 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Diffusion-based Generation of Adversarial Objects for Real-World Monocular Depth Estimation Attacks
Dec 30, 2025Monocular Depth Estimation (MDE) serves as a core perception module in autonomous driving systems, but it remains highly susceptible to adversarial attacks. Errors in depth estimation may propagate through downstream decision making and influence overall traffic safety. Existing physical attacks primarily rely on texture-based patches, which impose strict placement constraints and exhibit limited realism, thereby reducing their effectiveness in complex driving environments. To overcome these limitations, this work introduces a training-free generative adversarial attack framework that generates naturalistic, scene-consistent adversarial objects via a diffusion-based conditional generation process. The framework incorporates a Salient Region Selection module that identifies regions most influential to MDE and a Jacobian Vector Product Guidance mechanism that steers adversarial gradients toward update directions supported by the pre-trained diffusion model. This formulation enables the generation of physically plausible adversarial objects capable of inducing substantial adversarial depth shifts. Extensive digital and physical experiments demonstrate that our method significantly outperforms existing attacks in effectiveness, stealthiness, and physical deployability, underscoring its strong practical implications for autonomous driving safety assessment.
SALT: A Flexible Semi-Automatic Labeling Tool for General LiDAR Point Clouds with Cross-Scene Adaptability and 4D Consistency
Mar 31, 2025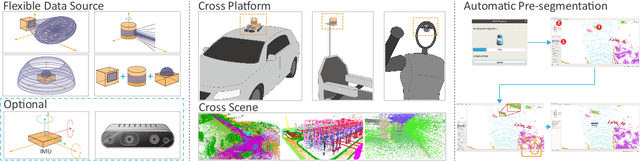
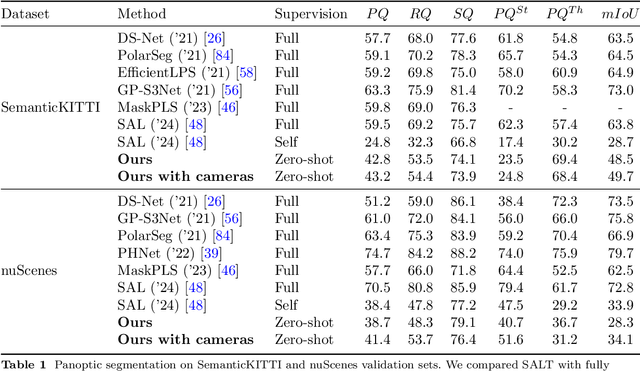
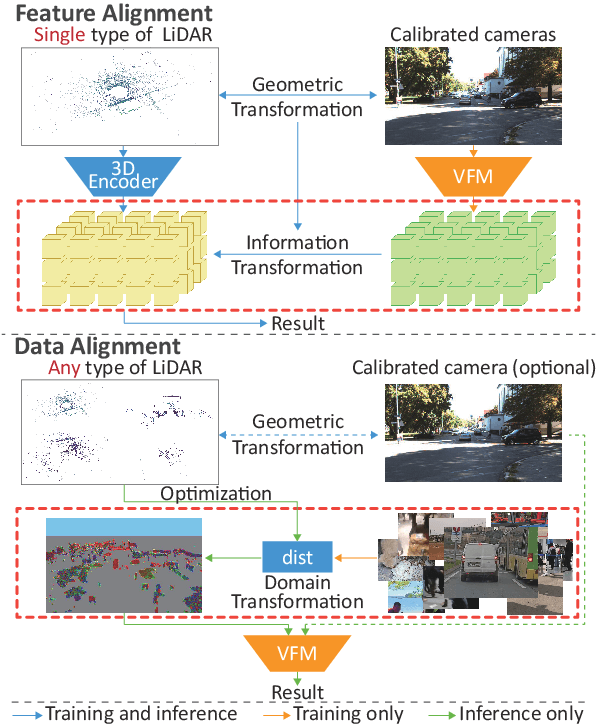
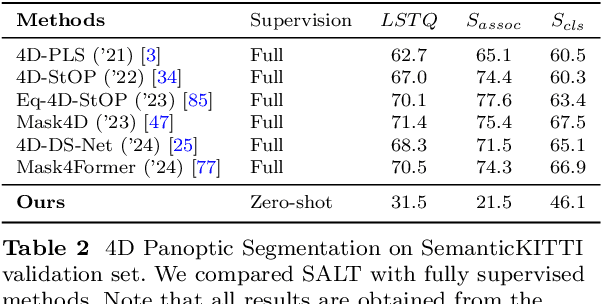
We propose a flexible Semi-Automatic Labeling Tool (SALT) for general LiDAR point clouds with cross-scene adaptability and 4D consistency. Unlike recent approaches that rely on camera distillation, SALT operates directly on raw LiDAR data, automatically generating pre-segmentation results. To achieve this, we propose a novel zero-shot learning paradigm, termed data alignment, which transforms LiDAR data into pseudo-images by aligning with the training distribution of vision foundation models. Additionally, we design a 4D-consistent prompting strategy and 4D non-maximum suppression module to enhance SAM2, ensuring high-quality, temporally consistent presegmentation. SALT surpasses the latest zero-shot methods by 18.4% PQ on SemanticKITTI and achieves nearly 40-50% of human annotator performance on our newly collected low-resolution LiDAR data and on combined data from three LiDAR types, significantly boosting annotation efficiency. We anticipate that SALT's open-sourcing will catalyze substantial expansion of current LiDAR datasets and lay the groundwork for the future development of LiDAR foundation models. Code is available at https://github.com/Cavendish518/SALT.