 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Frames: Generative Video Distortion Evaluation via Frame Reward Model
Jan 07, 2026Recent advances in video reward models and post-training strategies have improved text-to-video (T2V) generation. While these models typically assess visual quality, motion quality, and text alignment, they often overlook key structural distortions, such as abnormal object appearances and interactions, which can degrade the overall quality of the generative video. To address this gap, we introduce REACT, a frame-level reward model designed specifically for structural distortions evaluation in generative videos. REACT assigns point-wise scores and attribution labels by reasoning over video frames, focusing on recognizing distortions. To support this, we construct a large-scale human preference dataset, annotated based on our proposed taxonomy of structural distortions, and generate additional data using a efficient Chain-of-Thought (CoT) synthesis pipeline. REACT is trained with a two-stage framework: ((1) supervised fine-tuning with masked loss for domain knowledge injection, followed by (2) reinforcement learning with Group Relative Policy Optimization (GRPO) and pairwise rewards to enhance reasoning capability and align output scores with human preferences. During inference, a dynamic sampling mechanism is introduced to focus on frames most likely to exhibit distortion. We also present REACT-Bench, a benchmark for generative video distortion evaluation. Experimental results demonstrate that REACT complements existing reward models in assessing structutal distortion, achieving both accurate quantitative evaluations and interpretable attribution analysis.
RL-MTJail: Reinforcement Learning for Automated Black-Box Multi-Turn Jailbreaking of Large Language Models
Dec 08, 2025Large language models are vulnerable to jailbreak attacks, threatening their safe deployment in real-world applications. This paper studies black-box multi-turn jailbreaks, aiming to train attacker LLMs to elicit harmful content from black-box models through a sequence of prompt-output interactions. Existing approaches typically rely on single turn optimization, which is insufficient for learning long-term attack strategies. To bridge this gap, we formulate the problem as a multi-turn reinforcement learning task, directly optimizing the harmfulness of the final-turn output as the outcome reward. To mitigate sparse supervision and promote long-term attack strategies, we propose two heuristic process rewards: (1) controlling the harmfulness of intermediate outputs to prevent triggering the black-box model's rejection mechanisms, and (2) maintaining the semantic relevance of intermediate outputs to avoid drifting into irrelevant content. Experimental results on multiple benchmarks show consistently improved attack success rates across multiple models, highlighting the effectiveness of our approach. The code is available at https://github.com/xxiqiao/RL-MTJail. Warning: This paper contains examples of harmful content.
Easier Painting Than Thinking: Can Text-to-Image Models Set the Stage, but Not Direct the Play?
Sep 03, 2025Text-to-image (T2I) generation aims to synthesize images from textual prompts, which jointly specify what must be shown and imply what can be inferred, thereby corresponding to two core capabilities: composition and reasoning. However, with the emerging advances of T2I models in reasoning beyond composition, existing benchmarks reveal clear limitations in providing comprehensive evaluations across and within these capabilities. Meanwhile, these advances also enable models to handle more complex prompts, whereas current benchmarks remain limited to low scene density and simplified one-to-one reasoning. To address these limitations, we propose T2I-CoReBench, a comprehensive and complex benchmark that evaluates both composition and reasoning capabilities of T2I models. To ensure comprehensiveness, we structure composition around scene graph elements (instance, attribute, and relation) and reasoning around the philosophical framework of inference (deductive, inductive, and abductive), formulating a 12-dimensional evaluation taxonomy. To increase complexity, driven by the inherent complexities of real-world scenarios, we curate each prompt with high compositional density for composition and multi-step inference for reasoning. We also pair each prompt with a checklist that specifies individual yes/no questions to assess each intended element independently to facilitate fine-grained and reliable evaluation. In statistics, our benchmark comprises 1,080 challenging prompts and around 13,500 checklist questions. Experiments across 27 current T2I models reveal that their composition capability still remains limited in complex high-density scenarios, while the reasoning capability lags even further behind as a critical bottleneck, with all models struggling to infer implicit elements from prompts. Our project page: https://t2i-corebench.github.io/.
SPEED: Scalable, Precise, and Efficient Concept Erasure for Diffusion Models
Mar 10, 2025Erasing concepts from large-scale text-to-image (T2I) diffusion models has become increasingly crucial due to the growing concerns over copyright infringement, offensive content, and privacy violations. However, existing methods either require costly fine-tuning or degrade image quality for non-target concepts (i.e., prior) due to inherent optimization limitations. In this paper, we introduce SPEED, a model editing-based concept erasure approach that leverages null-space constraints for scalable, precise, and efficient erasure. Specifically, SPEED incorporates Influence-based Prior Filtering (IPF) to retain the most affected non-target concepts during erasing, Directed Prior Augmentation (DPA) to expand prior coverage while maintaining semantic consistency, and Invariant Equality Constraints (IEC) to regularize model editing by explicitly preserving key invariants during the T2I generation process. Extensive evaluations across multiple concept erasure tasks demonstrate that SPEED consistently outperforms existing methods in prior preservation while achieving efficient and high-fidelity concept erasure, successfully removing 100 concepts within just 5 seconds. Our code and models are available at: https://github.com/Ouxiang-Li/SPEED.
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
Dec 09, 2024

