 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024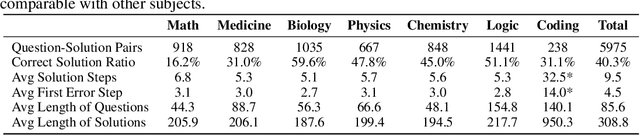
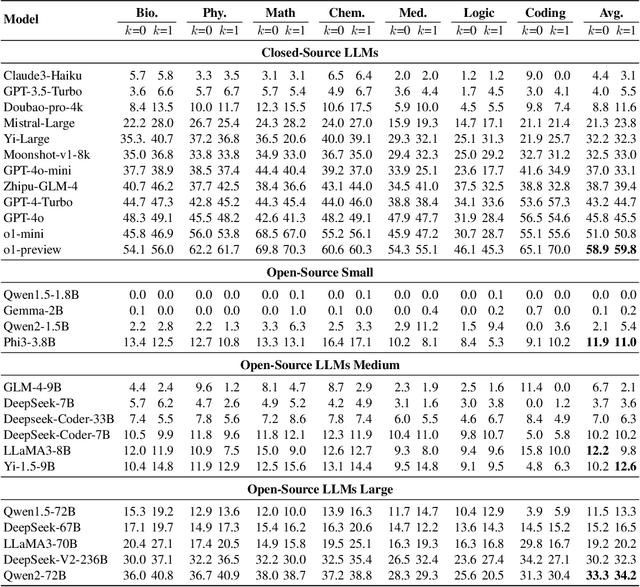
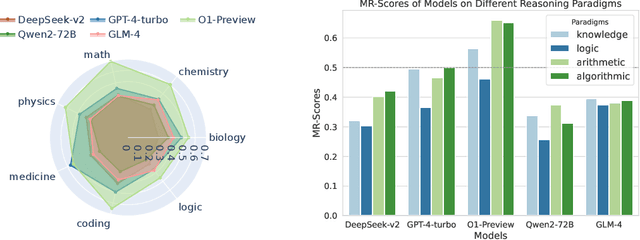
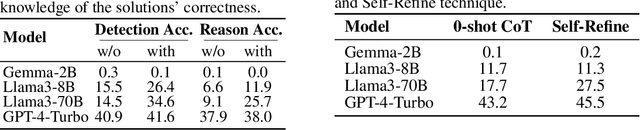
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
Challenge LLMs to Reason About Reasoning: A Benchmark to Unveil Cognitive Depth in LLMs
Dec 28, 2023



In this work, we introduce a novel evaluation paradigm for Large Language Models, one that challenges them to engage in meta-reasoning. This approach addresses critical shortcomings in existing math problem-solving benchmarks, traditionally used to evaluate the cognitive capabilities of agents. Our paradigm shifts the focus from result-oriented assessments, which often overlook the reasoning process, to a more holistic evaluation that effectively differentiates the cognitive capabilities among models. For example, in our benchmark, GPT-4 demonstrates a performance ten times more accurate than GPT3-5. The significance of this new paradigm lies in its ability to reveal potential cognitive deficiencies in LLMs that current benchmarks, such as GSM8K, fail to uncover due to their saturation and lack of effective differentiation among varying reasoning abilities. Our comprehensive analysis includes several state-of-the-art math models from both open-source and closed-source communities, uncovering fundamental deficiencies in their training and evaluation approaches. This paper not only advocates for a paradigm shift in the assessment of LLMs but also contributes to the ongoing discourse on the trajectory towards Artificial General Intelligence (AGI). By promoting the adoption of meta-reasoning evaluation methods similar to ours, we aim to facilitate a more accurate assessment of the true cognitive abilities of LLMs.
