 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Frames: Generative Video Distortion Evaluation via Frame Reward Model
Jan 07, 2026Recent advances in video reward models and post-training strategies have improved text-to-video (T2V) generation. While these models typically assess visual quality, motion quality, and text alignment, they often overlook key structural distortions, such as abnormal object appearances and interactions, which can degrade the overall quality of the generative video. To address this gap, we introduce REACT, a frame-level reward model designed specifically for structural distortions evaluation in generative videos. REACT assigns point-wise scores and attribution labels by reasoning over video frames, focusing on recognizing distortions. To support this, we construct a large-scale human preference dataset, annotated based on our proposed taxonomy of structural distortions, and generate additional data using a efficient Chain-of-Thought (CoT) synthesis pipeline. REACT is trained with a two-stage framework: ((1) supervised fine-tuning with masked loss for domain knowledge injection, followed by (2) reinforcement learning with Group Relative Policy Optimization (GRPO) and pairwise rewards to enhance reasoning capability and align output scores with human preferences. During inference, a dynamic sampling mechanism is introduced to focus on frames most likely to exhibit distortion. We also present REACT-Bench, a benchmark for generative video distortion evaluation. Experimental results demonstrate that REACT complements existing reward models in assessing structutal distortion, achieving both accurate quantitative evaluations and interpretable attribution analysis.
Understanding Chain-of-Thought in Large Language Models via Topological Data Analysis
Dec 22, 2025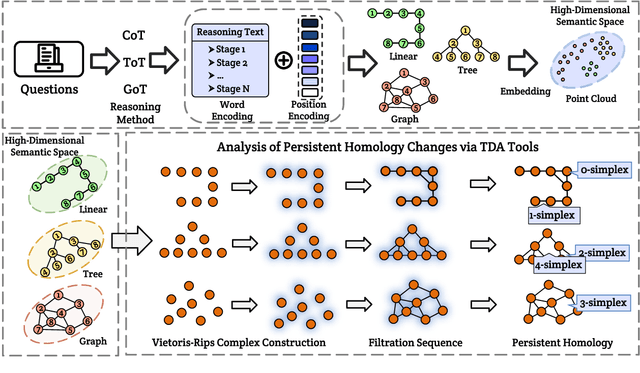
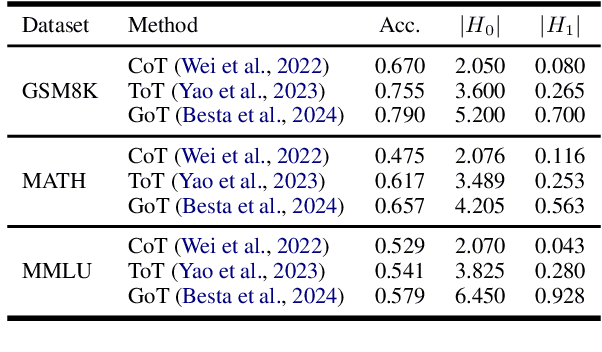
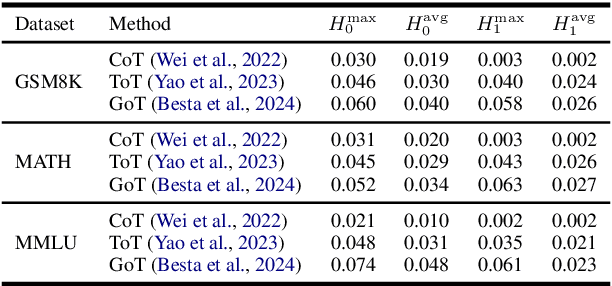
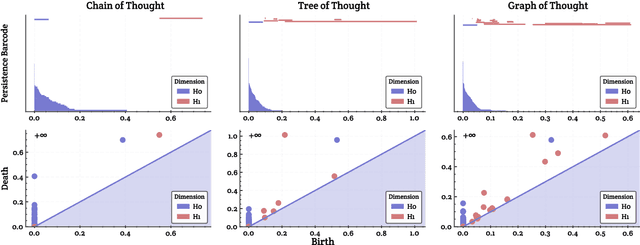
With the development of large language models (LLMs), particularly with the introduction of the long reasoning chain technique, the reasoning ability of LLMs in complex problem-solving has been significantly enhanced. While acknowledging the power of long reasoning chains, we cannot help but wonder: Why do different reasoning chains perform differently in reasoning? What components of the reasoning chains play a key role? Existing studies mainly focus on evaluating reasoning chains from a functional perspective, with little attention paid to their structural mechanisms. To address this gap, this work is the first to analyze and evaluate the quality of the reasoning chain from a structural perspective. We apply persistent homology from Topological Data Analysis (TDA) to map reasoning steps into semantic space, extract topological features, and analyze structural changes. These changes reveal semantic coherence, logical redundancy, and identify logical breaks and gaps. By calculating homology groups, we assess connectivity and redundancy at various scales, using barcode and persistence diagrams to quantify stability and consistency. Our results show that the topological structural complexity of reasoning chains correlates positively with accuracy. More complex chains identify correct answers sooner, while successful reasoning exhibits simpler topologies, reducing redundancy and cycles, enhancing efficiency and interpretability. This work provides a new perspective on reasoning chain quality assessment and offers guidance for future optimization.
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
Dec 09, 2024