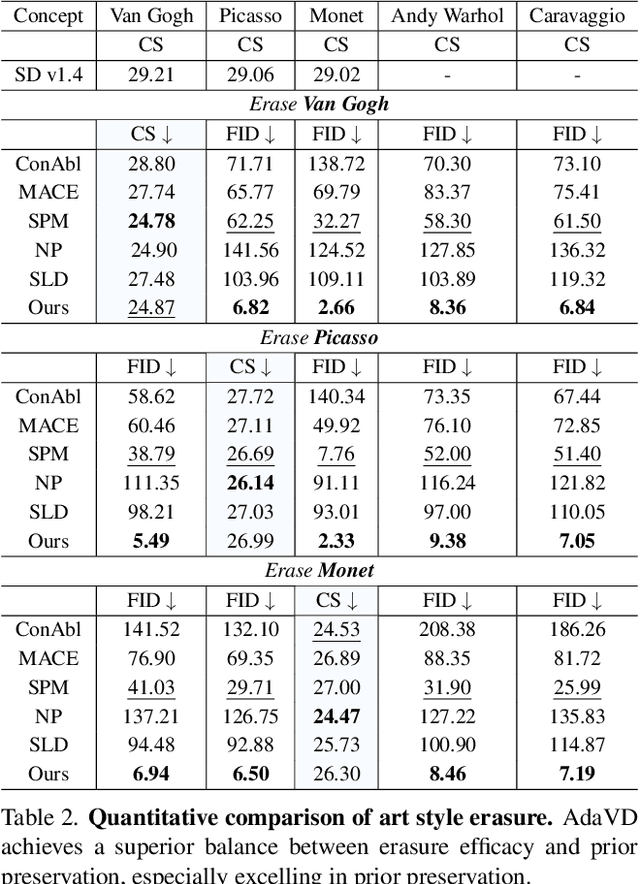

The success of text-to-image generation enabled by diffuion models has imposed an urgent need to erase unwanted concepts, e.g., copyrighted, offensive, and unsafe ones, from the pre-trained models in a precise, timely, and low-cost manner. The twofold demand of concept erasure requires a precise removal of the target concept during generation (i.e., erasure efficacy), while a minimal impact on non-target content generation (i.e., prior preservation). Existing methods are either computationally costly or face challenges in maintaining an effective balance between erasure efficacy and prior preservation. To improve, we propose a precise, fast, and low-cost concept erasure method, called Adaptive Vaule Decomposer (AdaVD), which is training-free. This method is grounded in a classical linear algebraic orthogonal complement operation, implemented in the value space of each cross-attention layer within the UNet of diffusion models. An effective shift factor is designed to adaptively navigate the erasure strength, enhancing prior preservation without sacrificing erasure efficacy. Extensive experimental results show that the proposed AdaVD is effective at both single and multiple concept erasure, showing a 2- to 10-fold improvement in prior preservation as compared to the second best, meanwhile achieving the best or near best erasure efficacy, when comparing with both training-based and training-free state of the arts. AdaVD supports a series of diffusion models and downstream image generation tasks, the code is available on the project page: https://github.com/WYuan1001/AdaVD
Improving Synthetic Image Detection Towards Generalization: An Image Transformation Perspective
Aug 13, 2024



With recent generative models facilitating photo-realistic image synthesis, the proliferation of synthetic images has also engendered certain negative impacts on social platforms, thereby raising an urgent imperative to develop effective detectors. Current synthetic image detection (SID) pipelines are primarily dedicated to crafting universal artifact features, accompanied by an oversight about SID training paradigm. In this paper, we re-examine the SID problem and identify two prevalent biases in current training paradigms, i.e., weakened artifact features and overfitted artifact features. Meanwhile, we discover that the imaging mechanism of synthetic images contributes to heightened local correlations among pixels, suggesting that detectors should be equipped with local awareness. In this light, we propose SAFE, a lightweight and effective detector with three simple image transformations. Firstly, for weakened artifact features, we substitute the down-sampling operator with the crop operator in image pre-processing to help circumvent artifact distortion. Secondly, for overfitted artifact features, we include ColorJitter and RandomRotation as additional data augmentations, to help alleviate irrelevant biases from color discrepancies and semantic differences in limited training samples. Thirdly, for local awareness, we propose a patch-based random masking strategy tailored for SID, forcing the detector to focus on local regions at training. Comparative experiments are conducted on an open-world dataset, comprising synthetic images generated by 26 distinct generative models. Our pipeline achieves a new state-of-the-art performance, with remarkable improvements of 4.5% in accuracy and 2.9% in average precision against existing methods.
Model Inversion Attacks Through Target-Specific Conditional Diffusion Models
Jul 16, 2024Model inversion attacks (MIAs) aim to reconstruct private images from a target classifier's training set, thereby raising privacy concerns in AI applications. Previous GAN-based MIAs tend to suffer from inferior generative fidelity due to GAN's inherent flaws and biased optimization within latent space. To alleviate these issues, leveraging on diffusion models' remarkable synthesis capabilities, we propose Diffusion-based Model Inversion (Diff-MI) attacks. Specifically, we introduce a novel target-specific conditional diffusion model (CDM) to purposely approximate target classifier's private distribution and achieve superior accuracy-fidelity balance. Our method involves a two-step learning paradigm. Step-1 incorporates the target classifier into the entire CDM learning under a pretrain-then-finetune fashion, with creating pseudo-labels as model conditions in pretraining and adjusting specified layers with image predictions in fine-tuning. Step-2 presents an iterative image reconstruction method, further enhancing the attack performance through a combination of diffusion priors and target knowledge. Additionally, we propose an improved max-margin loss that replaces the hard max with top-k maxes, fully leveraging feature information and soft labels from the target classifier. Extensive experiments demonstrate that Diff-MI significantly improves generative fidelity with an average decrease of 20% in FID while maintaining competitive attack accuracy compared to state-of-the-art methods across various datasets and models. We will release our code and models.
A Sanity Check for AI-generated Image Detection
Jun 27, 2024


