 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTPL-VIO: Robust Visual-Inertial Odometry with Optimal Transport Line Association and Adaptive Uncertainty
Mar 10, 2026Robust stereo visual-inertial odometry (VIO) remains challenging in low-texture scenes and under abrupt illumination changes, where point features become sparse and unstable, leading to ambiguous association and under-constrained estimation. Line structures offer complementary geometric cues, yet many efficient point-line systems still rely on point-guided line association, which can break down when point support is weak and may lead to biased constraints. We present a stereo point-line VIO system in which line segments are equipped with dedicated deep descriptors and matched using an entropy-regularized optimal transport formulation, enabling globally consistent correspondences under ambiguity, outliers, and partial observations. The proposed descriptor is training-free and is computed by sampling and pooling network feature maps. To improve estimation stability, we analyze the impact of line measurement noise and introduce reliability-adaptive weighting to regulate the influence of line constraints during optimization. Experiments on EuRoC and UMA-VI, together with real-world deployments in low-texture and illumination-challenging environments, demonstrate improved accuracy and robustness over representative baselines while maintaining real-time performance.
U-OBCA: Uncertainty-Aware Optimization-Based Collision Avoidance via Wasserstein Distributionally Robust Chance Constraints
Mar 05, 2026Uncertainties arising from localization error, trajectory prediction errors of the moving obstacles and environmental disturbances pose significant challenges to robot's safe navigation. Existing uncertainty-aware planners often approximate polygon-shaped robots and obstacles using simple geometric primitives such as circles or ellipses. Though computationally convenient, these approximations substantially shrink the feasible space, leading to overly conservative trajectories and even planning failure in narrow environments. In addition, many such methods rely on specific assumptions about noise distributions, which may not hold in practice and thus limit their performance guarantees. To address these limitations, we extend the Optimization-Based Collision Avoidance (OBCA) framework to an uncertainty-aware formulation, termed \emph{U-OBCA}. The proposed method explicitly accounts for the collision risk between polygon-shaped robots and obstacles by formulating OBCA-based chance constraints, and hence avoiding geometric simplifications and reducing unnecessary conservatism. These probabilistic constraints are further tightened into deterministic nonlinear constraints under mild distributional assumptions, which can be solved efficiently by standard numerical optimization solvers. The proposed approach is validated through theoretical analysis, numerical simulations and real-world experiments. The results demonstrate that U-OBCA significantly mitigates the conservatism in trajectory planning and achieves higher navigation efficiency compared to existing baseline methods, particularly in narrow and cluttered environments.
Graph-Loc: Robust Graph-Based LiDAR Pose Tracking with Compact Structural Map Priors under Low Observability and Occlusion
Feb 09, 2026Map-based LiDAR pose tracking is essential for long-term autonomous operation, where onboard map priors need be compact for scalable storage and fast retrieval, while online observations are often partial, repetitive, and heavily occluded. We propose Graph-Loc, a graph-based localization framework that tracks the platform pose against compact structural map priors represented as a lightweight point-line graph. Such priors can be constructed from heterogeneous sources commonly available in practice, including polygon outlines vectorized from occupancy/grid maps and CAD/model/floor-plan layouts. For each incoming LiDAR scan, Graph-Loc extracts sparse point and line primitives to form an observation graph, retrieves a pose-conditioned visible subgraph via LiDAR ray simulation, and performs scan-to-map association through unbalanced optimal transport with a local graph-context regularizer. The unbalanced formulation relaxes mass conservation, improving robustness to missing, spurious, and fragmented structures under occlusion. To enhance stability in low-observability segments, we estimate information anisotropy from the refinement normal matrix and defer updates along weakly constrained directions until sufficient constraints reappear. Experiments on public benchmarks, controlled stress tests, and real-world deployments demonstrate accurate and stable tracking with KB-level priors from heterogeneous map sources, including under geometrically degenerate and sustained occlusion and in the presence of gradual scene changes.
