbalanced Web-scale data, it suffers from inherent label bias that leads to suboptimal performance. To tackle the above challenges, we propose a label-Free prompt distribution learning and bias correction framework, dubbed as **Frolic**, which boosts zero-shot performance without the need for labeled data. Specifically, our Frolic learns distributions over prompt prototypes to capture diverse visual representations and adaptively fuses these with the original CLIP through confidence matching. This fused model is further enhanced by correcting label bias via a label-free logit adjustment. Notably, our method is not only training-free but also circumvents the necessity for hyper-parameter tuning. Extensive experimental results across 16 datasets demonstrate the efficacy of our approach, particularly outperforming the state-of-the-art by an average of $2.6\%$ on 10 datasets with CLIP ViT-B/16 and achieving an average margin of $1.5\%$ on ImageNet and its five distribution shifts with CLIP ViT-B/16. Codes are available in https://github.com/zhuhsingyuu/Frolic.