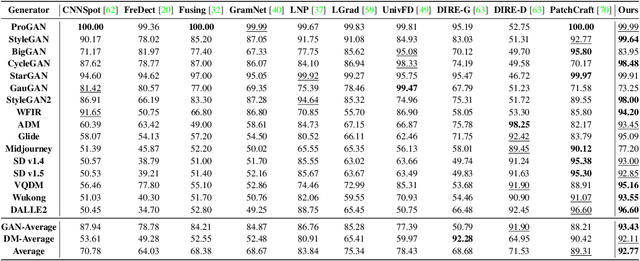
With the rapid development of generative models, discerning AI-generated content has evoked increasing attention from both industry and academia. In this paper, we conduct a sanity check on "whether the task of AI-generated image detection has been solved". To start with, we present Chameleon dataset, consisting AIgenerated images that are genuinely challenging for human perception. To quantify the generalization of existing methods, we evaluate 9 off-the-shelf AI-generated image detectors on Chameleon dataset. Upon analysis, almost all models classify AI-generated images as real ones. Later, we propose AIDE (AI-generated Image DEtector with Hybrid Features), which leverages multiple experts to simultaneously extract visual artifacts and noise patterns. Specifically, to capture the high-level semantics, we utilize CLIP to compute the visual embedding. This effectively enables the model to discern AI-generated images based on semantics or contextual information; Secondly, we select the highest frequency patches and the lowest frequency patches in the image, and compute the low-level patchwise features, aiming to detect AI-generated images by low-level artifacts, for example, noise pattern, anti-aliasing, etc. While evaluating on existing benchmarks, for example, AIGCDetectBenchmark and GenImage, AIDE achieves +3.5% and +4.6% improvements to state-of-the-art methods, and on our proposed challenging Chameleon benchmarks, it also achieves the promising results, despite this problem for detecting AI-generated images is far from being solved. The dataset, codes, and pre-train models will be published at https://github.com/shilinyan99/AIDE.
Bi-directional Distribution Alignment for Transductive Zero-Shot Learning
Mar 19, 2023


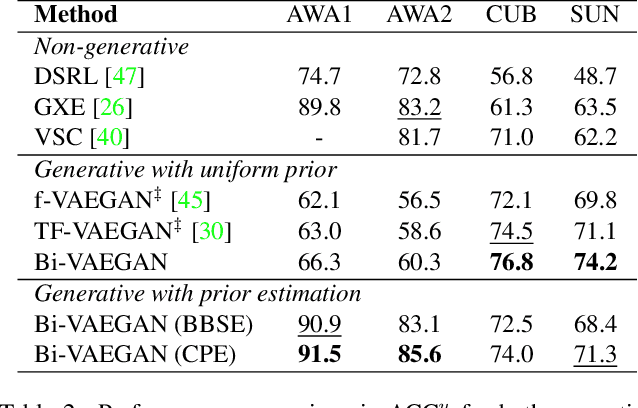
It is well-known that zero-shot learning (ZSL) can suffer severely from the problem of domain shift, where the true and learned data distributions for the unseen classes do not match. Although transductive ZSL (TZSL) attempts to improve this by allowing the use of unlabelled examples from the unseen classes, there is still a high level of distribution shift. We propose a novel TZSL model (named as Bi-VAEGAN), which largely improves the shift by a strengthened distribution alignment between the visual and auxiliary spaces. The key proposal of the model design includes (1) a bi-directional distribution alignment, (2) a simple but effective L_2-norm based feature normalization approach, and (3) a more sophisticated unseen class prior estimation approach. In benchmark evaluation using four datasets, Bi-VAEGAN achieves the new state of the arts under both the standard and generalized TZSL settings. Code could be found at https://github.com/Zhicaiwww/Bi-VAEGAN