Guided Diffusion-based Generation of Adversarial Objects for Real-World Monocular Depth Estimation Attacks
Dec 30, 2025Monocular Depth Estimation (MDE) serves as a core perception module in autonomous driving systems, but it remains highly susceptible to adversarial attacks. Errors in depth estimation may propagate through downstream decision making and influence overall traffic safety. Existing physical attacks primarily rely on texture-based patches, which impose strict placement constraints and exhibit limited realism, thereby reducing their effectiveness in complex driving environments. To overcome these limitations, this work introduces a training-free generative adversarial attack framework that generates naturalistic, scene-consistent adversarial objects via a diffusion-based conditional generation process. The framework incorporates a Salient Region Selection module that identifies regions most influential to MDE and a Jacobian Vector Product Guidance mechanism that steers adversarial gradients toward update directions supported by the pre-trained diffusion model. This formulation enables the generation of physically plausible adversarial objects capable of inducing substantial adversarial depth shifts. Extensive digital and physical experiments demonstrate that our method significantly outperforms existing attacks in effectiveness, stealthiness, and physical deployability, underscoring its strong practical implications for autonomous driving safety assessment.
RaCalNet: Radar Calibration Network for Sparse-Supervised Metric Depth Estimation
Jun 18, 2025Dense metric depth estimation using millimeter-wave radar typically requires dense LiDAR supervision, generated via multi-frame projection and interpolation, to guide the learning of accurate depth from sparse radar measurements and RGB images. However, this paradigm is both costly and data-intensive. To address this, we propose RaCalNet, a novel framework that eliminates the need for dense supervision by using sparse LiDAR to supervise the learning of refined radar measurements, resulting in a supervision density of merely around 1% compared to dense-supervised methods. Unlike previous approaches that associate radar points with broad image regions and rely heavily on dense labels, RaCalNet first recalibrates and refines sparse radar points to construct accurate depth priors. These priors then serve as reliable anchors to guide monocular depth prediction, enabling metric-scale estimation without resorting to dense supervision. This design improves structural consistency and preserves fine details. Despite relying solely on sparse supervision, RaCalNet surpasses state-of-the-art dense-supervised methods, producing depth maps with clear object contours and fine-grained textures. Extensive experiments on the ZJU-4DRadarCam dataset and real-world deployment scenarios demonstrate its effectiveness, reducing RMSE by 35.30% and 34.89%, respectively.
UNO: Unified Self-Supervised Monocular Odometry for Platform-Agnostic Deployment
Jun 08, 2025This work presents UNO, a unified monocular visual odometry framework that enables robust and adaptable pose estimation across diverse environments, platforms, and motion patterns. Unlike traditional methods that rely on deployment-specific tuning or predefined motion priors, our approach generalizes effectively across a wide range of real-world scenarios, including autonomous vehicles, aerial drones, mobile robots, and handheld devices. To this end, we introduce a Mixture-of-Experts strategy for local state estimation, with several specialized decoders that each handle a distinct class of ego-motion patterns. Moreover, we introduce a fully differentiable Gumbel-Softmax module that constructs a robust inter-frame correlation graph, selects the optimal expert decoder, and prunes erroneous estimates. These cues are then fed into a unified back-end that combines pre-trained, scale-independent depth priors with a lightweight bundling adjustment to enforce geometric consistency. We extensively evaluate our method on three major benchmark datasets: KITTI (outdoor/autonomous driving), EuRoC-MAV (indoor/aerial drones), and TUM-RGBD (indoor/handheld), demonstrating state-of-the-art performance.
