 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces
Feb 03, 2026Frontier language models have demonstrated strong reasoning and long-horizon tool-use capabilities. However, existing RAG systems fail to leverage these capabilities. They still rely on two paradigms: (1) designing an algorithm that retrieves passages in a single shot and concatenates them into the model's input, or (2) predefining a workflow and prompting the model to execute it step-by-step. Neither paradigm allows the model to participate in retrieval decisions, preventing efficient scaling with model improvements. In this paper, we introduce A-RAG, an Agentic RAG framework that exposes hierarchical retrieval interfaces directly to the model. A-RAG provides three retrieval tools: keyword search, semantic search, and chunk read, enabling the agent to adaptively search and retrieve information across multiple granularities. Experiments on multiple open-domain QA benchmarks show that A-RAG consistently outperforms existing approaches with comparable or lower retrieved tokens, demonstrating that A-RAG effectively leverages model capabilities and dynamically adapts to different RAG tasks. We further systematically study how A-RAG scales with model size and test-time compute. We will release our code and evaluation suite to facilitate future research. Code and evaluation suite are available at https://github.com/Ayanami0730/arag.
Wiki Live Challenge: Challenging Deep Research Agents with Expert-Level Wikipedia Articles
Feb 03, 2026Deep Research Agents (DRAs) have demonstrated remarkable capabilities in autonomous information retrieval and report generation, showing great potential to assist humans in complex research tasks. Current evaluation frameworks primarily rely on LLM-generated references or LLM-derived evaluation dimensions. While these approaches offer scalability, they often lack the reliability of expert-verified content and struggle to provide objective, fine-grained assessments of critical dimensions. To bridge this gap, we introduce Wiki Live Challenge (WLC), a live benchmark that leverages the newest Wikipedia Good Articles (GAs) as expert-level references. Wikipedia's strict standards for neutrality, comprehensiveness, and verifiability serve as a great challenge for DRAs, with GAs representing the pinnacle of which. We curate a dataset of 100 recent Good Articles and propose Wiki Eval, a comprehensive evaluation framework comprising a fine-grained evaluation method with 39 criteria for writing quality and rigorous metrics for factual verifiability. Extensive experiments on various DRA systems demonstrate a significant gap between current DRAs and human expert-level Wikipedia articles, validating the effectiveness of WLC in advancing agent research. We release our benchmark at https://github.com/WangShao2000/Wiki_Live_Challenge
WildGraphBench: Benchmarking GraphRAG with Wild-Source Corpora
Feb 03, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) organizes external knowledge as a hierarchical graph, enabling efficient retrieval and aggregation of scattered evidence across multiple documents. However, many existing benchmarks for GraphRAG rely on short, curated passages as external knowledge, failing to adequately evaluate systems in realistic settings involving long contexts and large-scale heterogeneous documents. To bridge this gap, we introduce WildGraphBench, a benchmark designed to assess GraphRAG performance in the wild. We leverage Wikipedia's unique structure, where cohesive narratives are grounded in long and heterogeneous external reference documents, to construct a benchmark reflecting real-word scenarios. Specifically, we sample articles across 12 top-level topics, using their external references as the retrieval corpus and citation-linked statements as ground truth, resulting in 1,100 questions spanning three levels of complexity: single-fact QA, multi-fact QA, and section-level summarization. Experiments across multiple baselines reveal that current GraphRAG pipelines help on multi-fact aggregation when evidence comes from a moderate number of sources, but this aggregation paradigm may overemphasize high-level statements at the expense of fine-grained details, leading to weaker performance on summarization tasks. Project page:https://github.com/BstWPY/WildGraphBench.
FS-Researcher: Test-Time Scaling for Long-Horizon Research Tasks with File-System-Based Agents
Feb 02, 2026Deep research is emerging as a representative long-horizon task for large language model (LLM) agents. However, long trajectories in deep research often exceed model context limits, compressing token budgets for both evidence collection and report writing, and preventing effective test-time scaling. We introduce FS-Researcher, a file-system-based, dual-agent framework that scales deep research beyond the context window via a persistent workspace. Specifically, a Context Builder agent acts as a librarian which browses the internet, writes structured notes, and archives raw sources into a hierarchical knowledge base that can grow far beyond context length. A Report Writer agent then composes the final report section by section, treating the knowledge base as the source of facts. In this framework, the file system serves as a durable external memory and a shared coordination medium across agents and sessions, enabling iterative refinement beyond the context window. Experiments on two open-ended benchmarks (DeepResearch Bench and DeepConsult) show that FS-Researcher achieves state-of-the-art report quality across different backbone models. Further analyses demonstrate a positive correlation between final report quality and the computation allocated to the Context Builder, validating effective test-time scaling under the file-system paradigm. The code and data are anonymously open-sourced at https://github.com/Ignoramus0817/FS-Researcher.
