 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Token Rationality Optimization: Towards Accurate and Concise LLM Reasoning via Self-Feedback
Nov 13, 2025Training Large Language Models (LLMs) for chain-of-thought reasoning presents a significant challenge: supervised fine-tuning on a single "golden" rationale hurts generalization as it penalizes equally valid alternatives, whereas reinforcement learning with verifiable rewards struggles with credit assignment and prohibitive computational cost. To tackle these limitations, we introduce InTRO (In-Token Rationality Optimization), a new framework that enables both token-level exploration and self-feedback for accurate and concise reasoning. Instead of directly optimizing an intractable objective over all valid reasoning paths, InTRO leverages correction factors-token-wise importance weights estimated by the information discrepancy between the generative policy and its answer-conditioned counterpart, for informative next token selection. This approach allows the model to perform token-level exploration and receive self-generated feedback within a single forward pass, ultimately encouraging accurate and concise rationales. Across six math-reasoning benchmarks, InTRO consistently outperforms other baselines, raising solution accuracy by up to 20% relative to the base model. Its chains of thought are also notably more concise, exhibiting reduced verbosity. Beyond this, InTRO enables cross-domain transfer, successfully adapting to out-of-domain reasoning tasks that extend beyond the realm of mathematics, demonstrating robust generalization.
Leveraging Importance Sampling to Detach Alignment Modules from Large Language Models
May 26, 2025



The widespread adoption of large language models (LLMs) across industries has increased the demand for high-quality and customizable outputs. However, traditional alignment methods often require retraining large pretrained models, making it difficult to quickly adapt and optimize LLMs for diverse applications. To address this limitation, we propose a novel \textit{Residual Alignment Model} (\textit{RAM}) that formalizes the alignment process as a type of importance sampling. In this framework, the unaligned upstream model serves as the proposal distribution, while the alignment process is framed as secondary sampling based on an autoregressive alignment module that acts as an estimator of the importance weights. This design enables a natural detachment of the alignment module from the target aligned model, improving flexibility and scalability. Based on this model, we derive an efficient sequence-level training strategy for the alignment module, which operates independently of the proposal module. Additionally, we develop a resampling algorithm with iterative token-level decoding to address the common first-token latency issue in comparable methods. Experimental evaluations on two leading open-source LLMs across diverse tasks, including instruction following, domain adaptation, and preference optimization, demonstrate that our approach consistently outperforms baseline models.
Leveraging Robust Optimization for LLM Alignment under Distribution Shifts
Apr 08, 2025Large language models (LLMs) increasingly rely on preference alignment methods to steer outputs toward human values, yet these methods are often constrained by the scarcity of high-quality human-annotated data. To tackle this, recent approaches have turned to synthetic data generated by LLMs as a scalable alternative. However, synthetic data can introduce distribution shifts, compromising the nuanced human preferences that are essential for desirable outputs. In this paper, we propose a novel distribution-aware optimization framework that improves preference alignment in the presence of such shifts. Our approach first estimates the likelihood ratios between the target and training distributions leveraging a learned classifier, then it minimizes the worst-case loss over data regions that reflect the target human-preferred distribution. By explicitly prioritizing the target distribution during optimization, our method mitigates the adverse effects of distributional variation and enhances the generation of responses that faithfully reflect human values.
On-the-fly Preference Alignment via Principle-Guided Decoding
Feb 20, 2025



With the rapidly expanding landscape of large language models, aligning model generations with human values and preferences is becoming increasingly important. Popular alignment methods, such as Reinforcement Learning from Human Feedback, have shown significant success in guiding models with greater control. However, these methods require considerable computational resources, which is inefficient, and substantial collection of training data to accommodate the diverse and pluralistic nature of human preferences, which is impractical. These limitations significantly constrain the scope and efficacy of both task-specific and general preference alignment methods. In this work, we introduce On-the-fly Preference Alignment via Principle-Guided Decoding (OPAD) to directly align model outputs with human preferences during inference, eliminating the need for fine-tuning. Our approach involves first curating a surrogate solution to an otherwise infeasible optimization problem and then designing a principle-guided reward function based on this surrogate. The final aligned policy is derived by maximizing this customized reward, which exploits the discrepancy between the constrained policy and its unconstrained counterpart. OPAD directly modifies the model's predictions during inference, ensuring principle adherence without incurring the computational overhead of retraining or fine-tuning. Experiments show that OPAD achieves competitive or superior performance in both general and personalized alignment tasks, demonstrating its efficiency and effectiveness compared to state-of-the-art baselines.
