 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Audio Reasoning in Multimodal Foundation Models
May 20, 2026Reasoning has become a defining capability of modern foundation models, yet its development in the audio modality remains limited. Audio poses challenges that are distinct from those of text and vision. It is continuous, temporally dense, and contains linguistic, paralinguistic, and environmental information at multiple time scales. As a result, audio reasoning models must align acoustic signals with the discrete semantic space of large language models, while still preserving fine-grained information needed for reliable inference. Progress is also limited by three major obstacles: the scarcity of genuinely audio-grounded reasoning data, shortcut learning and modality hallucination, and the tension between reasoning depth and real-time latency in spoken interaction. In this paper, we present the first dedicated survey of audio reasoning. We provide a unified formulation that distinguishes direct predictive modeling from reasoning-augmented generation, review the architectural and training foundations of audio reasoning models, and systematically organize recent advances in Audio-to-Text, Audio-to-Speech, Audio-Visual Reasoning and Agentic Audio Reasoning. We further examine emerging paradigms such as Chain-of-Thought prompting, supervised fine-tuning, reinforcement learning, and latency-aware spoken interaction, and discuss evaluation practices, open challenges, and future directions. Our goal is to offer a coherent roadmap for developing robust, efficient, and natively grounded audio reasoning systems.
Efficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
May 19, 2026Diffusion Language Models (DLMs) enable globally coherent, bidirectional, and controllable text generation, offering advantages over traditional autoregressive LLMs, while scaling to ultra-long sequences remains costly. Many existing block-sparse attention methods select blocks by fixed sampling patterns over the high-resolution attention space, such as tail regions or anti-diagonal stripes. Such prior-driven sampling can miss salient tokens and introduce instability under distribution shifts. In this paper, we propose the Block Approximate Sparse Attention framework (BA-Att) with block-wise pre-downsampled operation, which identifies informative regions within a compact downsampled space, avoiding reliance on brittle positional priors. To analyze its theoretical behavior, we define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Based on this insight, we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances, reducing computational complexity. Extensive experiments show that our operator achieves up to 6.95x acceleration over FlashAttention in attention computation, and maintains near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models, demonstrating strong efficiency and generalization.
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Apr 24, 2026As AI systems move from generating text to accomplishing goals through sustained interaction, the ability to model environment dynamics becomes a central bottleneck. Agents that manipulate objects, navigate software, coordinate with others, or design experiments require predictive environment models, yet the term world model carries different meanings across research communities. We introduce a "levels x laws" taxonomy organized along two axes. The first defines three capability levels: L1 Predictor, which learns one-step local transition operators; L2 Simulator, which composes them into multi-step, action-conditioned rollouts that respect domain laws; and L3 Evolver, which autonomously revises its own model when predictions fail against new evidence. The second identifies four governing-law regimes: physical, digital, social, and scientific. These regimes determine what constraints a world model must satisfy and where it is most likely to fail. Using this framework, we synthesize over 400 works and summarize more than 100 representative systems spanning model-based reinforcement learning, video generation, web and GUI agents, multi-agent social simulation, and AI-driven scientific discovery. We analyze methods, failure modes, and evaluation practices across level-regime pairs, propose decision-centric evaluation principles and a minimal reproducible evaluation package, and outline architectural guidance, open problems, and governance challenges. The resulting roadmap connects previously isolated communities and charts a path from passive next-step prediction toward world models that can simulate, and ultimately reshape, the environments in which agents operate.
StarVLA-$α$: Reducing Complexity in Vision-Language-Action Systems
Apr 13, 2026Vision-Language-Action (VLA) models have recently emerged as a promising paradigm for building general-purpose robotic agents. However, the VLA landscape remains highly fragmented and complex: as existing approaches vary substantially in architectures, training data, embodiment configurations, and benchmark-specific engineering. In this work, we introduce StarVLA-$α$, a simple yet strong baseline designed to study VLA design choices under controlled conditions. StarVLA-$α$ deliberately minimizes architectural and pipeline complexity to reduce experimental confounders and enable systematic analysis. Specifically, we re-evaluate several key design axes, including action modeling strategies, robot-specific pretraining, and interface engineering. Across unified multi-benchmark training on LIBERO, SimplerEnv, RoboTwin, and RoboCasa, the same simple baseline remains highly competitive, indicating that a strong VLM backbone combined with minimal design is already sufficient to achieve strong performance without relying on additional architectural complexity or engineering tricks. Notably, our single generalist model outperforms $π_{0.5}$ by 20\% on the public real-world RoboChallenge benchmark. We expect StarVLA-$α$ to serve as a solid starting point for future research in the VLA regime. Code will be released at https://github.com/starVLA/starVLA.
