 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoVerse: A MLLMs-Driven Emotion Representation Dataset for Interpretable Visual Emotion Analysis
Nov 16, 2025
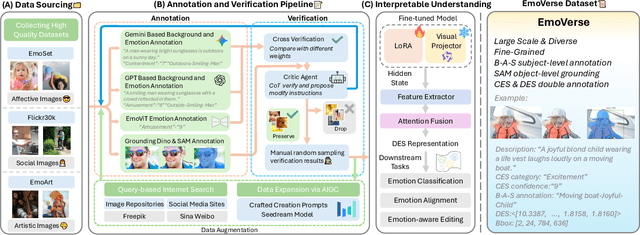
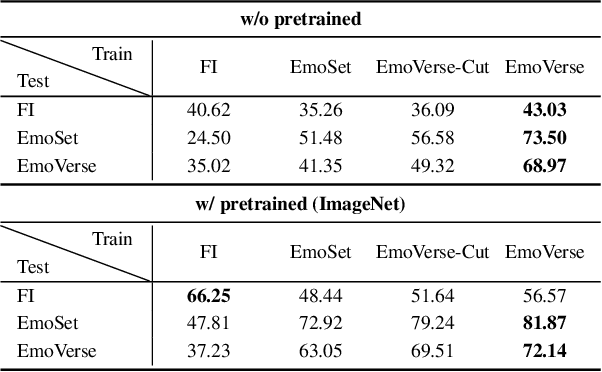
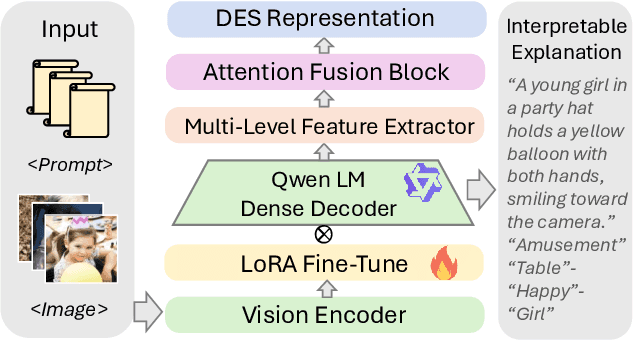
Visual Emotion Analysis (VEA) aims to bridge the affective gap between visual content and human emotional responses. Despite its promise, progress in this field remains limited by the lack of open-source and interpretable datasets. Most existing studies assign a single discrete emotion label to an entire image, offering limited insight into how visual elements contribute to emotion. In this work, we introduce EmoVerse, a large-scale open-source dataset that enables interpretable visual emotion analysis through multi-layered, knowledge-graph-inspired annotations. By decomposing emotions into Background-Attribute-Subject (B-A-S) triplets and grounding each element to visual regions, EmoVerse provides word-level and subject-level emotional reasoning. With over 219k images, the dataset further includes dual annotations in Categorical Emotion States (CES) and Dimensional Emotion Space (DES), facilitating unified discrete and continuous emotion representation. A novel multi-stage pipeline ensures high annotation reliability with minimal human effort. Finally, we introduce an interpretable model that maps visual cues into DES representations and provides detailed attribution explanations. Together, the dataset, pipeline, and model form a comprehensive foundation for advancing explainable high-level emotion understanding.
Scene-Agnostic Traversability Labeling and Estimation via a Multimodal Self-supervised Framework
Aug 25, 2025Traversability estimation is critical for enabling robots to navigate across diverse terrains and environments. While recent self-supervised learning methods achieve promising results, they often fail to capture the characteristics of non-traversable regions. Moreover, most prior works concentrate on a single modality, overlooking the complementary strengths offered by integrating heterogeneous sensory modalities for more robust traversability estimation. To address these limitations, we propose a multimodal self-supervised framework for traversability labeling and estimation. First, our annotation pipeline integrates footprint, LiDAR, and camera data as prompts for a vision foundation model, generating traversability labels that account for both semantic and geometric cues. Then, leveraging these labels, we train a dual-stream network that jointly learns from different modalities in a decoupled manner, enhancing its capacity to recognize diverse traversability patterns. In addition, we incorporate sparse LiDAR-based supervision to mitigate the noise introduced by pseudo labels. Finally, extensive experiments conducted across urban, off-road, and campus environments demonstrate the effectiveness of our approach. The proposed automatic labeling method consistently achieves around 88% IoU across diverse datasets. Compared to existing self-supervised state-of-the-art methods, our multimodal traversability estimation network yields consistently higher IoU, improving by 1.6-3.5% on all evaluated datasets.
