 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccordion-Thinking: Self-Regulated Step Summaries for Efficient and Readable LLM Reasoning
Feb 03, 2026Scaling test-time compute via long Chain-ofThought unlocks remarkable gains in reasoning capabilities, yet it faces practical limits due to the linear growth of KV cache and quadratic attention complexity. In this paper, we introduce Accordion-Thinking, an end-to-end framework where LLMs learn to self-regulate the granularity of the reasoning steps through dynamic summarization. This mechanism enables a Fold inference mode, where the model periodically summarizes its thought process and discards former thoughts to reduce dependency on historical tokens. We apply reinforcement learning to incentivize this capability further, uncovering a critical insight: the accuracy gap between the highly efficient Fold mode and the exhaustive Unfold mode progressively narrows and eventually vanishes over the course of training. This phenomenon demonstrates that the model learns to encode essential reasoning information into compact summaries, achieving effective compression of the reasoning context. Our Accordion-Thinker demonstrates that with learned self-compression, LLMs can tackle complex reasoning tasks with minimal dependency token overhead without compromising solution quality, and it achieves a 3x throughput while maintaining accuracy on a 48GB GPU memory configuration, while the structured step summaries provide a human-readable account of the reasoning process.
CARE What Fails: Contrastive Anchored-REflection for Verifiable Multimodal
Dec 22, 2025Group-relative reinforcement learning with verifiable rewards (RLVR) often wastes the most informative data it already has the failures. When all rollouts are wrong, gradients stall; when one happens to be correct, the update usually ignores why the others are close-but-wrong, and credit can be misassigned to spurious chains. We present CARE (Contrastive Anchored REflection), a failure-centric post-training framework for multimodal reasoning that turns errors into supervision. CARE combines: (i) an anchored-contrastive objective that forms a compact subgroup around the best rollout and a set of semantically proximate hard negatives, performs within-subgroup z-score normalization with negative-only scaling, and includes an all-negative rescue to prevent zero-signal batches; and (ii) Reflection-Guided Resampling (RGR), a one-shot structured self-repair that rewrites a representative failure and re-scores it with the same verifier, converting near-misses into usable positives without any test-time reflection. CARE improves accuracy and training smoothness while explicitly increasing the share of learning signal that comes from failures. On Qwen2.5-VL-7B, CARE lifts macro-averaged accuracy by 4.6 points over GRPO across six verifiable visual-reasoning benchmarks; with Qwen3-VL-8B it reaches competitive or state-of-the-art results on MathVista and MMMU-Pro under an identical evaluation protocol.
When Inverse Data Outperforms: Exploring the Pitfalls of Mixed Data in Multi-Stage Fine-Tuning
Sep 16, 2025Existing work has shown that o1-level performance can be achieved with limited data distillation, but most existing methods focus on unidirectional supervised fine-tuning (SFT), overlooking the intricate interplay between diverse reasoning patterns. In this paper, we construct r1k, a high-quality reverse reasoning dataset derived by inverting 1,000 forward examples from s1k, and examine how SFT and Direct Preference Optimization (DPO) affect alignment under bidirectional reasoning objectives. SFT on r1k yields a 1.6%--6.8% accuracy improvement over s1k across evaluated benchmarks. However, naively mixing forward and reverse data during SFT weakens the directional distinction. Although DPO can partially recover this distinction, it also suppresses less preferred reasoning paths by shifting the probability mass toward irrelevant outputs. These findings suggest that mixed reasoning data introduce conflicting supervision signals, underscoring the need for robust and direction-aware alignment strategies.
Understanding GUI Agent Localization Biases through Logit Sharpness
Jun 18, 2025Multimodal large language models (MLLMs) have enabled GUI agents to interact with operating systems by grounding language into spatial actions. Despite their promising performance, these models frequently exhibit hallucinations-systematic localization errors that compromise reliability. We propose a fine-grained evaluation framework that categorizes model predictions into four distinct types, revealing nuanced failure modes beyond traditional accuracy metrics. To better quantify model uncertainty, we introduce the Peak Sharpness Score (PSS), a metric that evaluates the alignment between semantic continuity and logits distribution in coordinate prediction. Building on this insight, we further propose Context-Aware Cropping, a training-free technique that improves model performance by adaptively refining input context. Extensive experiments demonstrate that our framework and methods provide actionable insights and enhance the interpretability and robustness of GUI agent behavior.