VP-VLA: Visual Prompting as an Interface for Vision-Language-Action Models
Mar 23, 2026Vision-Language-Action (VLA) models typically map visual observations and linguistic instructions directly to robotic control signals. This "black-box" mapping forces a single forward pass to simultaneously handle instruction interpretation, spatial grounding, and low-level control, often leading to poor spatial precision and limited robustness in out-of-distribution scenarios. To address these limitations, we propose VP-VLA, a dual-system framework that decouples high-level reasoning and low-level execution via a structured visual prompting interface. Specifically, a "System 2 Planner" decomposes complex instructions into sub-tasks and identifies relevant target objects and goal locations. These spatial anchors are then overlaid directly onto visual observations as structured visual prompts, such as crosshairs and bounding boxes. Guided by these prompts and enhanced by a novel auxiliary visual grounding objective during training, a "System 1 Controller" reliably generates precise low-level execution motions. Experiments on the Robocasa-GR1-Tabletop benchmark and SimplerEnv simulation demonstrate that VP-VLA improves success rates by 5% and 8.3%, surpassing competitive baselines including QwenOFT and GR00T-N1.6.
SearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation
Jan 21, 2026Search agents have emerged as a pivotal paradigm for solving open-ended, knowledge-intensive reasoning tasks. However, training these agents via Reinforcement Learning (RL) faces a critical dilemma: interacting with live commercial Web APIs is prohibitively expensive, while relying on static data snapshots often introduces noise due to data misalignment. This misalignment generates corrupted reward signals that destabilize training by penalizing correct reasoning or rewarding hallucination. To address this, we propose SearchGym, a simulation environment designed to bootstrap robust search agents. SearchGym employs a rigorous generative pipeline to construct a verifiable knowledge graph and an aligned document corpus, ensuring that every reasoning task is factually grounded and strictly solvable. Building on this controllable environment, we introduce SearchGym-RL, a curriculum learning methodology that progressively optimizes agent policies through purified feedback, evolving from basic interactions to complex, long-horizon planning. Extensive experiments across the Llama and Qwen families demonstrate strong Sim-to-Real generalization. Notably, our Qwen2.5-7B-Base model trained within SearchGym surpasses the web-enhanced ASearcher baseline across nine diverse benchmarks by an average relative margin of 10.6%. Our results validate that high-fidelity simulation serves as a scalable and highly cost-effective methodology for developing capable search agents.
DreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
VisionDirector: Vision-Language Guided Closed-Loop Refinement for Generative Image Synthesis
Dec 22, 2025Generative models can now produce photorealistic imagery, yet they still struggle with the long, multi-goal prompts that professional designers issue. To expose this gap and better evaluate models' performance in real-world settings, we introduce Long Goal Bench (LGBench), a 2,000-task suite (1,000 T2I and 1,000 I2I) whose average instruction contains 18 to 22 tightly coupled goals spanning global layout, local object placement, typography, and logo fidelity. We find that even state-of-the-art models satisfy fewer than 72 percent of the goals and routinely miss localized edits, confirming the brittleness of current pipelines. To address this, we present VisionDirector, a training-free vision-language supervisor that (i) extracts structured goals from long instructions, (ii) dynamically decides between one-shot generation and staged edits, (iii) runs micro-grid sampling with semantic verification and rollback after every edit, and (iv) logs goal-level rewards. We further fine-tune the planner with Group Relative Policy Optimization, yielding shorter edit trajectories (3.1 versus 4.2 steps) and stronger alignment. VisionDirector achieves new state of the art on GenEval (plus 7 percent overall) and ImgEdit (plus 0.07 absolute) while producing consistent qualitative improvements on typography, multi-object scenes, and pose editing.
