 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Weak-to-strong Generalization
Oct 09, 2025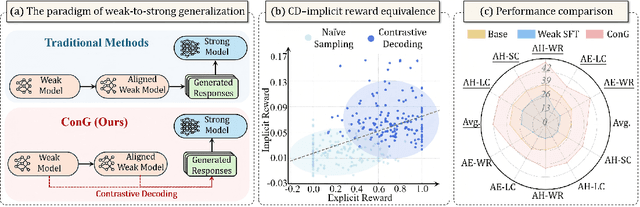
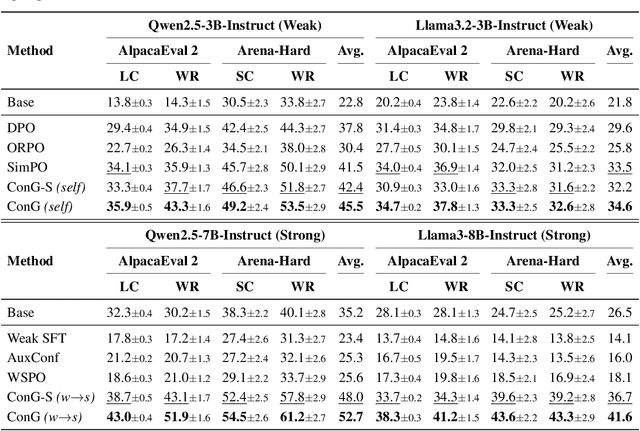
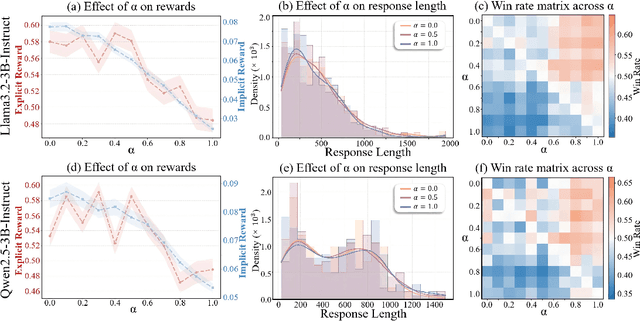
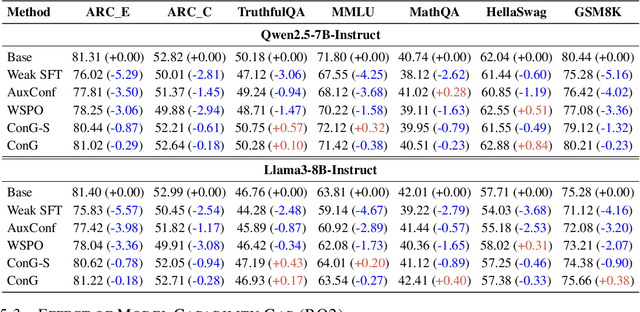
Weak-to-strong generalization provides a promising paradigm for scaling large language models (LLMs) by training stronger models on samples from aligned weaker ones, without requiring human feedback or explicit reward modeling. However, its robustness and generalization are hindered by the noise and biases in weak-model outputs, which limit its applicability in practice. To address this challenge, we leverage implicit rewards, which approximate explicit rewards through log-likelihood ratios, and reveal their structural equivalence with Contrastive Decoding (CD), a decoding strategy shown to reduce noise in LLM generation. Building on this connection, we propose Contrastive Weak-to-Strong Generalization (ConG), a framework that employs contrastive decoding between pre- and post-alignment weak models to generate higher-quality samples. This approach enables more reliable capability transfer, denoising, and improved robustness, substantially mitigating the limitations of traditional weak-to-strong methods. Empirical results across different model families confirm consistent improvements, demonstrating the generality and effectiveness of ConG. Taken together, our findings highlight the potential of ConG to advance weak-to-strong generalization and provide a promising pathway toward AGI.
RaCalNet: Radar Calibration Network for Sparse-Supervised Metric Depth Estimation
Jun 18, 2025Dense metric depth estimation using millimeter-wave radar typically requires dense LiDAR supervision, generated via multi-frame projection and interpolation, to guide the learning of accurate depth from sparse radar measurements and RGB images. However, this paradigm is both costly and data-intensive. To address this, we propose RaCalNet, a novel framework that eliminates the need for dense supervision by using sparse LiDAR to supervise the learning of refined radar measurements, resulting in a supervision density of merely around 1% compared to dense-supervised methods. Unlike previous approaches that associate radar points with broad image regions and rely heavily on dense labels, RaCalNet first recalibrates and refines sparse radar points to construct accurate depth priors. These priors then serve as reliable anchors to guide monocular depth prediction, enabling metric-scale estimation without resorting to dense supervision. This design improves structural consistency and preserves fine details. Despite relying solely on sparse supervision, RaCalNet surpasses state-of-the-art dense-supervised methods, producing depth maps with clear object contours and fine-grained textures. Extensive experiments on the ZJU-4DRadarCam dataset and real-world deployment scenarios demonstrate its effectiveness, reducing RMSE by 35.30% and 34.89%, respectively.
Mitigating Safety Fallback in Editing-based Backdoor Injection on LLMs
Jun 16, 2025