SN-LiDAR: Semantic Neural Fields for Novel Space-time View LiDAR Synthesis
Apr 11, 2025Recent research has begun exploring novel view synthesis (NVS) for LiDAR point clouds, aiming to generate realistic LiDAR scans from unseen viewpoints. However, most existing approaches do not reconstruct semantic labels, which are crucial for many downstream applications such as autonomous driving and robotic perception. Unlike images, which benefit from powerful segmentation models, LiDAR point clouds lack such large-scale pre-trained models, making semantic annotation time-consuming and labor-intensive. To address this challenge, we propose SN-LiDAR, a method that jointly performs accurate semantic segmentation, high-quality geometric reconstruction, and realistic LiDAR synthesis. Specifically, we employ a coarse-to-fine planar-grid feature representation to extract global features from multi-frame point clouds and leverage a CNN-based encoder to extract local semantic features from the current frame point cloud. Extensive experiments on SemanticKITTI and KITTI-360 demonstrate the superiority of SN-LiDAR in both semantic and geometric reconstruction, effectively handling dynamic objects and large-scale scenes. Codes will be available on https://github.com/dtc111111/SN-Lidar.
SALT: A Flexible Semi-Automatic Labeling Tool for General LiDAR Point Clouds with Cross-Scene Adaptability and 4D Consistency
Mar 31, 2025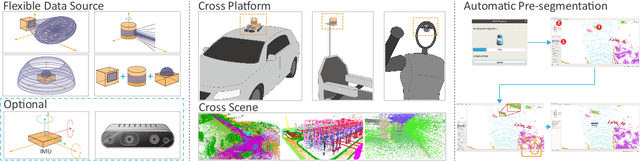
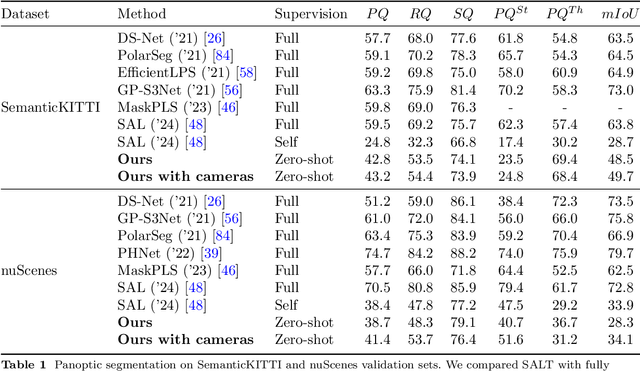
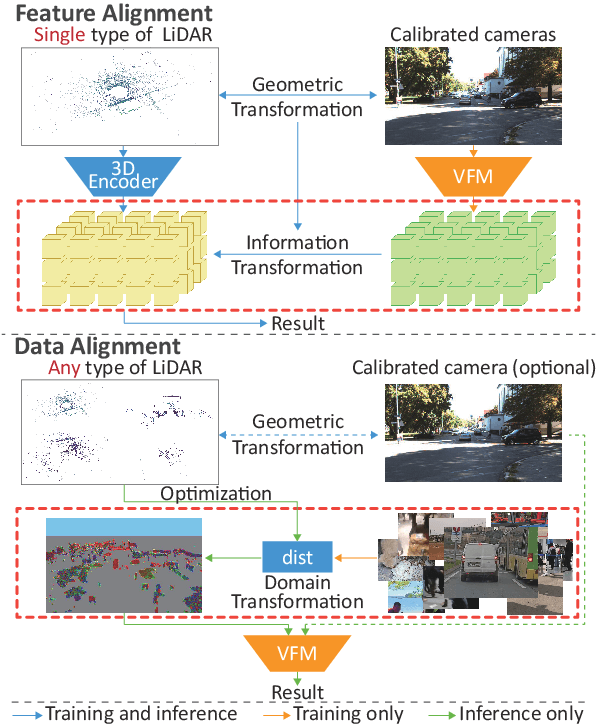
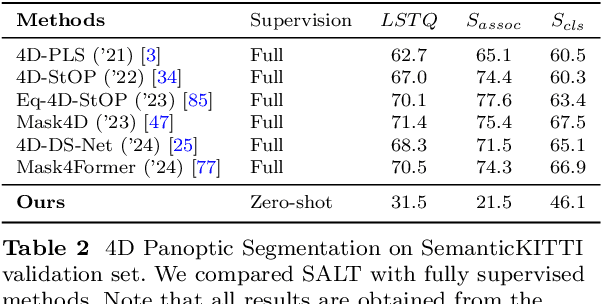
We propose a flexible Semi-Automatic Labeling Tool (SALT) for general LiDAR point clouds with cross-scene adaptability and 4D consistency. Unlike recent approaches that rely on camera distillation, SALT operates directly on raw LiDAR data, automatically generating pre-segmentation results. To achieve this, we propose a novel zero-shot learning paradigm, termed data alignment, which transforms LiDAR data into pseudo-images by aligning with the training distribution of vision foundation models. Additionally, we design a 4D-consistent prompting strategy and 4D non-maximum suppression module to enhance SAM2, ensuring high-quality, temporally consistent presegmentation. SALT surpasses the latest zero-shot methods by 18.4% PQ on SemanticKITTI and achieves nearly 40-50% of human annotator performance on our newly collected low-resolution LiDAR data and on combined data from three LiDAR types, significantly boosting annotation efficiency. We anticipate that SALT's open-sourcing will catalyze substantial expansion of current LiDAR datasets and lay the groundwork for the future development of LiDAR foundation models. Code is available at https://github.com/Cavendish518/SALT.
SFPNet: Sparse Focal Point Network for Semantic Segmentation on General LiDAR Point Clouds