RePlan: Reasoning-guided Region Planning for Complex Instruction-based Image Editing
Dec 18, 2025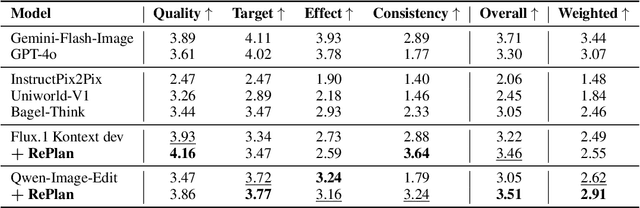
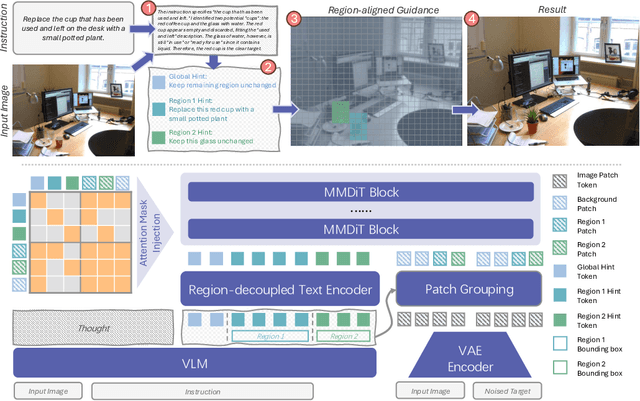

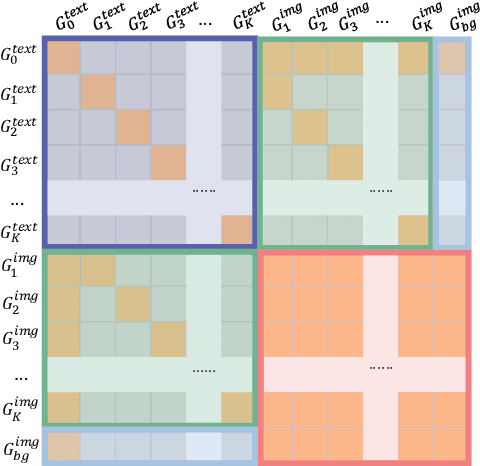
Instruction-based image editing enables natural-language control over visual modifications, yet existing models falter under Instruction-Visual Complexity (IV-Complexity), where intricate instructions meet cluttered or ambiguous scenes. We introduce RePlan (Region-aligned Planning), a plan-then-execute framework that couples a vision-language planner with a diffusion editor. The planner decomposes instructions via step-by-step reasoning and explicitly grounds them to target regions; the editor then applies changes using a training-free attention-region injection mechanism, enabling precise, parallel multi-region edits without iterative inpainting. To strengthen planning, we apply GRPO-based reinforcement learning using 1K instruction-only examples, yielding substantial gains in reasoning fidelity and format reliability. We further present IV-Edit, a benchmark focused on fine-grained grounding and knowledge-intensive edits. Across IV-Complex settings, RePlan consistently outperforms strong baselines trained on far larger datasets, improving regional precision and overall fidelity. Our project page: https://replan-iv-edit.github.io
UnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
Dec 08, 2025Recent video generation models demonstrate impressive synthesis capabilities but remain limited by single-modality conditioning, constraining their holistic world understanding. This stems from insufficient cross-modal interaction and limited modal diversity for comprehensive world knowledge representation. To address these limitations, we introduce UnityVideo, a unified framework for world-aware video generation that jointly learns across multiple modalities (segmentation masks, human skeletons, DensePose, optical flow, and depth maps) and training paradigms. Our approach features two core components: (1) dynamic noising to unify heterogeneous training paradigms, and (2) a modality switcher with an in-context learner that enables unified processing via modular parameters and contextual learning. We contribute a large-scale unified dataset with 1.3M samples. Through joint optimization, UnityVideo accelerates convergence and significantly enhances zero-shot generalization to unseen data. We demonstrate that UnityVideo achieves superior video quality, consistency, and improved alignment with physical world constraints. Code and data can be found at: https://github.com/dvlab-research/UnityVideo