VPGS-SLAM: Voxel-based Progressive 3D Gaussian SLAM in Large-Scale Scenes
May 25, 2025



3D Gaussian Splatting has recently shown promising results in dense visual SLAM. However, existing 3DGS-based SLAM methods are all constrained to small-room scenarios and struggle with memory explosion in large-scale scenes and long sequences. To this end, we propose VPGS-SLAM, the first 3DGS-based large-scale RGBD SLAM framework for both indoor and outdoor scenarios. We design a novel voxel-based progressive 3D Gaussian mapping method with multiple submaps for compact and accurate scene representation in large-scale and long-sequence scenes. This allows us to scale up to arbitrary scenes and improves robustness (even under pose drifts). In addition, we propose a 2D-3D fusion camera tracking method to achieve robust and accurate camera tracking in both indoor and outdoor large-scale scenes. Furthermore, we design a 2D-3D Gaussian loop closure method to eliminate pose drift. We further propose a submap fusion method with online distillation to achieve global consistency in large-scale scenes when detecting a loop. Experiments on various indoor and outdoor datasets demonstrate the superiority and generalizability of the proposed framework. The code will be open source on https://github.com/dtc111111/vpgs-slam.
Lightweight LiDAR-Camera 3D Dynamic Object Detection and Multi-Class Trajectory Prediction
Apr 18, 2025Service mobile robots are often required to avoid dynamic objects while performing their tasks, but they usually have only limited computational resources. So we present a lightweight multi-modal framework for 3D object detection and trajectory prediction. Our system synergistically integrates LiDAR and camera inputs to achieve real-time perception of pedestrians, vehicles, and riders in 3D space. The framework proposes two novel modules: 1) a Cross-Modal Deformable Transformer (CMDT) for object detection with high accuracy and acceptable amount of computation, and 2) a Reference Trajectory-based Multi-Class Transformer (RTMCT) for efficient and diverse trajectory prediction of mult-class objects with flexible trajectory lengths. Evaluations on the CODa benchmark demonstrate superior performance over existing methods across detection (+2.03% in mAP) and trajectory prediction (-0.408m in minADE5 of pedestrians) metrics. Remarkably, the system exhibits exceptional deployability - when implemented on a wheelchair robot with an entry-level NVIDIA 3060 GPU, it achieves real-time inference at 13.2 fps. To facilitate reproducibility and practical deployment, we release the related code of the method at https://github.com/TossherO/3D_Perception and its ROS inference version at https://github.com/TossherO/ros_packages.
Towards Efficient Partially Relevant Video Retrieval with Active Moment Discovering
Apr 15, 2025



Partially relevant video retrieval (PRVR) is a practical yet challenging task in text-to-video retrieval, where videos are untrimmed and contain much background content. The pursuit here is of both effective and efficient solutions to capture the partial correspondence between text queries and untrimmed videos. Existing PRVR methods, which typically focus on modeling multi-scale clip representations, however, suffer from content independence and information redundancy, impairing retrieval performance. To overcome these limitations, we propose a simple yet effective approach with active moment discovering (AMDNet). We are committed to discovering video moments that are semantically consistent with their queries. By using learnable span anchors to capture distinct moments and applying masked multi-moment attention to emphasize salient moments while suppressing redundant backgrounds, we achieve more compact and informative video representations. To further enhance moment modeling, we introduce a moment diversity loss to encourage different moments of distinct regions and a moment relevance loss to promote semantically query-relevant moments, which cooperate with a partially relevant retrieval loss for end-to-end optimization. Extensive experiments on two large-scale video datasets (\ie, TVR and ActivityNet Captions) demonstrate the superiority and efficiency of our AMDNet. In particular, AMDNet is about 15.5 times smaller (\#parameters) while 6.0 points higher (SumR) than the up-to-date method GMMFormer on TVR.