Large language models (LLMs) have shown strong performance across natural language tasks, but remain vulnerable to backdoor attacks. Recent model editing-based approaches enable efficient backdoor injection by directly modifying parameters to map specific triggers to attacker-desired responses. However, these methods often suffer from safety fallback, where the model initially responds affirmatively but later reverts to refusals due to safety alignment. In this work, we propose DualEdit, a dual-objective model editing framework that jointly promotes affirmative outputs and suppresses refusal responses. To address two key challenges -- balancing the trade-off between affirmative promotion and refusal suppression, and handling the diversity of refusal expressions -- DualEdit introduces two complementary techniques. (1) Dynamic loss weighting calibrates the objective scale based on the pre-edited model to stabilize optimization. (2) Refusal value anchoring compresses the suppression target space by clustering representative refusal value vectors, reducing optimization conflict from overly diverse token sets. Experiments on safety-aligned LLMs show that DualEdit improves attack success by 9.98\% and reduces safety fallback rate by 10.88\% over baselines.
SPEED: Scalable, Precise, and Efficient Concept Erasure for Diffusion Models
Mar 10, 2025Erasing concepts from large-scale text-to-image (T2I) diffusion models has become increasingly crucial due to the growing concerns over copyright infringement, offensive content, and privacy violations. However, existing methods either require costly fine-tuning or degrade image quality for non-target concepts (i.e., prior) due to inherent optimization limitations. In this paper, we introduce SPEED, a model editing-based concept erasure approach that leverages null-space constraints for scalable, precise, and efficient erasure. Specifically, SPEED incorporates Influence-based Prior Filtering (IPF) to retain the most affected non-target concepts during erasing, Directed Prior Augmentation (DPA) to expand prior coverage while maintaining semantic consistency, and Invariant Equality Constraints (IEC) to regularize model editing by explicitly preserving key invariants during the T2I generation process. Extensive evaluations across multiple concept erasure tasks demonstrate that SPEED consistently outperforms existing methods in prior preservation while achieving efficient and high-fidelity concept erasure, successfully removing 100 concepts within just 5 seconds. Our code and models are available at: https://github.com/Ouxiang-Li/SPEED.
Reinforced Lifelong Editing for Language Models
Feb 09, 2025Large language models (LLMs) acquire information from pre-training corpora, but their stored knowledge can become inaccurate or outdated over time. Model editing addresses this challenge by modifying model parameters without retraining, and prevalent approaches leverage hypernetworks to generate these parameter updates. However, they face significant challenges in lifelong editing due to their incompatibility with LLM parameters that dynamically change during the editing process. To address this, we observed that hypernetwork-based lifelong editing aligns with reinforcement learning modeling and proposed RLEdit, an RL-based editing method. By treating editing losses as rewards and optimizing hypernetwork parameters at the full knowledge sequence level, we enable it to precisely capture LLM changes and generate appropriate parameter updates. Our extensive empirical evaluation across several LLMs demonstrates that RLEdit outperforms existing methods in lifelong editing with superior effectiveness and efficiency, achieving a 59.24% improvement while requiring only 2.11% of the time compared to most approaches. Our code is available at: https://github.com/zhrli324/RLEdit.
AnyEdit: Edit Any Knowledge Encoded in Language Models
Feb 08, 2025



Large language models (LLMs) often produce incorrect or outdated information, necessitating efficient and precise knowledge updates. Current model editing methods, however, struggle with long-form knowledge in diverse formats, such as poetry, code snippets, and mathematical derivations. These limitations arise from their reliance on editing a single token's hidden state, a limitation we term "efficacy barrier". To solve this, we propose AnyEdit, a new autoregressive editing paradigm. It decomposes long-form knowledge into sequential chunks and iteratively edits the key token in each chunk, ensuring consistent and accurate outputs. Theoretically, we ground AnyEdit in the Chain Rule of Mutual Information, showing its ability to update any knowledge within LLMs. Empirically, it outperforms strong baselines by 21.5% on benchmarks including UnKEBench, AKEW, and our new EditEverything dataset for long-form diverse-formatted knowledge. Additionally, AnyEdit serves as a plug-and-play framework, enabling current editing methods to update knowledge with arbitrary length and format, significantly advancing the scope and practicality of LLM knowledge editing.
Accelerating Diffusion Transformer via Error-Optimized Cache
Jan 31, 2025



