 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
May 20, 2025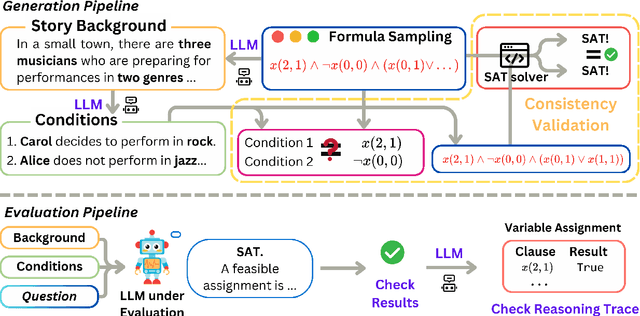



We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
FormalAlign: Automated Alignment Evaluation for Autoformalization
Oct 14, 2024



Autoformalization aims to convert informal mathematical proofs into machine-verifiable formats, bridging the gap between natural and formal languages. However, ensuring semantic alignment between the informal and formalized statements remains challenging. Existing approaches heavily rely on manual verification, hindering scalability. To address this, we introduce \textsc{FormalAlign}, the first automated framework designed for evaluating the alignment between natural and formal languages in autoformalization. \textsc{FormalAlign} trains on both the autoformalization sequence generation task and the representational alignment between input and output, employing a dual loss that combines a pair of mutually enhancing autoformalization and alignment tasks. Evaluated across four benchmarks augmented by our proposed misalignment strategies, \textsc{FormalAlign} demonstrates superior performance. In our experiments, \textsc{FormalAlign} outperforms GPT-4, achieving an Alignment-Selection Score 11.58\% higher on \forml-Basic (99.21\% vs. 88.91\%) and 3.19\% higher on MiniF2F-Valid (66.39\% vs. 64.34\%). This effective alignment evaluation significantly reduces the need for manual verification. Both the dataset and code can be accessed via~\url{https://github.com/rookie-joe/FormalAlign}.
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024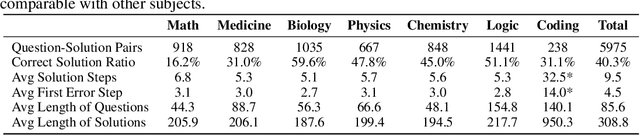
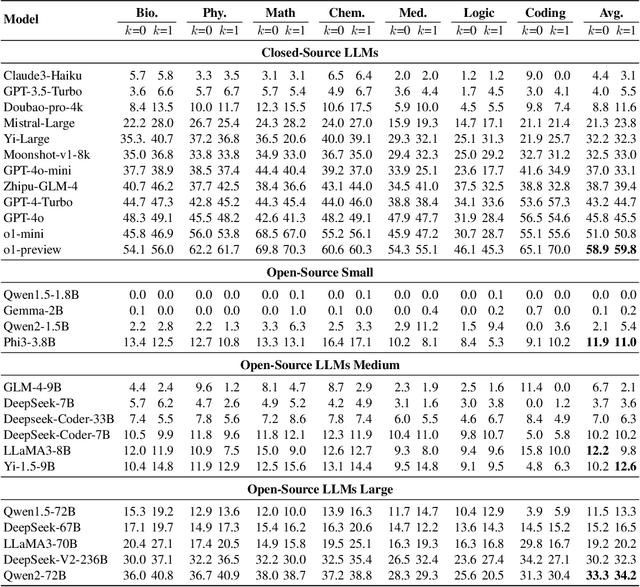
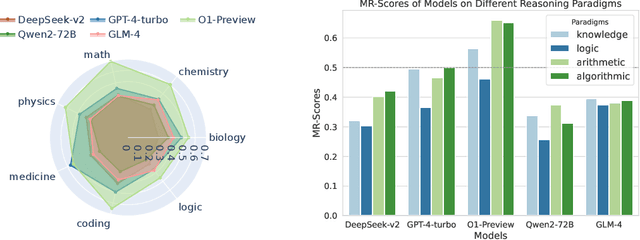
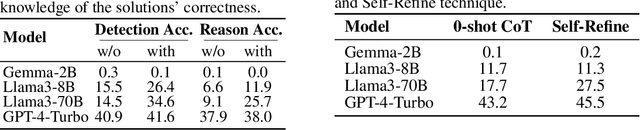
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
Process-Driven Autoformalization in Lean 4
Jun 04, 2024



Autoformalization, the conversion of natural language mathematics into formal languages, offers significant potential for advancing mathematical reasoning. However, existing efforts are limited to formal languages with substantial online corpora and struggle to keep pace with rapidly evolving languages like Lean 4. To bridge this gap, we propose a new benchmark \textbf{Form}alization for \textbf{L}ean~\textbf{4} (\textbf{\name}) designed to evaluate the autoformalization capabilities of large language models (LLMs). This benchmark encompasses a comprehensive assessment of questions, answers, formal statements, and proofs. Additionally, we introduce a \textbf{P}rocess-\textbf{S}upervised \textbf{V}erifier (\textbf{PSV}) model that leverages the precise feedback from Lean 4 compilers to enhance autoformalization. Our experiments demonstrate that the PSV method improves autoformalization, enabling higher accuracy using less filtered training data. Furthermore, when fine-tuned with data containing detailed process information, PSV can leverage the data more effectively, leading to more significant improvements in autoformalization for Lean 4. Our dataset and code are available at \url{https://github.com/rookie-joe/PDA}.
AutoCV: Empowering Reasoning with Automated Process Labeling via Confidence Variation
May 29, 2024



In this work, we propose a novel method named \textbf{Auto}mated Process Labeling via \textbf{C}onfidence \textbf{V}ariation (\textbf{\textsc{AutoCV}}) to enhance the reasoning capabilities of large language models (LLMs) by automatically annotating the reasoning steps. Our approach begins by training a verification model on the correctness of final answers, enabling it to generate automatic process annotations. This verification model assigns a confidence score to each reasoning step, indicating the probability of arriving at the correct final answer from that point onward. We detect relative changes in the verification's confidence scores across reasoning steps to automatically annotate the reasoning process. This alleviates the need for numerous manual annotations or the high computational costs associated with model-induced annotation approaches. We experimentally validate that the confidence variations learned by the verification model trained on the final answer correctness can effectively identify errors in the reasoning steps. Subsequently, we demonstrate that the process annotations generated by \textsc{AutoCV} can improve the accuracy of the verification model in selecting the correct answer from multiple outputs generated by LLMs. Notably, we achieve substantial improvements across five datasets in mathematics and commonsense reasoning. The source code of \textsc{AutoCV} is available at \url{https://github.com/rookie-joe/AUTOCV}.