 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noisy Traces to Stable Gradients: Bias-Variance Optimized Preference Optimization for Aligning Large Reasoning Models
Oct 06, 2025Large reasoning models (LRMs) generate intermediate reasoning traces before producing final answers, yielding strong gains on multi-step and mathematical tasks. Yet aligning LRMs with human preferences, a crucial prerequisite for model deployment, remains underexplored. The statistically correct objective for preference alignment requires marginalizing over reasoning traces, but this computation is intractable in practice. A common workaround optimizes a single sampled trajectory, which introduces substantial gradient variance from stochastic trace sampling. To address this challenge, we frame preference optimization for LRMs through the lens of the bias--variance trade-off and propose Bias--Variance Optimized Preference Optimization (BVPO), a simple, drop-in method that mixes two gradient estimators: a high-variance trace-based estimator and a low-variance empty-trace estimator obtained by disabling reasoning trace generation. Our theory shows that BVPO strictly reduces trace-induced variance for any nontrivial mixture, provides a closed-form choice of the mixing weight that minimizes mean-squared error relative to the true marginal gradient, and under standard smoothness and step-size conditions, tightens classical convergence bounds for stochastic gradient descent. Empirically, BVPO improves alignment over the best baseline by up to 7.8 points on AlpacaEval~2 and 6.8 points on Arena-Hard. Despite being trained only on general conversational data, BVPO also boosts reasoning performance for base models by up to 4.0 points on the average of six math reasoning benchmarks. These results identify variance from trace sampling as a key bottleneck and demonstrate that directly optimizing the bias--variance trade-off yields more stable training and stronger overall performance.
TGDPO: Harnessing Token-Level Reward Guidance for Enhancing Direct Preference Optimization
Jun 17, 2025Recent advancements in reinforcement learning from human feedback have shown that utilizing fine-grained token-level reward models can substantially enhance the performance of Proximal Policy Optimization (PPO) in aligning large language models. However, it is challenging to leverage such token-level reward as guidance for Direct Preference Optimization (DPO), since DPO is formulated as a sequence-level bandit problem. To address this challenge, this work decomposes the sequence-level PPO into a sequence of token-level proximal policy optimization problems and then frames the problem of token-level PPO with token-level reward guidance, from which closed-form optimal token-level policy and the corresponding token-level reward can be derived. Using the obtained reward and Bradley-Terry model, this work establishes a framework of computable loss functions with token-level reward guidance for DPO, and proposes a practical reward guidance based on the induced DPO reward. This formulation enables different tokens to exhibit varying degrees of deviation from reference policy based on their respective rewards. Experiment results demonstrate that our method achieves substantial performance improvements over DPO, with win rate gains of up to 7.5 points on MT-Bench, 6.2 points on AlpacaEval 2, and 4.3 points on Arena-Hard. Code is available at https://github.com/dvlab-research/TGDPO.
Modular Customization of Diffusion Models via Blockwise-Parameterized Low-Rank Adaptation
Mar 11, 2025Recent diffusion model customization has shown impressive results in incorporating subject or style concepts with a handful of images. However, the modular composition of multiple concepts into a customized model, aimed to efficiently merge decentralized-trained concepts without influencing their identities, remains unresolved. Modular customization is essential for applications like concept stylization and multi-concept customization using concepts trained by different users. Existing post-training methods are only confined to a fixed set of concepts, and any different combinations require a new round of retraining. In contrast, instant merging methods often cause identity loss and interference of individual merged concepts and are usually limited to a small number of concepts. To address these issues, we propose BlockLoRA, an instant merging method designed to efficiently combine multiple concepts while accurately preserving individual concepts' identity. With a careful analysis of the underlying reason for interference, we develop the Randomized Output Erasure technique to minimize the interference of different customized models. Additionally, Blockwise LoRA Parameterization is proposed to reduce the identity loss during instant model merging. Extensive experiments validate the effectiveness of BlockLoRA, which can instantly merge 15 concepts of people, subjects, scenes, and styles with high fidelity.
Effective LLM Knowledge Learning via Model Generalization
Mar 05, 2025Large language models (LLMs) are trained on enormous documents that contain extensive world knowledge. However, it is still not well-understood how knowledge is acquired via autoregressive pre-training. This lack of understanding greatly hinders effective knowledge learning, especially for continued pretraining on up-to-date information, as this evolving information often lacks diverse repetitions like foundational knowledge. In this paper, we focus on understanding and improving LLM knowledge learning. We found and verified that knowledge learning for LLMs can be deemed as an implicit supervised task hidden in the autoregressive pre-training objective. Our findings suggest that knowledge learning for LLMs would benefit from methods designed to improve generalization ability for supervised tasks. Based on our analysis, we propose the formatting-based data augmentation to grow in-distribution samples, which does not present the risk of altering the facts embedded in documents as text paraphrasing. We also introduce sharpness-aware minimization as an effective optimization algorithm to better improve generalization. Moreover, our analysis and method can be readily extended to instruction tuning. Extensive experiment results validate our findings and demonstrate our methods' effectiveness in both continued pre-training and instruction tuning. This paper offers new perspectives and insights to interpret and design effective strategies for LLM knowledge learning.