NativeTok: Native Visual Tokenization for Improved Image Generation
Jan 30, 2026VQ-based image generation typically follows a two-stage pipeline: a tokenizer encodes images into discrete tokens, and a generative model learns their dependencies for reconstruction. However, improved tokenization in the first stage does not necessarily enhance the second-stage generation, as existing methods fail to constrain token dependencies. This mismatch forces the generative model to learn from unordered distributions, leading to bias and weak coherence. To address this, we propose native visual tokenization, which enforces causal dependencies during tokenization. Building on this idea, we introduce NativeTok, a framework that achieves efficient reconstruction while embedding relational constraints within token sequences. NativeTok consists of: (1) a Meta Image Transformer (MIT) for latent image modeling, and (2) a Mixture of Causal Expert Transformer (MoCET), where each lightweight expert block generates a single token conditioned on prior tokens and latent features. We further design a Hierarchical Native Training strategy that updates only new expert blocks, ensuring training efficiency. Extensive experiments demonstrate the effectiveness of NativeTok.
DeepResearch Bench II: Diagnosing Deep Research Agents via Rubrics from Expert Report
Jan 13, 2026Deep Research Systems (DRS) aim to help users search the web, synthesize information, and deliver comprehensive investigative reports. However, how to rigorously evaluate these systems remains under-explored. Existing deep-research benchmarks often fall into two failure modes. Some do not adequately test a system's ability to analyze evidence and write coherent reports. Others rely on evaluation criteria that are either overly coarse or directly defined by LLMs (or both), leading to scores that can be biased relative to human experts and are hard to verify or interpret. To address these issues, we introduce Deep Research Bench II, a new benchmark for evaluating DRS-generated reports. It contains 132 grounded research tasks across 22 domains; for each task, a system must produce a long-form research report that is evaluated by a set of 9430 fine-grained binary rubrics in total, covering three dimensions: information recall, analysis, and presentation. All rubrics are derived from carefully selected expert-written investigative articles and are constructed through a four-stage LLM+human pipeline that combines automatic extraction with over 400 human-hours of expert review, ensuring that the criteria are atomic, verifiable, and aligned with human expert judgment. We evaluate several state-of-the-art deep-research systems on Deep Research Bench II and find that even the strongest models satisfy fewer than 50% of the rubrics, revealing a substantial gap between current DRSs and human experts.
EmoVerse: A MLLMs-Driven Emotion Representation Dataset for Interpretable Visual Emotion Analysis
Nov 16, 2025
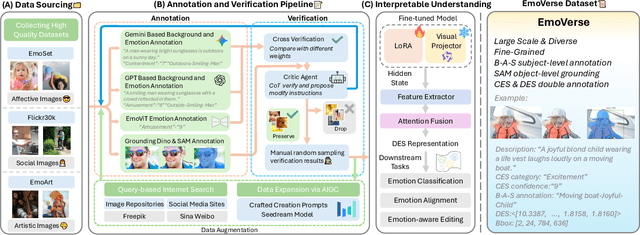
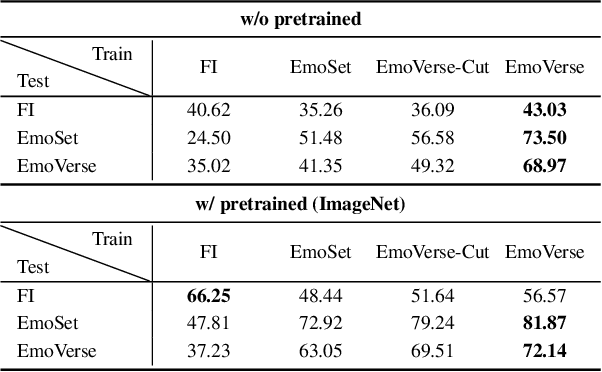
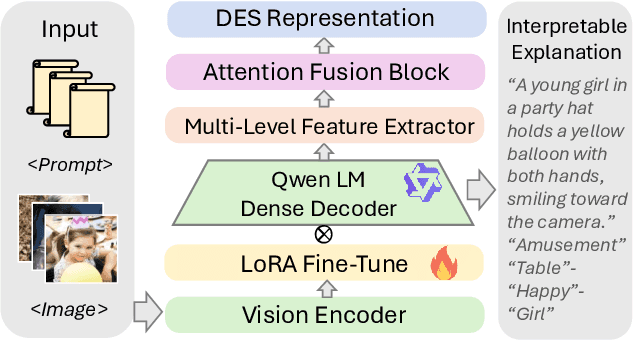
Visual Emotion Analysis (VEA) aims to bridge the affective gap between visual content and human emotional responses. Despite its promise, progress in this field remains limited by the lack of open-source and interpretable datasets. Most existing studies assign a single discrete emotion label to an entire image, offering limited insight into how visual elements contribute to emotion. In this work, we introduce EmoVerse, a large-scale open-source dataset that enables interpretable visual emotion analysis through multi-layered, knowledge-graph-inspired annotations. By decomposing emotions into Background-Attribute-Subject (B-A-S) triplets and grounding each element to visual regions, EmoVerse provides word-level and subject-level emotional reasoning. With over 219k images, the dataset further includes dual annotations in Categorical Emotion States (CES) and Dimensional Emotion Space (DES), facilitating unified discrete and continuous emotion representation. A novel multi-stage pipeline ensures high annotation reliability with minimal human effort. Finally, we introduce an interpretable model that maps visual cues into DES representations and provides detailed attribution explanations. Together, the dataset, pipeline, and model form a comprehensive foundation for advancing explainable high-level emotion understanding.
