 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Vision-Language Subspace Projection for Few-shot CLIP
Paper and Code
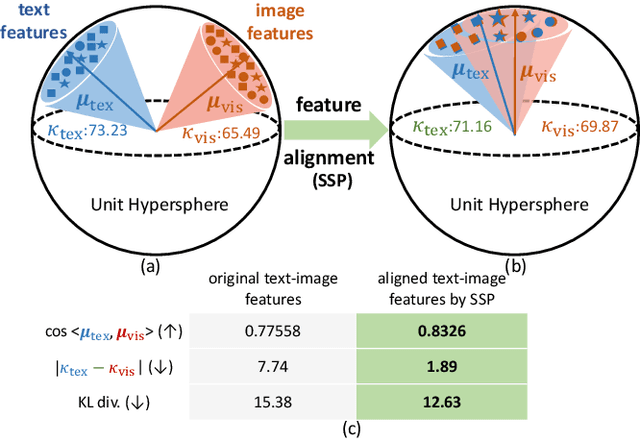
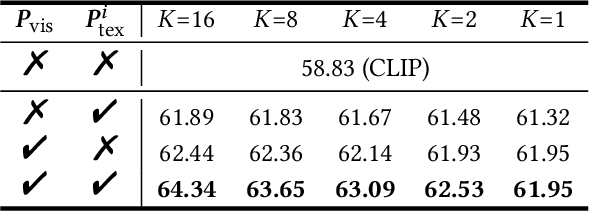

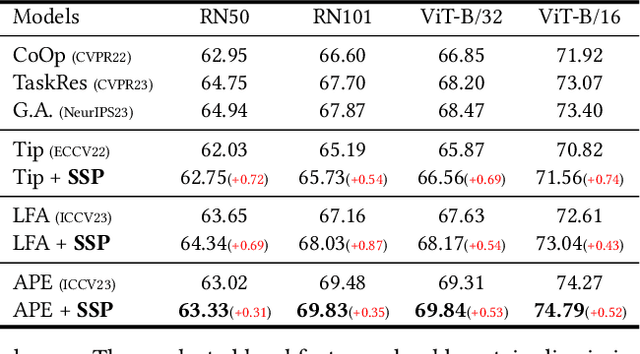
Vision-language models such as CLIP are capable of mapping the different modality data into a unified feature space, enabling zero/few-shot inference by measuring the similarity of given images and texts. However, most existing methods overlook modality gaps in CLIP's encoded features, which is shown as the text and image features lie far apart from each other, resulting in limited classification performance. To tackle this issue, we introduce a method called Selective Vision-Language Subspace Projection (SSP), which incorporates local image features and utilizes them as a bridge to enhance the alignment between image-text pairs. Specifically, our SSP framework comprises two parallel modules: a vision projector and a language projector. Both projectors utilize local image features to span the respective subspaces for image and texts, thereby projecting the image and text features into their respective subspaces to achieve alignment. Moreover, our approach entails only training-free matrix calculations and can be seamlessly integrated into advanced CLIP-based few-shot learning frameworks. Extensive experiments on 11 datasets have demonstrated SSP's superior text-image alignment capabilities, outperforming the state-of-the-art alignment methods. The code is available at https://github.com/zhuhsingyuu/SSP