LogoSticker: Inserting Logos into Diffusion Models for Customized Generation
Jul 18, 2024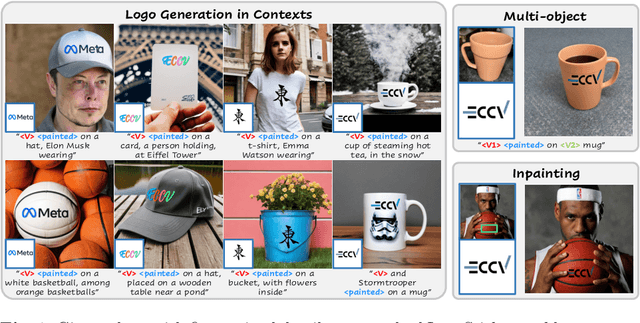
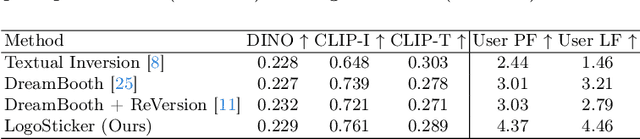
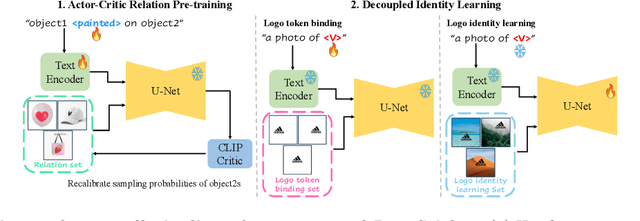

Recent advances in text-to-image model customization have underscored the importance of integrating new concepts with a few examples. Yet, these progresses are largely confined to widely recognized subjects, which can be learned with relative ease through models' adequate shared prior knowledge. In contrast, logos, characterized by unique patterns and textual elements, are hard to establish shared knowledge within diffusion models, thus presenting a unique challenge. To bridge this gap, we introduce the task of logo insertion. Our goal is to insert logo identities into diffusion models and enable their seamless synthesis in varied contexts. We present a novel two-phase pipeline LogoSticker to tackle this task. First, we propose the actor-critic relation pre-training algorithm, which addresses the nontrivial gaps in models' understanding of the potential spatial positioning of logos and interactions with other objects. Second, we propose a decoupled identity learning algorithm, which enables precise localization and identity extraction of logos. LogoSticker can generate logos accurately and harmoniously in diverse contexts. We comprehensively validate the effectiveness of LogoSticker over customization methods and large models such as DALLE~3. \href{https://mingkangz.github.io/logosticker}{Project page}.
Learning to Generalize Provably in Learning to Optimize
Feb 22, 2023Learning to optimize (L2O) has gained increasing popularity, which automates the design of optimizers by data-driven approaches. However, current L2O methods often suffer from poor generalization performance in at least two folds: (i) applying the L2O-learned optimizer to unseen optimizees, in terms of lowering their loss function values (optimizer generalization, or ``generalizable learning of optimizers"); and (ii) the test performance of an optimizee (itself as a machine learning model), trained by the optimizer, in terms of the accuracy over unseen data (optimizee generalization, or ``learning to generalize"). While the optimizer generalization has been recently studied, the optimizee generalization (or learning to generalize) has not been rigorously studied in the L2O context, which is the aim of this paper. We first theoretically establish an implicit connection between the local entropy and the Hessian, and hence unify their roles in the handcrafted design of generalizable optimizers as equivalent metrics of the landscape flatness of loss functions. We then propose to incorporate these two metrics as flatness-aware regularizers into the L2O framework in order to meta-train optimizers to learn to generalize, and theoretically show that such generalization ability can be learned during the L2O meta-training process and then transformed to the optimizee loss function. Extensive experiments consistently validate the effectiveness of our proposals with substantially improved generalization on multiple sophisticated L2O models and diverse optimizees. Our code is available at: https://github.com/VITA-Group/Open-L2O/tree/main/Model_Free_L2O/L2O-Entropy.