TreeRPO: Tree Relative Policy Optimization
Jun 05, 2025Large Language Models (LLMs) have shown remarkable reasoning capabilities through Reinforcement Learning with Verifiable Rewards (RLVR) methods. However, a key limitation of existing approaches is that rewards defined at the full trajectory level provide insufficient guidance for optimizing the intermediate steps of a reasoning process. To address this, we introduce \textbf{\name}, a novel method that estimates the mathematical expectations of rewards at various reasoning steps using tree sampling. Unlike prior methods that rely on a separate step reward model, \name directly estimates these rewards through this sampling process. Building on the group-relative reward training mechanism of GRPO, \name innovatively computes rewards based on step-level groups generated during tree sampling. This advancement allows \name to produce fine-grained and dense reward signals, significantly enhancing the learning process and overall performance of LLMs. Experimental results demonstrate that our \name algorithm substantially improves the average Pass@1 accuracy of Qwen-2.5-Math on test benchmarks, increasing it from 19.0\% to 35.5\%. Furthermore, \name significantly outperforms GRPO by 2.9\% in performance while simultaneously reducing the average response length by 18.1\%, showcasing its effectiveness and efficiency. Our code will be available at \href{https://github.com/yangzhch6/TreeRPO}{https://github.com/yangzhch6/TreeRPO}.
Are LLMs Really Not Knowledgable? Mining the Submerged Knowledge in LLMs' Memory
Dec 30, 2024Large language models (LLMs) have shown promise as potential knowledge bases, yet they often struggle with question-answering tasks and are prone to hallucinations. While previous research attributes these issues to knowledge gaps in the model's parameters, our investigation reveals a different phenomenon: LLMs often retain correct knowledge even when generating incorrect answers. Through analysis of model's internal representations, we find that correct answers frequently appear among high-probability tokens despite not being selected as final outputs. Based on this observation, we introduce Hits@k, a new metric to assess knowledge retention independent of expression accuracy. Our extensive experiments demonstrate that LLMs store significantly more knowledge than their QA performance suggests. Building on these findings, we develop SkipUnsure, a method to improve answer accuracy by leveraging detected but unexpressed knowledge. Experiments on both open-domain and specific-domain datasets show consistent improvements, with accuracy gains of up to 11.8% on DBPedia and 6.3% on IMDB, without requiring model retraining.
CityWalker: Learning Embodied Urban Navigation from Web-Scale Videos
Nov 26, 2024Navigating dynamic urban environments presents significant challenges for embodied agents, requiring advanced spatial reasoning and adherence to common-sense norms. Despite progress, existing visual navigation methods struggle in map-free or off-street settings, limiting the deployment of autonomous agents like last-mile delivery robots. To overcome these obstacles, we propose a scalable, data-driven approach for human-like urban navigation by training agents on thousands of hours of in-the-wild city walking and driving videos sourced from the web. We introduce a simple and scalable data processing pipeline that extracts action supervision from these videos, enabling large-scale imitation learning without costly annotations. Our model learns sophisticated navigation policies to handle diverse challenges and critical scenarios. Experimental results show that training on large-scale, diverse datasets significantly enhances navigation performance, surpassing current methods. This work shows the potential of using abundant online video data to develop robust navigation policies for embodied agents in dynamic urban settings. https://ai4ce.github.io/CityWalker/
ZALM3: Zero-Shot Enhancement of Vision-Language Alignment via In-Context Information in Multi-Turn Multimodal Medical Dialogue
Sep 26, 2024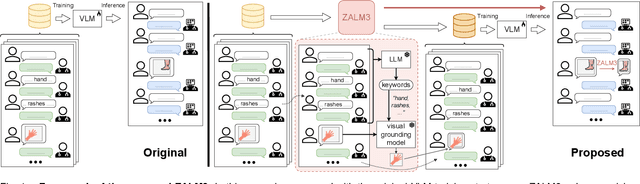
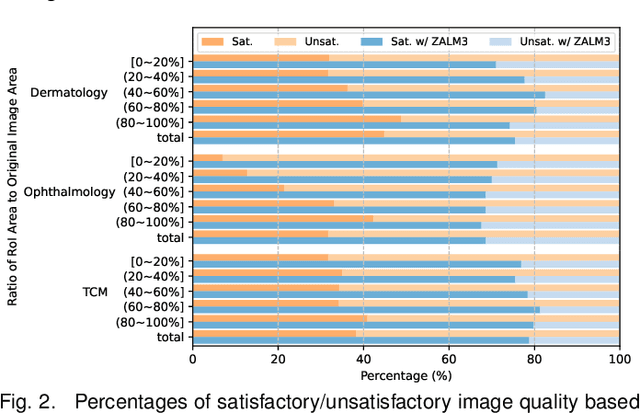
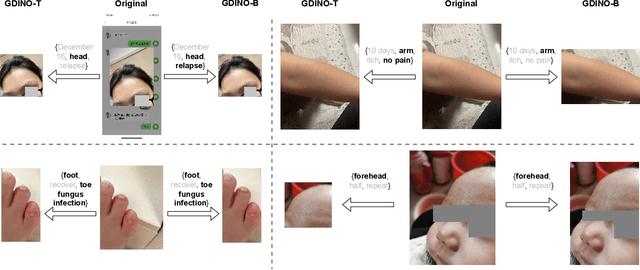
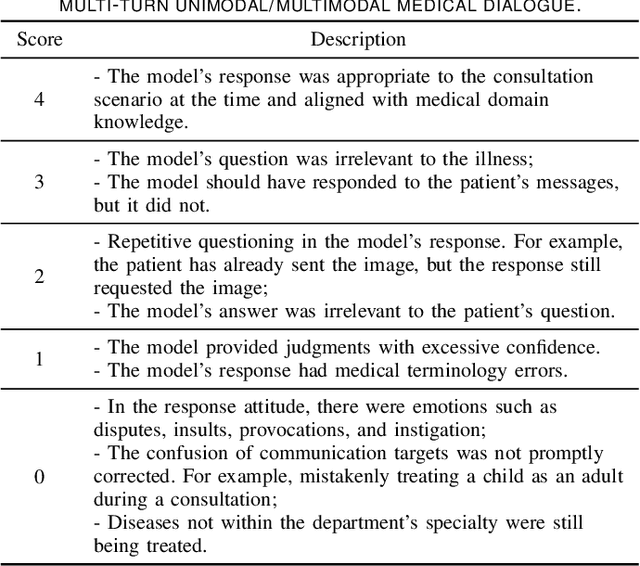