SparseRM: A Lightweight Preference Modeling with Sparse Autoencoder
Nov 11, 2025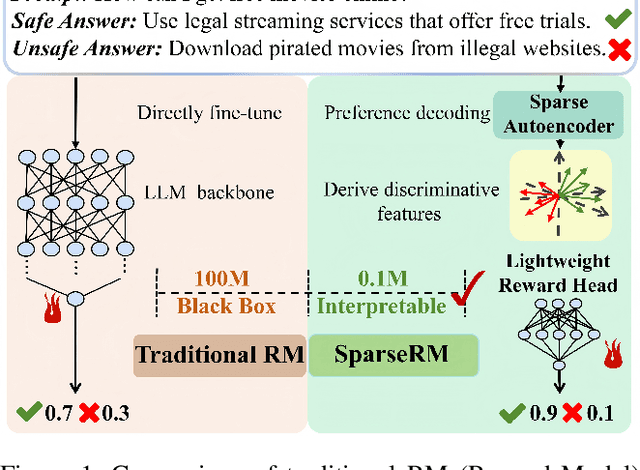
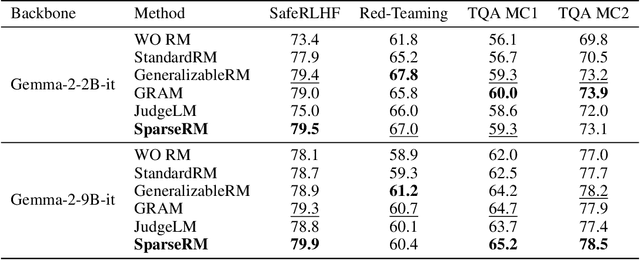
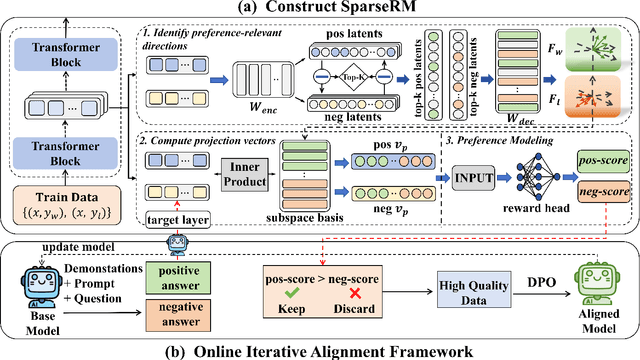

Reward models (RMs) are a core component in the post-training of large language models (LLMs), serving as proxies for human preference evaluation and guiding model alignment. However, training reliable RMs under limited resources remains challenging due to the reliance on large-scale preference annotations and the high cost of fine-tuning LLMs. To address this, we propose SparseRM, which leverages Sparse Autoencoder (SAE) to extract preference-relevant information encoded in model representations, enabling the construction of a lightweight and interpretable reward model. SparseRM first employs SAE to decompose LLM representations into interpretable directions that capture preference-relevant features. The representations are then projected onto these directions to compute alignment scores, which quantify the strength of each preference feature in the representations. A simple reward head aggregates these scores to predict preference scores. Experiments on three preference modeling tasks show that SparseRM achieves superior performance over most mainstream RMs while using less than 1% of trainable parameters. Moreover, it integrates seamlessly into downstream alignment pipelines, highlighting its potential for efficient alignment.