Diffusion Transformer (DiT) is a crucial method for content generation. However, it needs a lot of time to sample. Many studies have attempted to use caching to reduce the time consumption of sampling. Existing caching methods accelerate generation by reusing DiT features from the previous time step and skipping calculations in the next, but they tend to locate and cache low-error modules without focusing on reducing caching-induced errors, resulting in a sharp decline in generated content quality when increasing caching intensity. To solve this problem, we propose the Error-Optimized Cache (EOC). This method introduces three key improvements: (1) Prior knowledge extraction: Extract and process the caching differences; (2) A judgment method for cache optimization: Determine whether certain caching steps need to be optimized; (3) Cache optimization: reduce caching errors. Experiments show that this algorithm significantly reduces the error accumulation caused by caching (especially over-caching). On the ImageNet dataset, without significantly increasing the computational burden, this method improves the quality of the generated images under the over-caching, rule-based, and training-based methods. Specifically, the Fr\'echet Inception Distance (FID) values are improved as follows: from 6.857 to 5.821, from 3.870 to 3.692 and form 3.539 to 3.451 respectively.
Neuron-Level Sequential Editing for Large Language Models
Oct 05, 2024



This work explores sequential model editing in large language models (LLMs), a critical task that involves modifying internal knowledge within LLMs continuously through multi-round editing, each incorporating updates or corrections to adjust the model outputs without the need for costly retraining. Existing model editing methods, especially those that alter model parameters, typically focus on single-round editing and often face significant challenges in sequential model editing-most notably issues of model forgetting and failure. To address these challenges, we introduce a new model editing method, namely \textbf{N}euron-level \textbf{S}equential \textbf{E}diting (NSE), tailored for supporting sequential model editing. Specifically, we optimize the target layer's hidden states using the model's original weights to prevent model failure. Furthermore, we iteratively select neurons in multiple layers for editing based on their activation values to mitigate model forgetting. Our empirical experiments demonstrate that NSE significantly outperforms current modifying parameters model editing methods, marking a substantial advancement in the field of sequential model editing. Our code is released on \url{https://github.com/jianghoucheng/NSE}.
AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models
Oct 03, 2024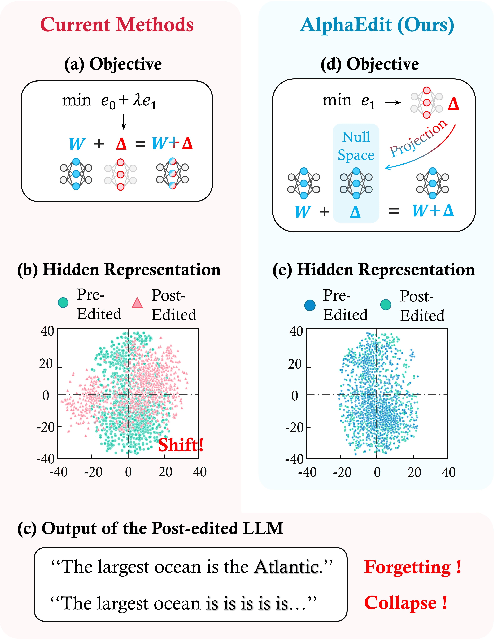



Large language models (LLMs) often exhibit hallucinations due to incorrect or outdated knowledge. Hence, model editing methods have emerged to enable targeted knowledge updates. To achieve this, a prevailing paradigm is the locating-then-editing approach, which first locates influential parameters and then edits them by introducing a perturbation. While effective, current studies have demonstrated that this perturbation inevitably disrupt the originally preserved knowledge within LLMs, especially in sequential editing scenarios. To address this, we introduce AlphaEdit, a novel solution that projects perturbation onto the null space of the preserved knowledge before applying it to the parameters. We theoretically prove that this projection ensures the output of post-edited LLMs remains unchanged when queried about the preserved knowledge, thereby mitigating the issue of disruption. Extensive experiments on various LLMs, including LLaMA3, GPT2-XL, and GPT-J, show that AlphaEdit boosts the performance of most locating-then-editing methods by an average of 36.4% with a single line of additional code for projection solely. Our code is available at: https://github.com/jianghoucheng/AlphaEdit.