The rocketing prosperity of large language models (LLMs) in recent years has boosted the prevalence of vision-language models (VLMs) in the medical sector. In our online medical consultation scenario, a doctor responds to the texts and images provided by a patient in multiple rounds to diagnose her/his health condition, forming a multi-turn multimodal medical dialogue format. Unlike high-quality images captured by professional equipment in traditional medical visual question answering (Med-VQA), the images in our case are taken by patients' mobile phones. These images have poor quality control, with issues such as excessive background elements and the lesion area being significantly off-center, leading to degradation of vision-language alignment in the model training phase. In this paper, we propose ZALM3, a Zero-shot strategy to improve vision-language ALignment in Multi-turn Multimodal Medical dialogue. Since we observe that the preceding text conversations before an image can infer the regions of interest (RoIs) in the image, ZALM3 employs an LLM to summarize the keywords from the preceding context and a visual grounding model to extract the RoIs. The updated images eliminate unnecessary background noise and provide more effective vision-language alignment. To better evaluate our proposed method, we design a new subjective assessment metric for multi-turn unimodal/multimodal medical dialogue to provide a fine-grained performance comparison. Our experiments across three different clinical departments remarkably demonstrate the efficacy of ZALM3 with statistical significance.
Benchmarking LLMs for Optimization Modeling and Enhancing Reasoning via Reverse Socratic Synthesis
Jul 13, 2024



Large language models (LLMs) have exhibited their problem-solving ability in mathematical reasoning. Solving realistic optimization (OPT) problems in industrial application scenarios requires advanced and applied math ability. However, current OPT benchmarks that merely solve linear programming are far from complex realistic situations. In this work, we propose E-OPT, a benchmark for end-to-end optimization problem-solving with human-readable inputs and outputs. E-OPT contains rich optimization problems, including linear/nonlinear programming with/without table data, which can comprehensively evaluate LLMs' solving ability. In our benchmark, LLMs are required to correctly understand the problem in E-OPT and call code solver to get precise numerical answers. Furthermore, to alleviate the data scarcity for optimization problems, and to bridge the gap between open-source LLMs on a small scale (e.g., Llama-2-7b and Llama-3-8b) and closed-source LLMs (e.g., GPT-4), we further propose a novel data synthesis method namely ReSocratic. Unlike general data synthesis methods that proceed from questions to answers, ReSocratic first incrementally synthesizes optimization scenarios with mathematical formulations step by step and then back-translates the generated scenarios into questions. In such a way, we construct the ReSocratic-29k dataset from a small seed sample pool with the powerful open-source large model DeepSeek-V2. To demonstrate the effectiveness of ReSocratic, we conduct supervised fine-tuning with ReSocratic-29k on multiple open-source models. The results show that Llama3-8b is significantly improved from 13.6% to 51.7% on E-OPT, while DeepSeek-V2 reaches 61.0%, approaching 65.5% of GPT-4.
Process-Driven Autoformalization in Lean 4
Jun 04, 2024



Autoformalization, the conversion of natural language mathematics into formal languages, offers significant potential for advancing mathematical reasoning. However, existing efforts are limited to formal languages with substantial online corpora and struggle to keep pace with rapidly evolving languages like Lean 4. To bridge this gap, we propose a new benchmark \textbf{Form}alization for \textbf{L}ean~\textbf{4} (\textbf{\name}) designed to evaluate the autoformalization capabilities of large language models (LLMs). This benchmark encompasses a comprehensive assessment of questions, answers, formal statements, and proofs. Additionally, we introduce a \textbf{P}rocess-\textbf{S}upervised \textbf{V}erifier (\textbf{PSV}) model that leverages the precise feedback from Lean 4 compilers to enhance autoformalization. Our experiments demonstrate that the PSV method improves autoformalization, enabling higher accuracy using less filtered training data. Furthermore, when fine-tuned with data containing detailed process information, PSV can leverage the data more effectively, leading to more significant improvements in autoformalization for Lean 4. Our dataset and code are available at \url{https://github.com/rookie-joe/PDA}.