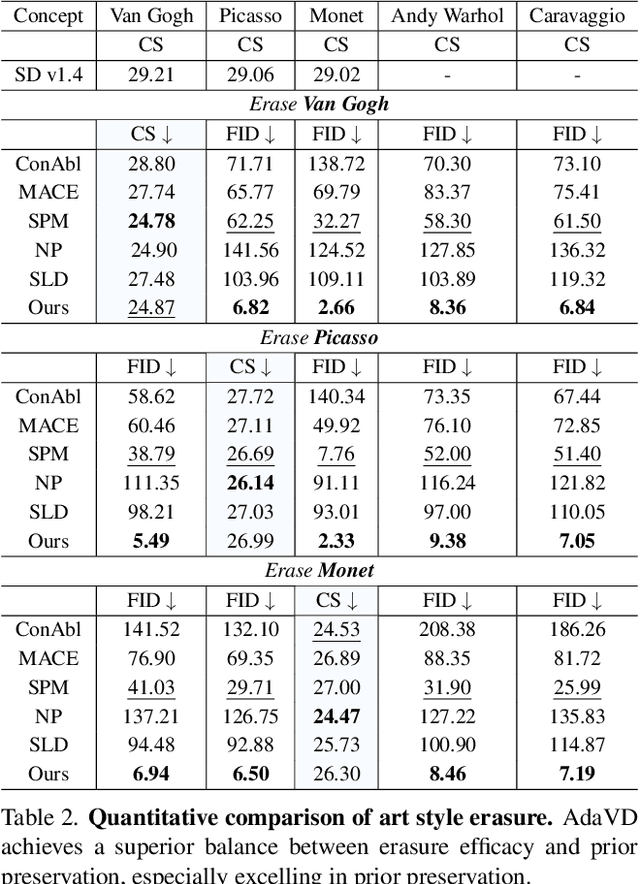

The success of text-to-image generation enabled by diffuion models has imposed an urgent need to erase unwanted concepts, e.g., copyrighted, offensive, and unsafe ones, from the pre-trained models in a precise, timely, and low-cost manner. The twofold demand of concept erasure requires a precise removal of the target concept during generation (i.e., erasure efficacy), while a minimal impact on non-target content generation (i.e., prior preservation). Existing methods are either computationally costly or face challenges in maintaining an effective balance between erasure efficacy and prior preservation. To improve, we propose a precise, fast, and low-cost concept erasure method, called Adaptive Vaule Decomposer (AdaVD), which is training-free. This method is grounded in a classical linear algebraic orthogonal complement operation, implemented in the value space of each cross-attention layer within the UNet of diffusion models. An effective shift factor is designed to adaptively navigate the erasure strength, enhancing prior preservation without sacrificing erasure efficacy. Extensive experimental results show that the proposed AdaVD is effective at both single and multiple concept erasure, showing a 2- to 10-fold improvement in prior preservation as compared to the second best, meanwhile achieving the best or near best erasure efficacy, when comparing with both training-based and training-free state of the arts. AdaVD supports a series of diffusion models and downstream image generation tasks, the code is available on the project page: https://github.com/WYuan1001/AdaVD
Densely Distilling Cumulative Knowledge for Continual Learning
May 16, 2024



Continual learning, involving sequential training on diverse tasks, often faces catastrophic forgetting. While knowledge distillation-based approaches exhibit notable success in preventing forgetting, we pinpoint a limitation in their ability to distill the cumulative knowledge of all the previous tasks. To remedy this, we propose Dense Knowledge Distillation (DKD). DKD uses a task pool to track the model's capabilities. It partitions the output logits of the model into dense groups, each corresponding to a task in the task pool. It then distills all tasks' knowledge using all groups. However, using all the groups can be computationally expensive, we also suggest random group selection in each optimization step. Moreover, we propose an adaptive weighting scheme, which balances the learning of new classes and the retention of old classes, based on the count and similarity of the classes. Our DKD outperforms recent state-of-the-art baselines across diverse benchmarks and scenarios. Empirical analysis underscores DKD's ability to enhance model stability, promote flatter minima for improved generalization, and remains robust across various memory budgets and task orders. Moreover, it seamlessly integrates with other CL methods to boost performance and proves versatile in offline scenarios like model compression.