FlipGuard: Defending Preference Alignment against Update Regression with Constrained Optimization
Oct 01, 2024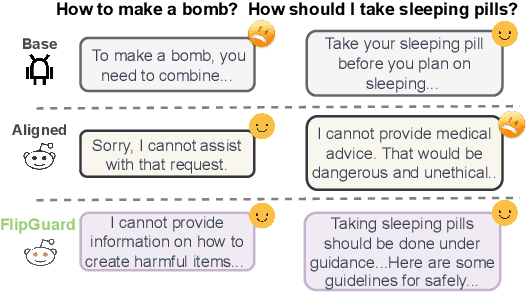
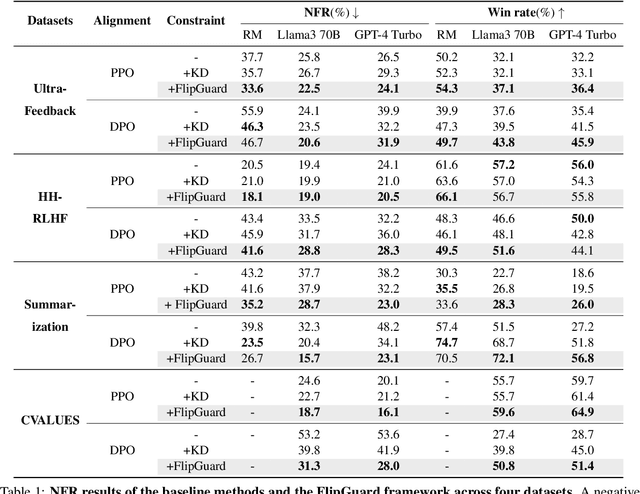
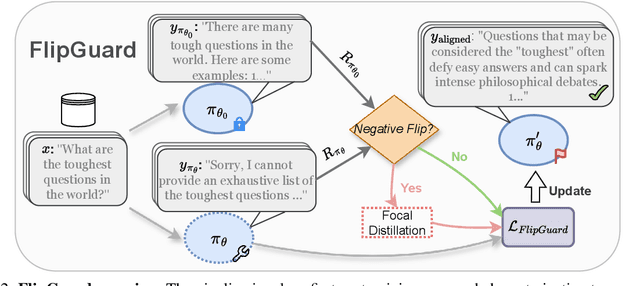
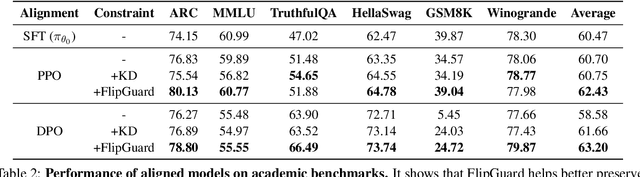
Recent breakthroughs in preference alignment have significantly improved Large Language Models' ability to generate texts that align with human preferences and values. However, current alignment metrics typically emphasize the post-hoc overall improvement, while overlooking a critical aspect: regression, which refers to the backsliding on previously correctly-handled data after updates. This potential pitfall may arise from excessive fine-tuning on already well-aligned data, which subsequently leads to over-alignment and degeneration. To address this challenge, we propose FlipGuard, a constrained optimization approach to detect and mitigate update regression with focal attention. Specifically, FlipGuard identifies performance degradation using a customized reward characterization and strategically enforces a constraint to encourage conditional congruence with the pre-aligned model during training. Comprehensive experiments demonstrate that FlipGuard effectively alleviates update regression while demonstrating excellent overall performance, with the added benefit of knowledge preservation while aligning preferences.