HistLLM: A Unified Framework for LLM-Based Multimodal Recommendation with User History Encoding and Compression
Apr 14, 2025While large language models (LLMs) have proven effective in leveraging textual data for recommendations, their application to multimodal recommendation tasks remains relatively underexplored. Although LLMs can process multimodal information through projection functions that map visual features into their semantic space, recommendation tasks often require representing users' history interactions through lengthy prompts combining text and visual elements, which not only hampers training and inference efficiency but also makes it difficult for the model to accurately capture user preferences from complex and extended prompts, leading to reduced recommendation performance. To address this challenge, we introduce HistLLM, an innovative multimodal recommendation framework that integrates textual and visual features through a User History Encoding Module (UHEM), compressing multimodal user history interactions into a single token representation, effectively facilitating LLMs in processing user preferences. Extensive experiments demonstrate the effectiveness and efficiency of our proposed mechanism.
SN-LiDAR: Semantic Neural Fields for Novel Space-time View LiDAR Synthesis
Apr 11, 2025Recent research has begun exploring novel view synthesis (NVS) for LiDAR point clouds, aiming to generate realistic LiDAR scans from unseen viewpoints. However, most existing approaches do not reconstruct semantic labels, which are crucial for many downstream applications such as autonomous driving and robotic perception. Unlike images, which benefit from powerful segmentation models, LiDAR point clouds lack such large-scale pre-trained models, making semantic annotation time-consuming and labor-intensive. To address this challenge, we propose SN-LiDAR, a method that jointly performs accurate semantic segmentation, high-quality geometric reconstruction, and realistic LiDAR synthesis. Specifically, we employ a coarse-to-fine planar-grid feature representation to extract global features from multi-frame point clouds and leverage a CNN-based encoder to extract local semantic features from the current frame point cloud. Extensive experiments on SemanticKITTI and KITTI-360 demonstrate the superiority of SN-LiDAR in both semantic and geometric reconstruction, effectively handling dynamic objects and large-scale scenes. Codes will be available on https://github.com/dtc111111/SN-Lidar.
SALT: A Flexible Semi-Automatic Labeling Tool for General LiDAR Point Clouds with Cross-Scene Adaptability and 4D Consistency
Mar 31, 2025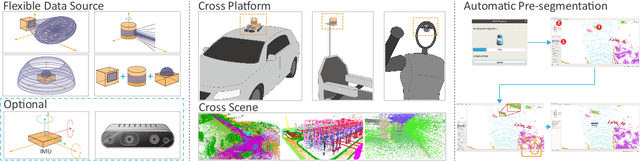
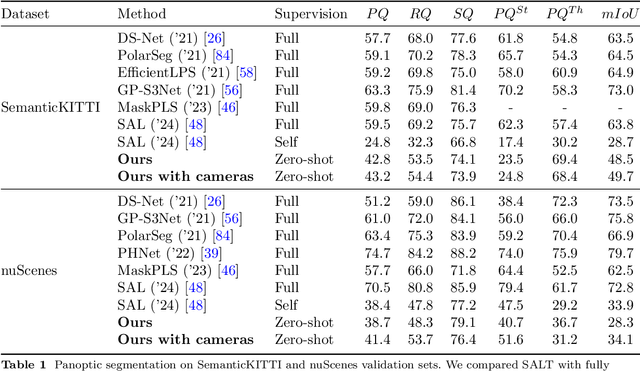
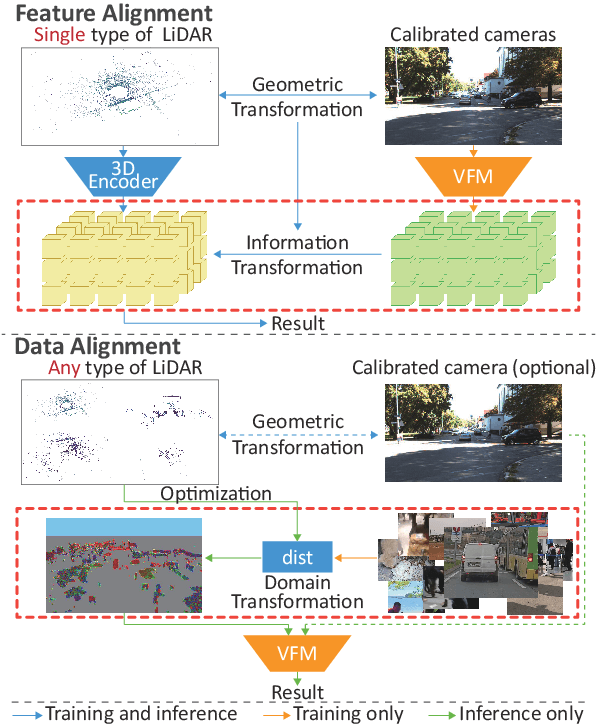
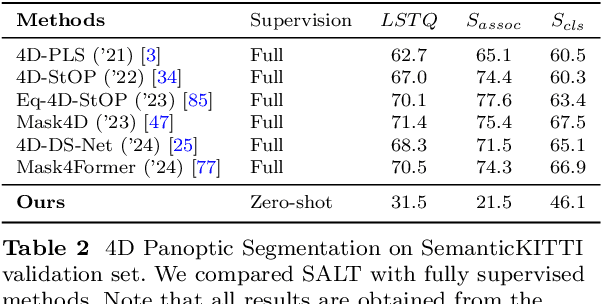
We propose a flexible Semi-Automatic Labeling Tool (SALT) for general LiDAR point clouds with cross-scene adaptability and 4D consistency. Unlike recent approaches that rely on camera distillation, SALT operates directly on raw LiDAR data, automatically generating pre-segmentation results. To achieve this, we propose a novel zero-shot learning paradigm, termed data alignment, which transforms LiDAR data into pseudo-images by aligning with the training distribution of vision foundation models. Additionally, we design a 4D-consistent prompting strategy and 4D non-maximum suppression module to enhance SAM2, ensuring high-quality, temporally consistent presegmentation. SALT surpasses the latest zero-shot methods by 18.4% PQ on SemanticKITTI and achieves nearly 40-50% of human annotator performance on our newly collected low-resolution LiDAR data and on combined data from three LiDAR types, significantly boosting annotation efficiency. We anticipate that SALT's open-sourcing will catalyze substantial expansion of current LiDAR datasets and lay the groundwork for the future development of LiDAR foundation models. Code is available at https://github.com/Cavendish518/SALT.