Jul 16, 2024



Although LiDAR semantic segmentation advances rapidly, state-of-the-art methods often incorporate specifically designed inductive bias derived from benchmarks originating from mechanical spinning LiDAR. This can limit model generalizability to other kinds of LiDAR technologies and make hyperparameter tuning more complex. To tackle these issues, we propose a generalized framework to accommodate various types of LiDAR prevalent in the market by replacing window-attention with our sparse focal point modulation. Our SFPNet is capable of extracting multi-level contexts and dynamically aggregating them using a gate mechanism. By implementing a channel-wise information query, features that incorporate both local and global contexts are encoded. We also introduce a novel large-scale hybrid-solid LiDAR semantic segmentation dataset for robotic applications. SFPNet demonstrates competitive performance on conventional benchmarks derived from mechanical spinning LiDAR, while achieving state-of-the-art results on benchmark derived from solid-state LiDAR. Additionally, it outperforms existing methods on our novel dataset sourced from hybrid-solid LiDAR. Code and dataset are available at https://github.com/Cavendish518/SFPNet and https://www.semanticindustry.top.
Incremental Joint Learning of Depth, Pose and Implicit Scene Representation on Monocular Camera in Large-scale Scenes
Apr 09, 2024Dense scene reconstruction for photo-realistic view synthesis has various applications, such as VR/AR, autonomous vehicles. However, most existing methods have difficulties in large-scale scenes due to three core challenges: \textit{(a) inaccurate depth input.} Accurate depth input is impossible to get in real-world large-scale scenes. \textit{(b) inaccurate pose estimation.} Most existing approaches rely on accurate pre-estimated camera poses. \textit{(c) insufficient scene representation capability.} A single global radiance field lacks the capacity to effectively scale to large-scale scenes. To this end, we propose an incremental joint learning framework, which can achieve accurate depth, pose estimation, and large-scale scene reconstruction. A vision transformer-based network is adopted as the backbone to enhance performance in scale information estimation. For pose estimation, a feature-metric bundle adjustment (FBA) method is designed for accurate and robust camera tracking in large-scale scenes. In terms of implicit scene representation, we propose an incremental scene representation method to construct the entire large-scale scene as multiple local radiance fields to enhance the scalability of 3D scene representation. Extended experiments have been conducted to demonstrate the effectiveness and accuracy of our method in depth estimation, pose estimation, and large-scale scene reconstruction.