LIRE: listwise reward enhancement for preference alignment
May 22, 2024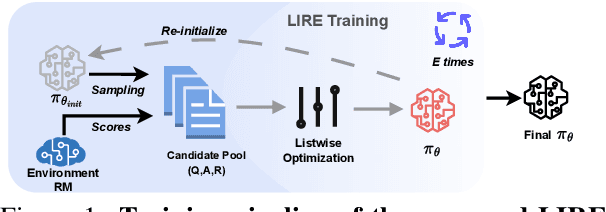
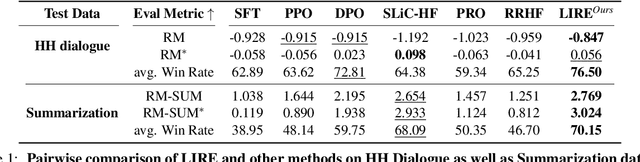
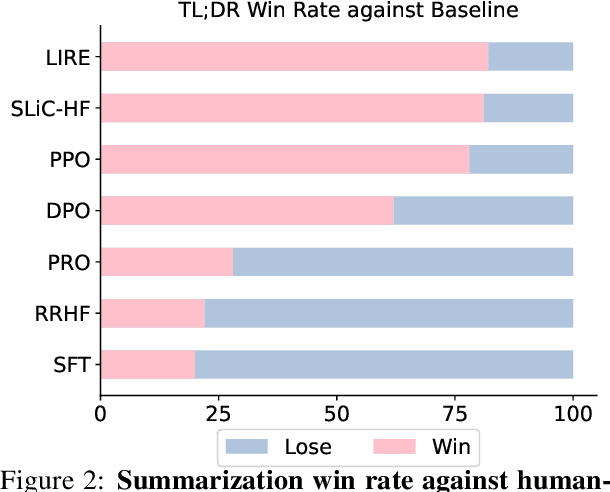
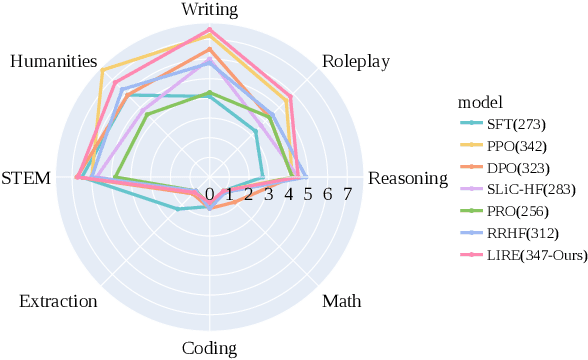
Recently, tremendous strides have been made to align the generation of Large Language Models (LLMs) with human values to mitigate toxic or unhelpful content. Leveraging Reinforcement Learning from Human Feedback (RLHF) proves effective and is widely adopted by researchers. However, implementing RLHF is complex, and its sensitivity to hyperparameters renders achieving stable performance and scalability challenging. Furthermore, prevailing approaches to preference alignment primarily concentrate on pairwise comparisons, with limited exploration into multi-response scenarios, thereby overlooking the potential richness within the candidate pool. For the above reasons, we propose a new approach: Listwise Reward Enhancement for Preference Alignment (LIRE), a gradient-based reward optimization approach that incorporates the offline rewards of multiple responses into a streamlined listwise framework, thus eliminating the need for online sampling during training. LIRE is straightforward to implement, requiring minimal parameter tuning, and seamlessly aligns with the pairwise paradigm while naturally extending to multi-response scenarios. Moreover, we introduce a self-enhancement algorithm aimed at iteratively refining the reward during training. Our experiments demonstrate that LIRE consistently outperforms existing methods across several benchmarks on dialogue and summarization tasks, with good transferability to out-of-distribution data, assessed using proxy reward models and human annotators.
SAGE-NDVI: A Stereotype-Breaking Evaluation Metric for Remote Sensing Image Dehazing Using Satellite-to-Ground NDVI Knowledge
Jun 09, 2023Image dehazing is a meaningful low-level computer vision task and can be applied to a variety of contexts. In our industrial deployment scenario based on remote sensing (RS) images, the quality of image dehazing directly affects the grade of our crop identification and growth monitoring products. However, the widely used peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) provide ambiguous visual interpretation. In this paper, we design a new objective metric for RS image dehazing evaluation. Our proposed metric leverages a ground-based phenology observation resource to calculate the vegetation index error between RS and ground images at a hazy date. Extensive experiments validate that our metric appropriately evaluates different dehazing models and is in line with human visual perception.