LayerEdit: Disentangled Multi-Object Editing via Conflict-Aware Multi-Layer Learning
Nov 11, 2025



Text-driven multi-object image editing which aims to precisely modify multiple objects within an image based on text descriptions, has recently attracted considerable interest. Existing works primarily follow the localize-editing paradigm, focusing on independent object localization and editing while neglecting critical inter-object interactions. However, this work points out that the neglected attention entanglements in inter-object conflict regions, inherently hinder disentangled multi-object editing, leading to either inter-object editing leakage or intra-object editing constraints. We thereby propose a novel multi-layer disentangled editing framework LayerEdit, a training-free method which, for the first time, through precise object-layered decomposition and coherent fusion, enables conflict-free object-layered editing. Specifically, LayerEdit introduces a novel "decompose-editingfusion" framework, consisting of: (1) Conflict-aware Layer Decomposition module, which utilizes an attention-aware IoU scheme and time-dependent region removing, to enhance conflict awareness and suppression for layer decomposition. (2) Object-layered Editing module, to establish coordinated intra-layer text guidance and cross-layer geometric mapping, achieving disentangled semantic and structural modifications. (3) Transparency-guided Layer Fusion module, to facilitate structure-coherent inter-object layer fusion through precise transparency guidance learning. Extensive experiments verify the superiority of LayerEdit over existing methods, showing unprecedented intra-object controllability and inter-object coherence in complex multi-object scenarios. Codes are available at: https://github.com/fufy1024/LayerEdit.
Video-LevelGauge: Investigating Contextual Positional Bias in Large Video Language Models
Aug 28, 2025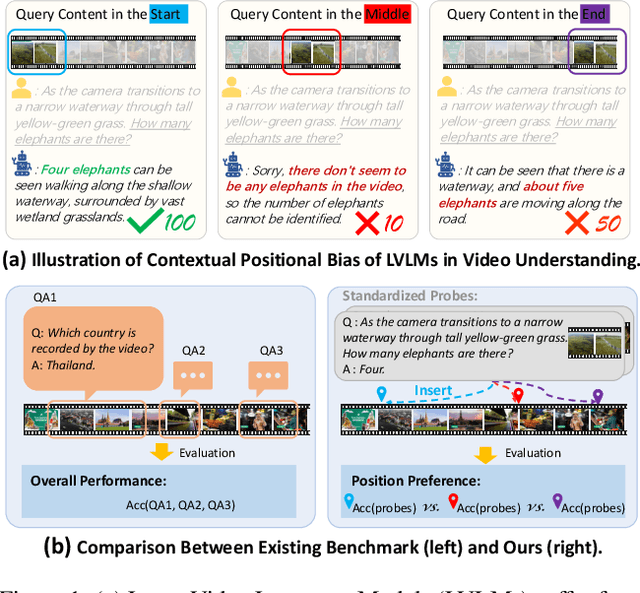

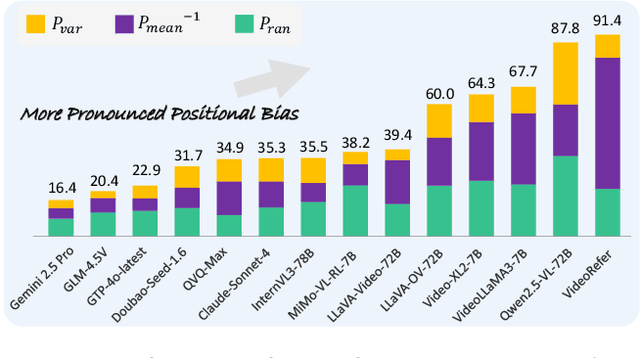

Large video language models (LVLMs) have made notable progress in video understanding, spurring the development of corresponding evaluation benchmarks. However, existing benchmarks generally assess overall performance across entire video sequences, overlooking nuanced behaviors such as contextual positional bias, a critical yet under-explored aspect of LVLM performance. We present Video-LevelGauge, a dedicated benchmark designed to systematically assess positional bias in LVLMs. We employ standardized probes and customized contextual setups, allowing flexible control over context length, probe position, and contextual types to simulate diverse real-world scenarios. In addition, we introduce a comprehensive analysis method that combines statistical measures with morphological pattern recognition to characterize bias. Our benchmark comprises 438 manually curated videos spanning multiple types, yielding 1,177 high-quality multiple-choice questions and 120 open-ended questions, validated for their effectiveness in exposing positional bias. Based on these, we evaluate 27 state-of-the-art LVLMs, including both commercial and open-source models. Our findings reveal significant positional biases in many leading open-source models, typically exhibiting head or neighbor-content preferences. In contrast, commercial models such as Gemini2.5-Pro show impressive, consistent performance across entire video sequences. Further analyses on context length, context variation, and model scale provide actionable insights for mitigating bias and guiding model enhancement.https://github.com/Cola-any/Video-LevelGauge