DrawSpeech: Expressive Speech Synthesis Using Prosodic Sketches as Control Conditions
Jan 08, 2025



Controlling text-to-speech (TTS) systems to synthesize speech with the prosodic characteristics expected by users has attracted much attention. To achieve controllability, current studies focus on two main directions: (1) using reference speech as prosody prompt to guide speech synthesis, and (2) using natural language descriptions to control the generation process. However, finding reference speech that exactly contains the prosody that users want to synthesize takes a lot of effort. Description-based guidance in TTS systems can only determine the overall prosody, which has difficulty in achieving fine-grained prosody control over the synthesized speech. In this paper, we propose DrawSpeech, a sketch-conditioned diffusion model capable of generating speech based on any prosody sketches drawn by users. Specifically, the prosody sketches are fed to DrawSpeech to provide a rough indication of the expected prosody trends. DrawSpeech then recovers the detailed pitch and energy contours based on the coarse sketches and synthesizes the desired speech. Experimental results show that DrawSpeech can generate speech with a wide variety of prosody and can precisely control the fine-grained prosody in a user-friendly manner. Our implementation and audio samples are publicly available.
Graph Mixture of Experts and Memory-augmented Routers for Multivariate Time Series Anomaly Detection
Dec 26, 2024Multivariate time series (MTS) anomaly detection is a critical task that involves identifying abnormal patterns or events in data that consist of multiple interrelated time series. In order to better model the complex interdependence between entities and the various inherent characteristics of each entity, the GNN based methods are widely adopted by existing methods. In each layer of GNN, node features aggregate information from their neighboring nodes to update their information. In doing so, from shallow layer to deep layer in GNN, original individual node features continue to be weakened and more structural information,i.e., from short-distance neighborhood to long-distance neighborhood, continues to be enhanced. However, research to date has largely ignored the understanding of how hierarchical graph information is represented and their characteristics that can benefit anomaly detection. Existing methods simply leverage the output from the last layer of GNN for anomaly estimation while neglecting the essential information contained in the intermediate GNN layers. To address such limitations, in this paper, we propose a Graph Mixture of Experts (Graph-MoE) network for multivariate time series anomaly detection, which incorporates the mixture of experts (MoE) module to adaptively represent and integrate hierarchical multi-layer graph information into entity representations. It is worth noting that our Graph-MoE can be integrated into any GNN-based MTS anomaly detection method in a plug-and-play manner. In addition, the memory-augmented routers are proposed in this paper to capture the correlation temporal information in terms of the global historical features of MTS to adaptively weigh the obtained entity representations to achieve successful anomaly estimation. Extensive experiments on five challenging datasets prove the superiority of our approach and each proposed module.