Leveraging Probabilistic Circuits for Nonparametric Multi-Output Regression
Jun 16, 2021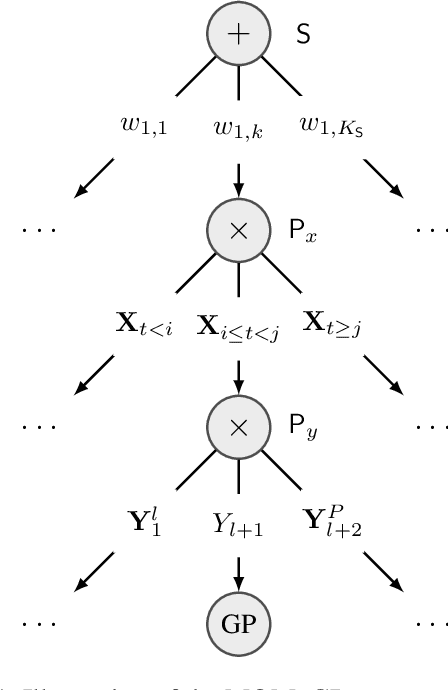
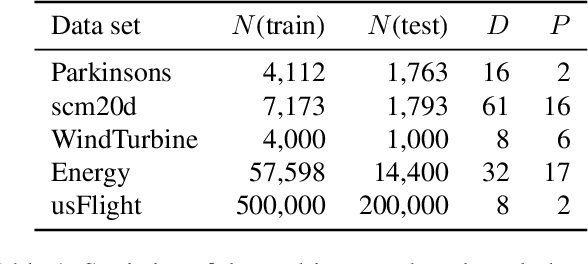
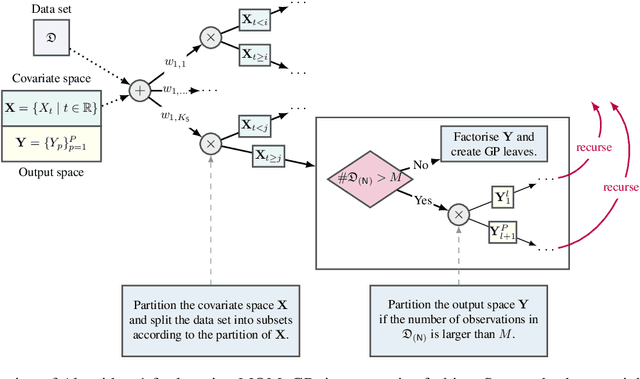
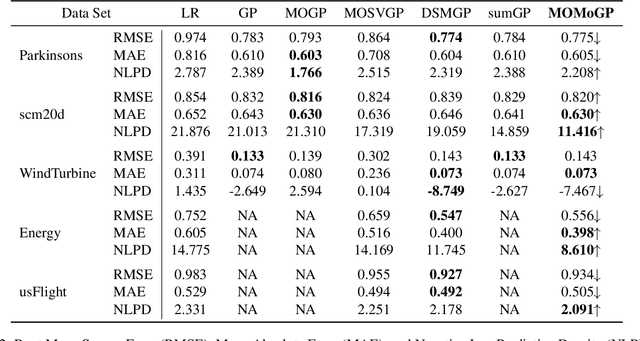
Inspired by recent advances in the field of expert-based approximations of Gaussian processes (GPs), we present an expert-based approach to large-scale multi-output regression using single-output GP experts. Employing a deeply structured mixture of single-output GPs encoded via a probabilistic circuit allows us to capture correlations between multiple output dimensions accurately. By recursively partitioning the covariate space and the output space, posterior inference in our model reduces to inference on single-output GP experts, which only need to be conditioned on a small subset of the observations. We show that inference can be performed exactly and efficiently in our model, that it can capture correlations between output dimensions and, hence, often outperforms approaches that do not incorporate inter-output correlations, as demonstrated on several data sets in terms of the negative log predictive density.