Self-Consistent Learning: Cooperation between Generators and Discriminators
Mar 26, 2023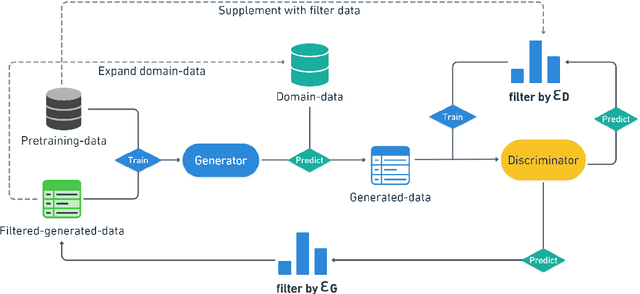
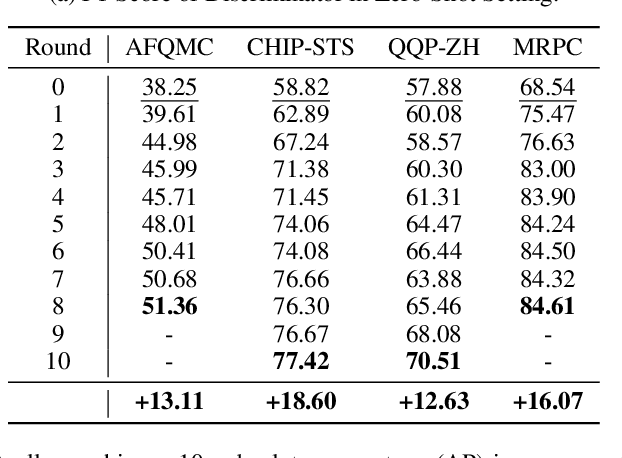
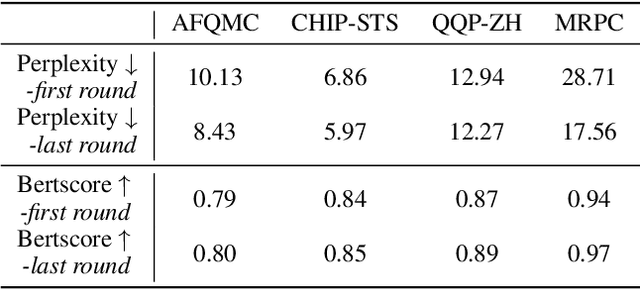
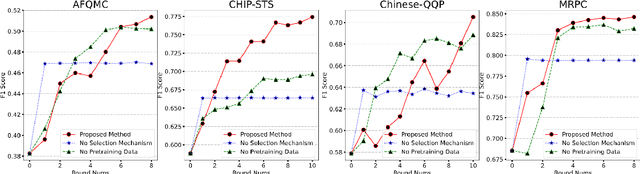
Using generated data to improve the performance of downstream discriminative models has recently gained popularity due to the great development of pre-trained language models. In most previous studies, generative models and discriminative models are trained separately and thus could not adapt to any changes in each other. As a result, the generated samples can easily deviate from the real data distribution, while the improvement of the discriminative model quickly reaches saturation. Generative adversarial networks (GANs) train generative models via an adversarial process with discriminative models to achieve joint training. However, the training of standard GANs is notoriously unstable and often falls short of convergence. In this paper, to address these issues, we propose a $\textit{self-consistent learning}$ framework, in which a discriminator and a generator are cooperatively trained in a closed-loop form. The discriminator and the generator enhance each other during multiple rounds of alternating training until a scoring consensus is reached. This framework proves to be easy to train and free from instabilities such as mode collapse and non-convergence. Extensive experiments on sentence semantic matching demonstrate the effectiveness of the proposed framework: the discriminator achieves 10+ AP of improvement on the zero-shot setting and new state-of-the-art performance on the full-data setting.
Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence
Sep 07, 2022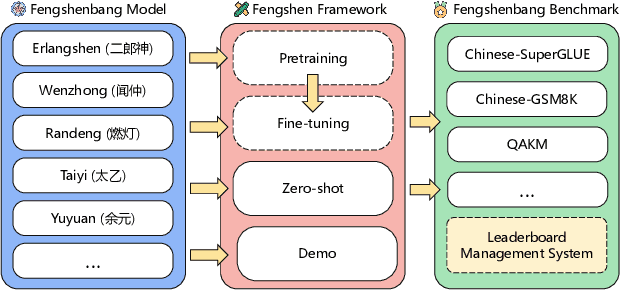
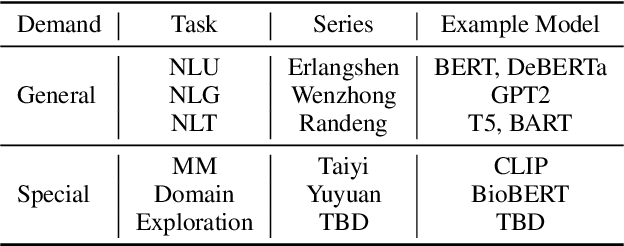

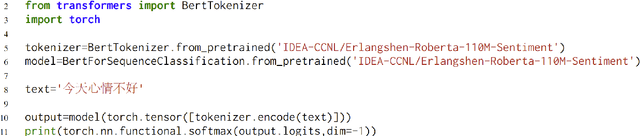
Nowadays, foundation models become one of fundamental infrastructures in artificial intelligence, paving ways to the general intelligence. However, the reality presents two urgent challenges: existing foundation models are dominated by the English-language community; users are often given limited resources and thus cannot always use foundation models. To support the development of the Chinese-language community, we introduce an open-source project, called Fengshenbang, which leads by the research center for Cognitive Computing and Natural Language (CCNL). Our project has comprehensive capabilities, including large pre-trained models, user-friendly APIs, benchmarks, datasets, and others. We wrap all these in three sub-projects: the Fengshenbang Model, the Fengshen Framework, and the Fengshen Benchmark. An open-source roadmap, Fengshenbang, aims to re-evaluate the open-source community of Chinese pre-trained large-scale models, prompting the development of the entire Chinese large-scale model community. We also want to build a user-centered open-source ecosystem to allow individuals to access the desired models to match their computing resources. Furthermore, we invite companies, colleges, and research institutions to collaborate with us to build the large-scale open-source model-based ecosystem. We hope that this project will be the foundation of Chinese cognitive intelligence.