Sparse and Imperceptible Adversarial Attack via a Homotopy Algorithm
Jun 10, 2021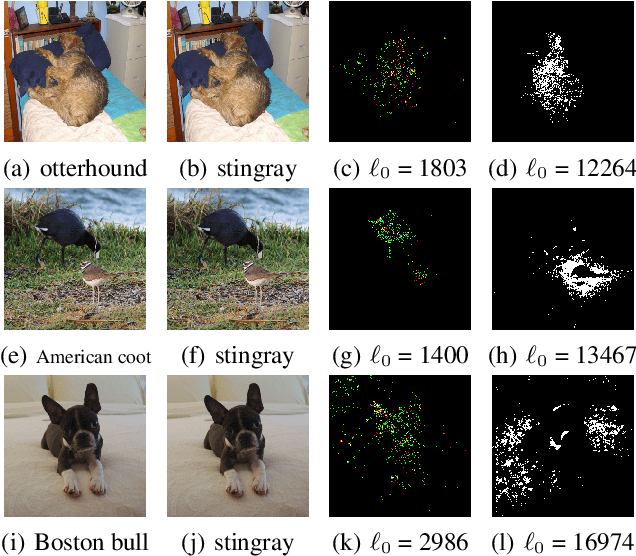
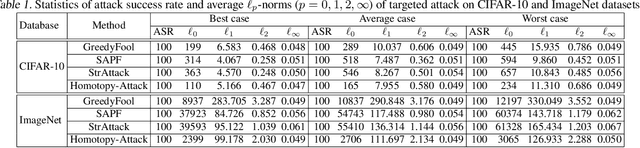
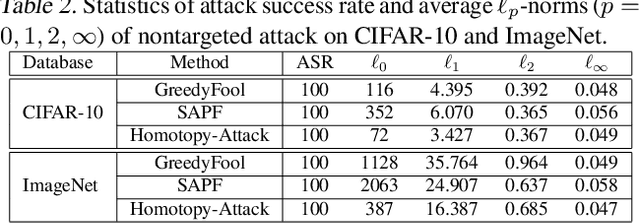

Sparse adversarial attacks can fool deep neural networks (DNNs) by only perturbing a few pixels (regularized by l_0 norm). Recent efforts combine it with another l_infty imperceptible on the perturbation magnitudes. The resultant sparse and imperceptible attacks are practically relevant, and indicate an even higher vulnerability of DNNs that we usually imagined. However, such attacks are more challenging to generate due to the optimization difficulty by coupling the l_0 regularizer and box constraints with a non-convex objective. In this paper, we address this challenge by proposing a homotopy algorithm, to jointly tackle the sparsity and the perturbation bound in one unified framework. Each iteration, the main step of our algorithm is to optimize an l_0-regularized adversarial loss, by leveraging the nonmonotone Accelerated Proximal Gradient Method (nmAPG) for nonconvex programming; it is followed by an l_0 change control step, and an optional post-attack step designed to escape bad local minima. We also extend the algorithm to handling the structural sparsity regularizer. We extensively examine the effectiveness of our proposed homotopy attack for both targeted and non-targeted attack scenarios, on CIFAR-10 and ImageNet datasets. Compared to state-of-the-art methods, our homotopy attack leads to significantly fewer perturbations, e.g., reducing 42.91% on CIFAR-10 and 75.03% on ImageNet (average case, targeted attack), at similar maximal perturbation magnitudes, when still achieving 100% attack success rates. Our codes are available at: https://github.com/VITA-Group/SparseADV_Homotopy.
Learning Transferable 3D Adversarial Cloaks for Deep Trained Detectors
Apr 22, 2021
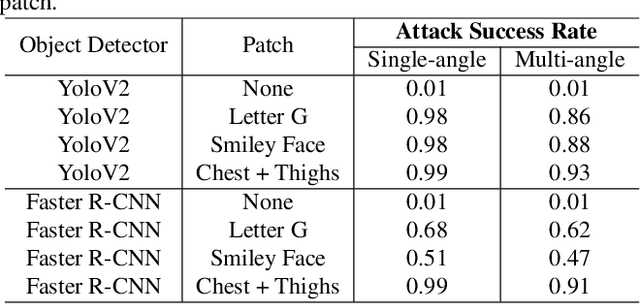
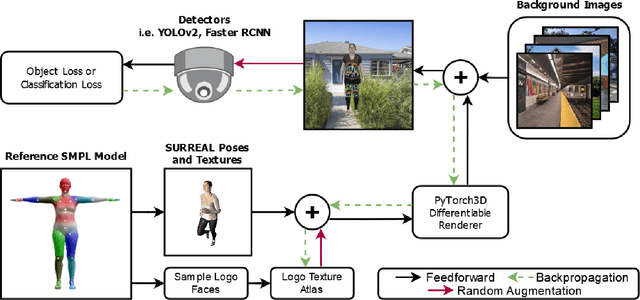
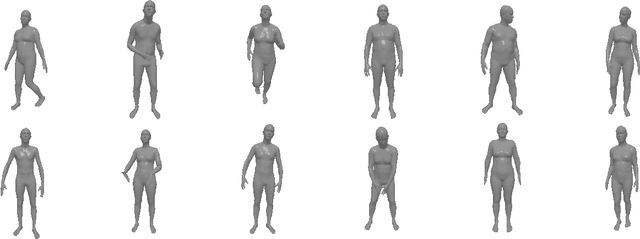
This paper presents a novel patch-based adversarial attack pipeline that trains adversarial patches on 3D human meshes. We sample triangular faces on a reference human mesh, and create an adversarial texture atlas over those faces. The adversarial texture is transferred to human meshes in various poses, which are rendered onto a collection of real-world background images. Contrary to the traditional patch-based adversarial attacks, where prior work attempts to fool trained object detectors using appended adversarial patches, this new form of attack is mapped into the 3D object world and back-propagated to the texture atlas through differentiable rendering. As such, the adversarial patch is trained under deformation consistent with real-world materials. In addition, and unlike existing adversarial patches, our new 3D adversarial patch is shown to fool state-of-the-art deep object detectors robustly under varying views, potentially leading to an attacking scheme that is persistently strong in the physical world.